Asakusa FrameworkのOperator DSLについて。
|
|
Asakusa Frameworkでは、Flow DSLで演算子(オペレーター)を並べることで処理全体を表現する。
演算子は個別の処理内容を表す。通常のJavaの“メソッド”に相当する。
つまり、「演算子を作る」のは「メソッドを用意する」ということであり、Flow DSLでメソッドの呼び出し順を指定していることになる。
通常のJavaプログラミングでも、フレームワークの用意したインターフェースや抽象クラスを継承したり実装したりするが、AsakusaFWの演算子も似たような感じ。
演算子には実装方法に応じてユーザー演算子とコア演算子がある。
コア演算子はプログラマーが中身を実装する必要が無いので、Flow DSLで書く為のメソッドをAsakusaFWが直接提供している。
ユーザー演算子はプログラマーがメソッド名を決めたり中身を実装したりする必要がある。
ユーザー演算子には種類(目的)に応じてアノテーションが提供されており、そのアノテーションを付けてメソッドを実装する。
演算子の種類が色々あるのは、処理の役割をはっきりさせる為。
また、それによってAsakusaFWが最適化をしやすくなる。
従来の感覚からすると1つの演算子の中に色々コーディングしてしまいたくなるが、そうするとAsakusaFWによって最適化されなくなるので、基本的には複数の演算子に分けた方が良い。
(これは、関数型プログラミングでコレクションを操作する際にmapやfilterをつなぎ合わせてコーディングするのと非常に近い)
たくさん演算子を書くと無駄に処理が多くなっているような気になってしまうが、Hadoop上で実行される際にはMapReduceジョブが少なくなるように複数の演算子をまとめる最適化が行われる。(Asakusa on Sparkでも同様[2016-02-11])
そういった分散処理を意識した最適化をAsakusaFWが行ってくれるので、プログラマーは分散処理をあまり意識しなくて済む。
ただ、やはり全く意識しなくてよいというわけではなくて、非効率な演算子を多用すると実行速度が出ないこともある。
(非常に大雑把に言えば、同じ処理が出来るなら、性能特性がCoGroup・Join・Fold(旧ドキュメントではReduce)の演算子よりもExtract(旧ドキュメントではMap)の演算子を使う方が良い[/2016-02-11])
→Toad Editor(図をGUIで描いてOperator DSLの雛形(サンプル)を生成できるツール)
演算子は入力データに対して何らかの処理を行って結果のデータを出力する。
データは、同一レイアウトで複数レコードが集まっているもの。
ファイルで例えればCSVファイル、RDBで例えればテーブル、Javaで例えればList。
レコードのレイアウトはデータモデルで定義する(DMDL(データモデル定義言語)で記述する)。
演算子の中身はJavaでプログラミングするので、実際のところはデータモデルのリスト(List<DataModel>)と思うのが良い。
ただし、演算子のメソッドの引数としてListが来ると決まっているわけではない。
1レコードの入力に対して1レコードしか出力しないと分かっている演算子のメソッドでは、レコード(データモデル)が引数となる。
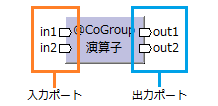
演算子へのデータの入口を入力ポート、演算子からのデータの出口を出力ポートと呼ぶ。
ポートの個数は演算子の種類によって異なる。
演算子の出力データを別の演算子の入力データとして使用する。
これを、出力ポートと入力ポートを(演算子同士を)接続するとか結線すると言う。
AsakusaFWの演算子の一覧。
| 分類 | 演算子 | 入出力 | 説明 | 他言語との類似 | |||||
|---|---|---|---|---|---|---|---|---|---|
| 入力型 | イメージ | 出力型 | SQL | Java | Scala | ||||
| フロー制御演算子 | 分岐演算子 | @Branch | 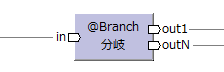 |
inと同じモデル | データの内容に応じて出力先を振り分ける。 出力ポート数は任意。 |
WHERE (CASE WHEN) |
switch if |
match | |
| 合流演算子 | confluent | 全て同じモデル |  |
inと同じモデル | 複数の入力(全て同じデータモデル)をまとめて単一の出力にする。 | UNION | ++ | ||
| 複製演算子 |  |
どの演算子の出力でも複数の演算子の入力に出来るので、 複製演算子には特別な演算子は無い。 |
(clone) | ||||||
