ポート数
の制約
ポート数
の制約
に対する
出力レコード数
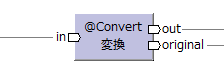
データモデル
Asakusa FrameworkのOperator DSLの変換演算子(@Convert)のメモ。
|
変換演算子は、入力データを別のデータモデルに変換する演算子。
性能特性はExtract(旧ドキュメントではMap)。[/2016-02-11]
| 入力 ポート数 |
入力データモデル の制約 |
イメージ | 出力 ポート数 |
出力データモデル の制約 |
入力1レコード に対する 出力レコード数 |
|
|---|---|---|---|---|---|---|
| 1 |
|
2 | out | 1レコード。 | ||
| original | inと同じ データモデル |
1レコード。 | ||||
変換したデータはoutから出力される。
同時に、変換前のデータそのものがoriginalから出力される。
というか、Convert演算子の中で元のデータを変更してもよく、それがoriginalから出力される。[/2018-08-26]
originalを使わない場合は停止演算子(stop)に接続する。
※AsakusaFW 0.10.1から、originalを使わない場合はstop演算子に渡さなくてもよくなった。[2018-08-26]
変換演算子は、データモデルの種類を変更するのに使う。
ただし、データモデルのプロパティーを増減させる目的なら、再構築演算子(restructure)を使う。
複数種類のデータモデルを出力したいなら抽出演算子(@Extract)を使う。
別のデータ種類に変換するのではなく内容(値)を変えたいだけなら、更新演算子(@Update)を使う。
複数レコードの集計をしたい場合は単純集計演算子(@Summarize)を使う。
(集計以外で)他のレコードを参照したい場合はグループ整列演算子(@GroupSort)を使う。
hogeというデータモデルをfooデータモデルに変換する例。
(この図はToad Editorを用いて作っています)
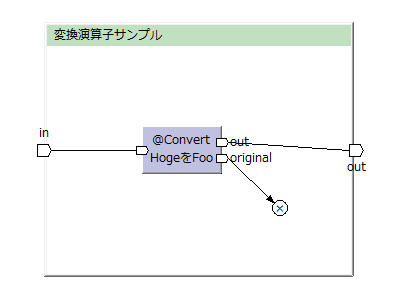
※Toad Editorでは、停止演算子(stop)を丸の中に×(バツ印)の入った図形で表している。
(AsakusaFW 0.10.1から、originalを使わない場合はどこにも結線する(stop演算子に渡す)必要が無くなった。[2018-08-26])
| 入力データ例 | 出力データ例 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| in |
|
→ | out |
|
||||||||
| → | original |
|
||||||||||
hoge = {
value : INT;
};
foo = {
value : INT;
};
import com.asakusafw.vocabulary.operator.Convert; import com.example.modelgen.dmdl.model.Foo; import com.example.modelgen.dmdl.model.Hoge;
public abstract class ExampleOperator {
private final Foo foo = new Foo();
/**
* HogeをFooに変換する
*
* @param hoge
* 変換するレコード
* @return 変換後のレコード
*/
@Convert
public Foo toFoo(Hoge hoge) {
foo.reset(); // 初期化
foo.setValue(hoge.getValue() / 1000);
return foo;
}
}
引数に入力のデータモデルを指定する。
戻り値には変換後のデータモデルを指定する。
Operatorクラスに定義したメソッドはスレッドセーフになる(別スレッドから同時に呼ばれることは無い)ので、フィールドにオブジェクトを定義して使い回してもよい。
(ただし、以前のレコードの値の保持には使えない。実行時には各マシンに分散して処理されるので、レコードの入力順も どのレコードが来るのかも保証されない為)
なお、返したオブジェクトは次に使うときは内容が破壊されている(可能性がある)ので、毎回初期化する必要がある。[2014-12-21]
(Resultにaddしたオブジェクトが破壊される可能性があるのと同じ理由)
import com.example.modelgen.dmdl.model.Hoge; import com.example.operator.ExampleOperatorFactory; import com.example.operator.ExampleOperatorFactory.ToFoo;
private final In<Hoge> in; private final Out<Foo> out;
@Override
public void describe() {
ExampleOperatorFactory operators = new ExampleOperatorFactory();
CoreOperatorFactory core = new CoreOperatorFactory();
// HogeをFooに変換する
ToFoo toFoo = operators.toFoo(this.in);
core.stop(toFoo.original); // オリジナルは使わないので停止演算子へ接続
this.out.add(toFoo.out);
}
Flow DSLでは、自分が作ったOperatorのFactoryクラス(AsakusaFWのコンパイラーによって生成される)を使用する。
メソッド名はOperatorクラスに書いたメソッド名と同じ。
戻り値の型はAsakusaFWのコンパイラーによって生成されたクラス。(メソッド名を先頭が大文字のキャメルケースに変換したもの)
出力ポートの名前のデフォルトはoutとoriginal。
出力ポート名を変えたい場合は@Convertアノテーションで指定できる。
@Convert(originalPort = "original", convertedPort = "out")
AsakusaFW 0.10.1から、originalは結線しなくても(stop演算子に渡さなくても)よくなった。[2018-08-26]
実際、originalはstop以外に渡した事は一度も無いし^^;
変換演算子の単体テストの実装例。
package com.example.operator;
import static org.hamcrest.CoreMatchers.is; import static org.junit.Assert.assertThat; import org.junit.Test; import com.example.modelgen.dmdl.model.Hoge;
/**
* {@link ExampleOperator}のテスト.
