Asakusa FrameworkのBatch DSLについて。
|
|
Asakusa Frameworkにおける「バッチ」は、例えて言えば、通常のJavaアプリケーション(main()から始まるもの)に相当する。
Batch DSLは、Flow DSLで記述した複数のジョブフローをどのような順番で実行するのかを記述する。
(単純なバッチなら、ジョブが1つしか無いこともある。というか、1ジョブしか無いのが一般的)
→Toad Editor(図をGUIで描いてBatch DSLを生成できるツール)
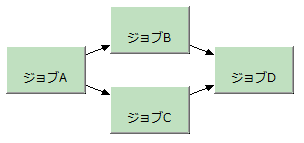
「ジョブAの実行後にジョブB・Cを実行し、B・Cの後にDを動かす」という例を考えてみる。
これは、以下のように記述する。
import com.asakusafw.vocabulary.batch.*;
@Batch(name = "example")
public class ExampleBatch extends BatchDescription {
@Override
public void describe() {
Work jobA = run(JobFlowA.class).soon();
Work jobB = run(JobFlowB.class).after(jobA);
Work jobC = run(JobFlowC.class).after(jobA);
/*Work jobD =*/ run(JobFlowD.class).after(jobB, jobC);
}
}
@BatchアノテーションによってバッチID(バッチ名)を付ける。
バッチを実行する際には、このバッチIDを指定して実行する。(YAESSの引数にバッチIDを指定する)
run()で、実行するジョブフローを指定する。
そして最初に動かすジョブはsoon()、何かのジョブの後に動く場合はafter()で先行ジョブを指定する。
「
run(JobA.class).soon()」という文を見ると、「JobAをすぐ(soon)に実行(run)する」と読める。
「run(JobB.class).after(jobA)」という文を見ると、「JobAの後(after)にJobBを実行(run)する」と読める。
このように文として読めるようになっているのがDSL(ドメイン特化言語)と名乗っている所以だと思う。
(Batch DSLは、Asakusaアプリケーションのバッチ内の処理順序を記述することに特化した言語である)
Batch DSLを記述したメソッドはコンパイル時に解釈されて実行情報に変換される。
実際のバッチ実行時にこのメソッドが直接呼ばれるわけではない。
Batch DSL内でsoonのジョブフローを複数指定すると、それらのジョブフローは並列で同時に実行してよいことになる。[2016-12-10]
が、デフォルトでは、ジョブフローの並列実行数は1になっているので、同時実行はされない(直列に/順番に実行される)。
YAESSのプロファイルでジョブフローの並列実行数を指定できるので、例えば3を指定すると、最大で3ジョブ同時に並列実行されるようになる。
また、この指定を有効にするためには、スケジューラーを並列ジョブスケジューラーにする必要がある。[2016-12-20]
scheduler = com.asakusafw.yaess.paralleljob.ParallelJobScheduler scheduler.parallel.default = 3
YAESSにはバッチの同時実行制御の仕組みがあり、デフォルトでは、複数のバッチを並列で同時に実行することが出来ないようになっている。[2017-06-10]
(並列で同時に実行を開始しても、ひとつずつしか実行されない(直列で実行される))
## file lock
lock = com.asakusafw.yaess.basic.BasicLockProvider
lock.scope = world
lock.directory = ${ASAKUSA_HOME}/yaess/var/lock
YAESSのプロファイルでlock.scopeをexecutionにすると、バッチを並列で実行できるようになる。
(lock.scopeを省略した場合のデフォルトはexecutionらしいのだが、生成されるyaess.propertiesにはworldが指定されているので、直列でしかバッチを実行できない)
→YAESSユーザーガイドのバッチ実行のロック
AsakusaFWの「バッチ」は、アプリケーションの実行単位。
AsakusaFWの「ジョブフロー」は、バッチを構成する処理単位。
AsakusaFWの「バッチ」は、ジョブ管理ツール(JP1やA-AUTO等)で言う“ジョブ”に相当する。
AsakusaFWの「ジョブフロー」は、普通のJavaアプリケーションで例えるとスレッド(や大きめのメソッド)に相当する。
個人的には混乱の元だと思うのだが、ジョブ管理ツールで言う“ジョブ”と、AsakusaFWで言う「ジョブ(ジョブフロー
・データフロー)」は別次元(別階層)のもの。