| データ操作演算子 | 更新演算子 | @Update | 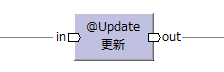 |
inと同じモデル | 入力データの一部を変更して出力する。 データモデルの種類は変わらない。 |
SELECT-INSERT (UPDATE) |
(map) (foreach) |
||
| 変換演算子 [/2018-08-26] |
@Convert | 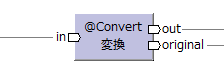 |
変換後のモデル | データモデルを別のデータモデルに変換する。 各データの移送はコーディングする必要がある。 |
SELECT-INSERT | map | |||
| inと同じモデル | |||||||||
| 拡張演算子 [/2015-04-23] |
extend |  |
inよりプロパティーが多いモデル | データモデルを別のデータモデルに変換する。 同一プロパティー名のデータはそのまま移送される。 プロパティーを増やすのに使う。 |
SELECT-INSERT | map | |||
| 射影演算子 [/2015-04-23] |
project |  |
inよりプロパティーが少ないモデル | データモデルを別のデータモデルに変換する。 同一プロパティー名のデータはそのまま移送される。 プロパティーを減らすのに使う。 |
SELECT-INSERT | map | |||
| 再構築演算子 [/2015-04-23] |
restructure |  |
データモデルを別のデータモデルに変換する。 同一プロパティー名のデータはそのまま移送される。 プロパティーを増減するのに使う。 |
SELECT-INSERT | map | ||||
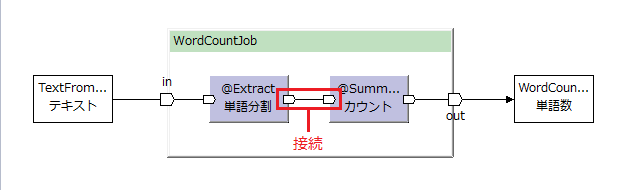
| 抽出演算子 [/2014-12-21] |
@Extract | 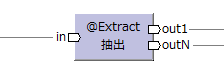 |
入力データを元に複数種類のデータを生成する。 出力ポート数および出力レコード数は任意。 |
flatMap | |||||
| 結合演算子 | マスター確認演算子 [/2015-10-10] |
@MasterCheck | 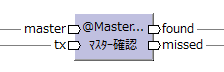 |
txと同じモデル | キーが一致するマスターが存在するかどうかで出力を振り分ける。 | JOIN | |||
| txと同じモデル | |||||||||
| マスター結合演算子 | @MasterJoin |  |
結合モデル | マスターと結合したデータモデルを出力する。 | JOIN | ||||
| txと同じモデル | |||||||||
| マスター分岐演算子 [/2015-03-22] |
@MasterBranch |  |
全てtxと同じモデル | キーが一致するマスターを取得し、 その内容に応じて出力先を振り分ける。 |
JOIN + WHERE | ||||
| マスターつき更新演算子 [/2015-03-22] |
@MasterJoinUpdate |  |
txと同じモデル | キーが一致するマスターを取得し、 その内容を元にデータの一部を変更して出力する。 |
JOIN + INSERT | ||||
| txと同じモデル | |||||||||
| グループ結合演算子 [/2017-04-30] |
@CoGroup |  |
複数の入力データをキーでグループ化し、複数種類のデータを出力する。 入力ポート数・出力ポート数も出力レコード数も任意。 |
(JOIN) | |||||
| 分割演算子 | @Split | 結合モデル | 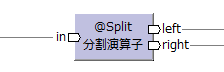 |
inの元となったモデル | 結合モデルを、結合前のデータモデルに分解して出力する。 | unzip | |||
| inの元となったモデル | |||||||||
| 集計演算子 | 単純集計演算子 [/2013-12-30] |
@Summarize |
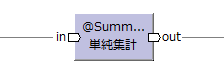 |
集計モデル | キーでグループ化してデータの集計を行う。 | SUM, COUNT, MIN, MAX GROUP BY |
sum,
size,
min,
max groupBy |
||
| 畳み込み演算子 [/2015-07-04] |
@Fold | 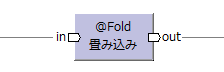 |
inと同じモデル | キーでグループ化して単一レコードへの畳み込みを行う。 | reduce | ||||
| グループ整列演算子 [/2017-04-30] |