*/
public class ExampleOperatorTest {
@Test
public void toFoo() {
ExampleOperator operator = new ExampleOperatorImpl();
Hoge hoge = new Hoge();
hoge.setValue(123);
Foo foo = operator.toFoo(hoge);
assertThat(foo.getValue(), is(123));
}
}
Operatorのテストクラスは、通常のJavaのJUnitのテストケースクラスとして作成する。
テスト対象のOperatorクラス自身は抽象クラスだが、Operatorクラス名の末尾に「Impl」の付いた具象クラスがAsakusaFWによって生成されるので、それを使う。
変換演算子では、変更元のデータモデルの他にも引数を指定することが出来る。
こうすると、引数の内容分だけ異なる同じ演算子(処理内容)をいくつかの場所で使用できるようになる。
Hoge2というデータモデルをErrorRecordデータモデルに変換し、「message」項目に引数で指定したメッセージを設定する例。
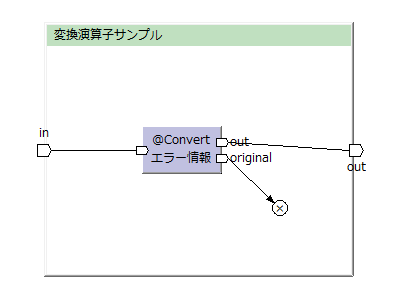
hoge2 = {
"コード"
code : TEXT;
};
error_record = {
"コード"
code : TEXT;
"メッセージ"
message : TEXT;
};
import com.asakusafw.vocabulary.operator.Convert; import com.example.modelgen.dmdl.model.ErrorRecord; import com.example.modelgen.dmdl.model.Hoge2;
public abstract class ExampleOperator {
/**
* エラー情報に変換する
*
* @param hoge
* 変換するレコード
* @param message
* メッセージ
* @return エラー情報レコード
*/
@Convert
public ErrorRecord toErrorRecord(Hoge2 hoge, String message) {
ErrorRecord record = new ErrorRecord();
record.setCode(hoge.getCode());
record.setMessageAsString(message);
return record;
}
}
第1引数は通常の変換演算子と同じく変更元のデータモデル。
第2引数以降を通常のJavaメソッドと同様に自由な引数とすることが出来る。(ただしプリミティブのみ)
import com.asakusafw.vocabulary.flow.util.CoreOperatorFactory; import com.example.modelgen.dmdl.model.ErrorRecord; import com.example.modelgen.dmdl.model.Hoge2; import com.example.operator.ExampleOperatorFactory; import com.example.operator.ExampleOperatorFactory.ToErrorRecord;
@Override
public void describe() {
ExampleOperatorFactory operators = new ExampleOperatorFactory();
CoreOperatorFactory core = new CoreOperatorFactory();
// エラー情報に変換する
ToErrorRecord toErrorRecord = operators.toErrorRecord(this.in, "Hoge2エラー");
core.stop(toErrorRecord.original); // オリジナルは使わないので停止演算子へ接続
this.out.add(toErrorRecord.out);
}
演算子を使用するFlow DSLで、引数に具体的な値を指定する。
@Test
public void toErrorRecord() {
ExampleOperator operator = new ExampleOperatorImpl();
Hoge2 hoge = new Hoge2();
hoge.setCodeAsString("abc");
String message = "Hoge2エラー";
ErrorRecord record = operator.toErrorRecord(hoge, message);
assertThat(record.getCodeAsString(), is("abc"));
assertThat(record.getMessageAsString(), is(message));
}
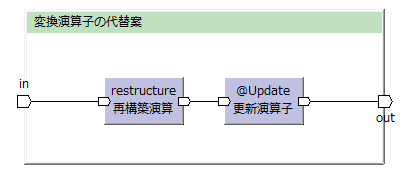
同名のプロパティーを移送する処理が多いなら、こちらの方がいいかもしれない。
(変換演算子は移送を全てプログラマーが実装する必要があるが、再構築演算子では移送処理を自動生成してくれるので)
または、変換後のデータモデルが変換元のデータモデルと関係が薄いとき(プロパティー名が一致している程度のとき)は再構築演算子の方が良いかもしれない。(汎用のエラーテーブルへ変換するとか)
変換演算子ではデータ移送を全てコーディングしなければならないので、色々な種類のデータモデルを入力にするのは難しい。
再構築演算子はその辺りがやりやすい。
変換演算子は、SQLのSELECT-INSERTに似ている。
INSERT out (code, message) SELECT code, 'メッセージ' FROM in;
case class Hoge(value: Int) case class Foo(value: Int) def toFoo(hoge: Hoge) = Foo(hoge.value) val in : List[Hoge] = 〜 val out: List[Foo] = in.map(toFoo)