各プロダクトの用語を階層毎に対比させると、以下の様な感じになると思う。
| 階層 | |||||
|---|---|---|---|---|---|
| システム全体 | 実行単位 | 処理単位 | データ構造 | ||
| ジョブ管理ツール | ジョブネット | ジョブ | |||
| Asakusa Framework | バッチ (Batch DSL) |
ジョブフロー (Flow DSL) |
演算子 (Operator DSL) |
データモデル (DMDL) |
|
| MapReduceジョブ群に変換して実行 | |||||
| Javaアプリケーション | バッチ (main()) |
スレッド (Thread) |
メソッド (サブルーチン) |
JavaBeans (構造体) |
|
| Hadoop(MapReduce) | ジョブ (MapReduce) |
Mapper#map() Reducer#reduce() |
Writable | ||
| PigやHive | スクリプト (Pig LatinやHiveQL) |
MapReduceジョブ群に変換して実行 | |||
AsakusaFWのジョブフローが普通のJavaアプリケーションのスレッドに相当すると思うのは、以下のようなコードがイメージできるから。
| Asakusa DSL | Javaアプリケーションのイメージ | |
|---|---|---|
| Job クラス |
@JobFlow(name = "jobA")
public class JobA extends FlowDescription {
private In<Data1> in;
private Out<Data3> out;
〜
@Override
protected void describe() {
ExampleOperatorFactory op = new ExampleOperatorFactory();
Process1 p1 = op.process1(in);
Source<Data2> s1 = p1.out;
Process2 p2 = op.process2(s2);
Source<Data3> s2 = p2.out;
out.add(s2);
}
}
|
// public class JobA extends Thread { private List<Data1> in; private List<Data3> out; 〜 @Override public void run() { Example op = new Example(); Reuslt1 r1 = op.process1(in); List<Data2> s1 = r1.out; Result2 r2 = op.process2(s1); List<Data3> s2 = r2.out; out.addAll(s2); } } |
| Batch クラス |
@Batch(name = "example")
public class ExampleBatch extends BatchDescription {
@Override
public void describe() {
Work jobA = run(JobA.class).soon();
Work jobB = run(JobB.class).after(jobA);
Work jobC = run(JobC.class).after(jobA);
Work jobD = run(JobD.class).after(jobB, jobC);
}
}
|
//
public class ExampleBatch {
public static void main(String[] args) {
JobA jobA = new JobA(〜); jobA.start();
jobA.join(); //JobAの終了待ち
JobB jobB = new JobB(〜); jobB.start();
JobC jobC = new JobC(〜); jobC.start();
jobB.join(); jobC.join(); //JobB,Cの終了待ち
JobD jobD = new JobD(〜); jobD.start();
jobD.join(); //JobDの終了待ち
}
}
普通だったらこういう場合はJobBかJobCだけを別スレッドにすると思うけど、これは例なので^^; |
つまり、処理の実体はOperatorクラスに書いておき、それらの処理をどのような順序で(どのような引数で)呼び出すのかをJobクラスに記述する。
Batchクラスでは、ジョブ(スレッド)をどの順番で呼び出すかだけを記述する。
ジョブフローとの対比対象は、スレッドでなく、大きめに分割されたメソッドでもよい。
(ジョブはpublicメソッドで、オペレーターはprivate/protectedメソッド。Batchクラスではpublicメソッド呼び出しだけを書く)
| Asakusa DSL | Javaアプリケーションのイメージ | |
|---|---|---|