@GroupSort | 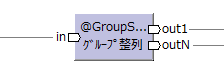 |
キーでグループ化し、さらに入力データがソートされる。 それを元にデータを加工して出力する。 出力ポート数および出力レコード数は任意。 |
ORDER BY | sort | sortBy | |||
| 特殊演算子 | フロー演算子 | FlowPart |  |
Flow DSLで定義したフロー部品を演算子として利用する。 | サブクエリー | メソッド | 関数 | ||
| チェックポイント演算子 | checkpoint |  |
inと同じモデル | 処理の途中結果を保存する。 普通は使わない。 |
|||||
| ロギング演算子 [/2019-06-14] |
@Logging |  |
inと同じモデル | データをログ出力する。 | |||||
| 空演算子 [/2015-04-23] |
empty | 空データ(0件データ)を生成する。 | emptyList | List.empty Nil |
|||||
| 停止演算子 | stop |  |
出力データを利用しない場合は停止演算子に接続する。 | ||||||
AsakusaFWの演算子は20個ちょっとあるので、どれを使えばいいのか選ぶのが悩ましい。
まずは、自分が行いたい処理が集計なのか結合なのかそれ以外なのかを考える。この三択なら迷わないだろう(笑)
大きくどの分類を使うかだけ判断できれば、その中で使える演算子の種類は絞られてくる。
ちなみに、cocoatomoさんの演算子選択のための流れ図のチャートの方がきれいで分かり易い(笑)[2013-12-23]
なお、cocoatomoさんのチャートで「入力の数」「出力の数」と言っているのは入力ポート/出力ポート数、「インスタンスの個数」と言っているのはレコード数のこと。
また、teppei_tosaさんの演算子のチートシートも実装例が載っており、分かり易い。[2015-03-15]
結合処理であれば、一番基本的なのがマスター結合演算子(@MasterJoin)。
SQLのINNER JOINに相当する。
ただし、結合した後の利用目的によっては、他の結合系演算子の方が実行効率が良いかもしれない。
マスターと突き合わせてマスターデータが存在するかどうかを確認するだけなら、マスター確認演算子(@MasterCheck)を使う。
マスターデータの値によって処理を振り分けたいが、その後マスターデータ自体は使用しない、という場合はマスター分岐演算子(@MasterBranch)を使う。
同様に、マスターデータの値を使ってデータを更新したいが、その後マスターデータ自体は使用しない、という場合はマスターつき更新演算子(@MasterJoinUpdate)を使う。
なお、1つのデータに複数種類のマスターを結合させる演算子は無いので、その場合は結合系演算子を複数使用する。
フロー部品化すれば、Flow DSL上は1つの演算子のように見せることも出来る。
集計処理であれば、基本的に単純集計演算子(@Summarize)を使うことを考える。
集計可能なレイアウト(データモデル)にする為に、集計の前にデータ加工系の演算子を使っておく。
関数型言語に慣れている人なら畳み込み演算子(@Fold)もいいだろう。
これは集計前と集計後で同一のデータモデルである必要がある。
(逆に言えば、単純集計演算子の出力は集計モデルになるので、同一データモデルのままにしたい場合は畳み込み演算子を使う。[2013-12-01])
集計ではなく、キーでグループ化した一塊(一連の複数レコード)に対して処理を行いたい場合はグループ整列演算子(@GroupSort)を使う。
(先頭10レコードだけ抽出したいとか、抜けているレコードを補填したいとか、複数レコードから1レコードを生成したい(いわゆる縦持ちを横持ちに変換する)とか。[/2013-11-26])
さらに入力データが複数あり、結合して同様の処理を行いたい場合はグループ結合演算子(@CoGroup)を使う。
ただしCoGroupは最適化が行われない筆頭の演算子なので、なるべく使わないようにしたい。処理を分割して他の演算子の組み合わせになるようにすべき。
(極端なことを言えば、CoGroupだけあれば全てその中に書けてしまうので)
いわゆる縦持ち・横持ちとは、以下のようなレコード・データの持ち方を指す。[2013-11-26]
| 縦持ち | 横持ち | ||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
→ |
|
縦持ちを横持ちに変換するにはグループ整列演算子(@GroupSort)を使う。→実装例 (ただし、AsakusaFWは項目数(プロパティー数)が可変のデータモデルを定義することは出来ない。 項目の最大数を決めて頑張って定義するしかないと思われる) |
