ポート数
の制約
ポート数
の制約
に対する
出力レコード数
データモデル
1レコード。
Asakusa FrameworkのOperator DSLの畳み込み演算子(@Fold)のメモ。
|
畳み込み演算子は、レコードを集計キー毎に集計する演算子。
性能特性はFold(旧ドキュメントではReduce)。[/2016-02-11]
| 入力 ポート数 |
入力データモデル の制約 |
イメージ | 出力 ポート数 |
出力データモデル の制約 |
入力1レコード に対する 出力レコード数 |
|---|---|---|---|---|---|
| 1 |
|
1 | inと同じ データモデル |
集計キー毎に 1レコード。 |
畳み込み演算子では、入力データが集計キー毎に2レコード以上ある場合、1つ目のレコードに2つ目以降のレコードの値を集計していく(畳み込んでいく)。
その集計方法をOperatorクラスのメソッドに実装する。
ただし、集計キーでグルーピングしたグループ内に1レコードしか無い場合は、実装したメソッドは呼ばれず、そのレコードそのものが出力される。
(つまり、例えばある項目を初期化するような演算を行って出力するようなコーディングをすると、1レコードしか無い場合にその演算(項目の初期化)が行われない)
基本的には、集計には単純集計演算子(@Summarize)を使う。
最悪の場合はグループ整列演算子(@GroupSort)で集計を行う。
畳み込み演算子を他の演算子と比較してみると。[2015-07-04]
単純集計演算子(@Summarize)と比べると、集計結果のデータモデルを作る必要が無い、入出力でデータモデルの種類が変わらないのが利点。
Foldでは集計内容を自分で実装しなければならないのが欠点。
グループ整列演算子(@GroupSort)と比べると、順序に依存しない(ソートされない)ので分散して処理される(HadoopのCombinerが使われる)のが利点。
順序が必要であればGroupSortを使うしかない。
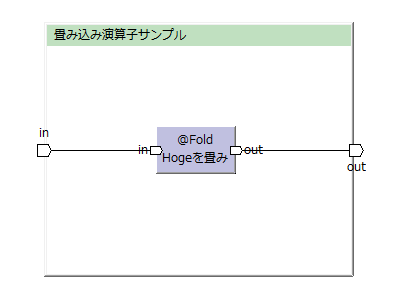
hogeの「value」項目を集計する例。
(この図はToad Editorを用いて作っています)
| 入力データ例 | 出力データ例 | |||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| in |
|
→ | out |
|
||||||||||||||||||||||
hoge = {
id : TEXT;
value : INT;
};
import com.asakusafw.vocabulary.operator.Fold; import com.example.modelgen.dmdl.model.Hoge;
public abstract class ExampleOperator {
/**
* Hogeを畳み込む
*
* @param left
* ここまでの畳み込みの結果
* @param right
* 畳み込む対象
*/
@Fold
public void fold(@Key(group = "id") Hoge left, Hoge right) {
// @Summarizeを手動で行うイメージで、leftに次々とrightを加える
left.setValue(left.getValue() + right.getValue());
}
}
引数で入力となるデータモデルを指定する。
第1引数には@Keyアノテーションを付けて、集計キーを指定する。
複数の項目を集計キーとする場合は「@Key(group = { "key1", "key2" })」のように波括弧でくくってカンマ区切りで指定する。
第2引数の値を、第1引数に集計してセットする。
最終的に第1引数のデータモデルの内容が出力される。
(集計キーでグルーピングしたグループ内に1レコードしか無い場合は、実装したメソッドは呼ばれず、レコードがそのまま出力される)
import com.example.modelgen.dmdl.model.Hoge; import com.example.operator.ExampleOperatorFactory; import com.example.operator.ExampleOperatorFactory.Fold;
private final In<Hoge> in; private final Out<Hoge> out;
@Override
public void describe() {
ExampleOperatorFactory operators = new ExampleOperatorFactory();
// Hogeを畳み込む
Fold f = operators.fold(this.in);
this.out.add(f.out);
}
Flow DSLでは、自分が作ったOperatorのFactoryクラス(AsakusaFWのコンパイラーによって生成される)を使用する。
メソッド名はOperatorクラスに書いたメソッド名と同じ。
戻り値の型はAsakusaFWのコンパイラーによって生成されたクラス。(メソッド名を先頭が大文字のキャメルケースに変換したもの)
出力ポートの名前のデフォルトはout。
出力ポート名を変えたい場合は@Foldアノテーションで指定できる。
@Fold(outputPort = "out")
畳み込み演算子の単体テストの実装例。
package com.example.operator;
import static org.hamcrest.CoreMatchers.is; import static org.junit.Assert.assertThat; import org.junit.Test; import com.example.modelgen.dmdl.model.Hoge;
/**
* {@link ExampleOperator}のテスト.
*/
public class ExampleOperatorTest {
@Test
public void fold() {
ExampleOperator operator = new ExampleOperatorImpl();
Hoge hoge = new Hoge();
hoge.setValue(123);
Hoge hoge2 = new Hoge();
hoge2.setValue(456);
Hoge hoge3 = new Hoge();
hoge3.setValue(789);
operator.fold(hoge, hoge2);
assertThat(hoge.getValue(), is(123 + 456));
operator.fold(hoge, hoge3);
assertThat(hoge.getValue(), is(123 + 456 + 789));
}
}
Operatorのテストクラスは、通常のJavaのJUnitのテストケースクラスとして作成する。
テスト対象のOperatorクラス自身は抽象クラスだが、Operatorクラス名の末尾に「Impl」の付いた具象クラスがAsakusaFWによって生成されるので、それを使う。
畳み込み演算子では、部分集約を行うかどうかを指定できる。
部分集約とは、ストレートに言うとHadoopのCombinerを使うかどうかの指定。
普通は部分集約を行う方が実行効率が良くなる。
@FoldアノテーションでPartialAggregation.PARTIALを指定すると部分集約が有効になる。
特に指定しない場合はDEFAULTが使われる。
import com.asakusafw.vocabulary.flow.processor.PartialAggregation; import com.asakusafw.vocabulary.operator.Fold; import com.example.modelgen.dmdl.model.Hoge; import com.example.modelgen.dmdl.model.HogeTotal;
public abstract class ExampleOperator {
/**
* Hogeを畳み込む
*
* @param left
* ここまでの畳み込みの結果
* @param right
* 畳み込む対象
*/
@Fold(partialAggregation = PartialAggregation.PARTIAL)
public void fold(@Key(group = "id") Hoge left, Hoge right) {
〜
}
}
畳み込み演算子は、Scalaのreduceメソッドに似ている。
case class Hoge(id: String, value: Int)
val list = List(Hoge("a", 1), Hoge("a", 2), Hoge("a", 3))
val out = list.reduce((left, right) => Hoge(left.id, left.value + right.value))
(Scalaにはfoldメソッドもあるのでfoldに似ている…と言いたいところだが、Scalaのfoldは初期データを指定するようになっているので、ちょっと違う)