| Job クラス |
@JobFlow(name = "jobA")
public class JobA extends FlowDescription {
private In<Data1> in;
private Out<Data3> out;
〜
@Override
protected void describe() {
ExampleOperatorFactory op = new ExampleOperatorFactory();
Process1 p1 = op.process1(in);
Source<Data2> s1 = p1.out;
Process2 p2 = op.process2(s2);
Source<Data3> s2 = p2.out;
out.add(s2);
}
}
|
//
public class JobA extends Example {
private List<Data1> in;
private List<Data3> out;
〜
public void run() {
Reuslt1 r1 = super.process1(in);
List<Data2> s1 = r1.out;
Result2 r2 = super.process2(s1);
List<Data3> s2 = r2.out;
out.addAll(s2);
}
}
|
| Batch クラス |
@Batch(name = "example")
public class ExampleBatch extends BatchDescription {
@Override
public void describe() {
Work jobA = run(JobA.class).soon();
Work jobB = run(JobB.class).after(jobA);
Work jobC = run(JobC.class).after(jobA);
Work jobD = run(JobD.class).after(jobB, jobC);
}
}
|
//
public class ExampleBatch {
public static void main(String[] args) {
JobA jobA = new JobA(〜); jobA.run();
JobB jobB = new JobB(〜); jobB.run();
JobC jobC = new JobC(〜); jobC.run();
JobD jobD = new JobD(〜); jobD.run();
}
}
|
が、ジョブフローは場合によっては並行して実行させることが出来る(上記のJobBとJobC)ので、その点ではスレッドが近いと思う。
(もちろん、実際はAsakusaプログラムは複数のHadoopジョブ(MapReduceプログラム)に変換されるので、実態はマルチスレッドというよりはマルチプロセスの方が近い)
処理の粒度(メソッドの大きさ)を考えるのは難しいが、
Asakusa DSLにおいては、「どのファイルを読み込んでどのファイルに書き出すか」がジョブ(ジョブフロー)を区切る単位になる。
“ジョブ”という言葉と複数“ジョブ”の先行関係を表した図(ジョブネット)をイメージすると、Batch
DSLはジョブネットを記述する言語の様に見える。
しかしそれは誤りで、ジョブ管理ツールに登録する“ジョブ”は「バッチ(Asakusaアプリケーション)」であり、AsakusaFWの「ジョブ」ではない。
Asakusaアプリケーションを実行するYAESSでも、基本的にはバッチIDのレベルまでしか指定しない。
(AsakusaFW 0.4では、フローID(ジョブフロー)を指定するオプションも有りはするのだが^^;)
したがって、Asakusaアプリケーションのジョブフローをジョブ管理ツールでジョブネットとして図示するのはレベル(階層)が違うことになる。
通常のJavaアプリケーションでメソッドやクラスの呼び出し関係をジョブネットとして図示しないとの同じ。
素のMapReduceプログラムを書いたなら、複数のHadoopジョブ(MapReduceプログラム)の実行制御としてジョブネットを組むことは自然だと思う。
(HadoopはHadoopアプリケーションを実行するときにジョブと呼ぶ。JobTrackerがHadoopジョブを管理している)
しかしPigやHiveのスクリプトを書いたなら、そこから変換されたHadoopジョブ群をジョブネットに登録しようとは思わないだろう。
(Oozieがどういう位置付けのものなのかはよく分からない^^;)
AsakusaFWもジョブフローをHadoopジョブに変換するので、PigやHiveと同じ。
とは言えPigやHiveと違って事前にコンパイルして実行計画(MapReduceプログラム群と実行順序情報)を作成するので、ジョブネットに変換できそうな気もする。
しかし
Asakusaプログラムをちょっと修正しただけでもコンパイルし直したら別の実行計画になる可能性があり、その都度ジョブネットを変更するかと言えば、その方が大変だと思う。