||||||||||||||||||||||||
| ← | 横持ちを縦持ちに変換するには抽出演算子(@Extract)を使う。→実装例 |
データの内容に応じて大きく処理を分けたい場合は分岐演算子(@Branch)を使う。
(例えば、区分=99のときだけ特別な処理を行うとか)
なお、結合したマスターデータの内容に応じて処理を分けたい場合はマスター分岐演算子(@MasterBranch)を使う。
レコード(データモデル)の内容を書き換える処理なら、更新演算子(@Update)が基本。
これは、レコード内の項目を使って演算し、別の項目に値をセットするもの。
したがって、入力のデータモデルと出力のデータモデルが同一となる。
1レコードの入力に対して1レコード出力する。
データモデルを別のデータモデルに変換しつつ演算を行うには、変換演算子(@Convert)を使う。
1レコードの入力に対して1レコード出力する。
出力データモデルの各項目への値のセットをコーディングするので、どんな演算でも書ける。(逆に言うと、全ての出力項目に対してコーディングしなければならない)
普通のJavaプログラミングで一番よく書かれている処理に近いと思う。
演算せずにデータモデルを別のデータモデルに変換するだけなら、再構築演算子(restructure)が使える。
これは、データモデル間で同一プロパティー名であれば、そのまま値を移送してくれる。
出力先データモデルのプロパティーが入力元データモデルから増える場合にも減る場合にも対応している。
ただし、プロパティーが増えるのみなら、拡張演算子(extend)を使った方が良さそう。プロパティーが減るのみなら、射影演算子(project)。
※これらの演算子のデータ移送はgetter/setterを使っての移送となる(そういうコードが生成される)らしい。つまりリフレクションを使って移送しているわけではないので、実行効率は特に悪くは無いはず。[2013-11-05]
1レコードの入力に対して複数レコード出力したい(あるいはレコードを出力しないこともある)場合は、抽出演算子(@Extract)を使う。
1つのデータモデルを異なるデータモデル(複数種類のデータモデル)に変換して出力したい場合も抽出演算子(@Extract)を使う。
複数レコードにまたがって(集計以外の)データ加工を行いたい場合はグループ処理を参照。
変換演算子(@Convert)は、再構築演算子(restructure)+更新演算子(@Update)で代用することも出来る。
単なる項目移送が多いなら後者の方がコーディング量が少ないと思う。
データモデルのプロパティーを増減させる目的なら、restructure・extend・projectの使用が推奨されている。[2013-11-05]
Operatorクラスのメソッドは、マルチスレッドセーフ(MTセーフ)になるようにコーディングするべき。[2015-06-21]
つまり、定数とShared以外のstaticフィールドは基本的に使用しないようにコーディングする必要がある。
実行基盤がHadoopの場合、各タスクが(マルチスレッドではなく)マルチプロセスで動くので、MTセーフでなくても動作はする。
が、Hadoop以外の実行基盤、例えばSparkではマルチスレッドで動く。[/2015-07-08]
Asakusaアプリケーションのリコンパイルのみで実行基盤を切り替えられるようになっている方が便利なので、基本的にMTセーフになるようコーディングしておくべき。
| 駄目な例(SimpleDateFormatはMTセーフでない) | MTセーフな例 |
|---|---|
public abstract ExampleOperator { |
public abstract ExampleOperator { |
|
(SimpleDateFormatをstaticに保持するから駄目なので、単純にstaticをやめるという方法もある。[2016-05-30] (Operatorインスタンスは演算子メソッド毎に別々に作られる為)) public abstract ExampleOperator { |
なお、Operatorクラスに関する“プログラマーのコーディング以外の部分”では、基本的にMTセーフになっている。
実行時のOperatorインスタンス自体も、演算子メソッド毎に別々に生成される。
したがって、インスタンスフィールド(staticでないフィールド)は共有されず、複数スレッドから同時にアクセスされることも無い。
(逆に、複数の演算子間でフィールドを共有して(値の受け渡しとかに)使うことは出来ない)
StringOption等のOption系クラスは読み取るだけならMTセーフなので、staticフィールドに定数として保持する使い方は問題ない。