Asakusa FrameworkのFlow DSLについて。
|
|
Asakusa Frameworkにおける「フロー(データフロー)」は、例えて言えば、通常のJavaアプリケーションのプログラム本体(処理の記述)に相当する。
Flow DSLは、オペレーター(演算子)を「どのようなデータを入力として」「どのような順番で実行するのか」を記述する。
別の言い方をすると、オペレータークラスに定義されたメソッドの呼び出しを記述する。
Flow DSLには、ジョブフロー(JobFlow)とフローパート(FlowPart)の二種類がある。
ジョブフローは、入力・出力のファイルまで定義し、アプリケーションとして完結した状態になる。Batch DSLに記述できるのはジョブフローのみ。
フローパートは、いくつかの演算子をまとめてひとつの演算子として扱うもの。「フロー部品」とも呼ばれる。いわばサブルーチンを作ることになる。フローパートは、他のFlow DSL内に演算子として記述できる。
Asakusaアプリケーションではジョブフローは必ず作る必要があるが、フローパートは必要に応じて作ればよい。
(大規模なアプリケーションであれば、フローパートを使ってジョブフロー内を分割した方がよい)
フローパートはコンパイル時に内部の演算子が展開されるので、コンパイルして作られるバッチアプリケーションが実行される際には全く影響しない。
→Toad Editor(図をGUIで描いてFlow DSLを生成できるツール)
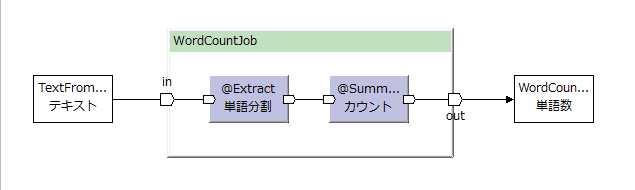
WordCountのジョブフローを考えてみる。
WordCountは、テキストファイルを単語に分割し、単語数をカウントするアプリケーション。
処理の流れは以下のようになる。
演算子(オペレーター)は、単語分割するsplitと、単語数を数えるcountとなる。
これらは別途WordCountOperatorクラスで定義されているものとする。
すると、このジョブフローのFlow DSLは以下のように記述できる。
import com.asakusafw.vocabulary.flow.*; import com.example.modelgen.dmdl.model.TextModel; import com.example.modelgen.dmdl.model.WordCountModel; import com.example.wordcount.job.TextFromCsv; import com.example.wordcount.job.WordCountToCsv; import com.example.wordcount.operator.WordCountOperatorFactory; import com.example.wordcount.operator.WordCountOperatorFactory.Count; import com.example.wordcount.operator.WordCountOperatorFactory.Split;
@JobFlow(name = "WordCountJob")
public class WordCountJob extends FlowDescription {
private final In<TextModel> in;
private final Out<WordCountModel> out;
ジョブフローのFlow DSLは、クラス名に@JobFlowアノテーションを付け、FlowDescriptionを継承する。
ここで指定したジョブフローID(ジョブ名)をBatch DSLで記述することになる。
(ジョブフローのクラス名と一致させておくのが分かりやすくて無難だと思われる)
コンストラクターで、ジョブフローの入出力ファイルを指定する。
public WordCountJob(
@Import(name = "in", description = TextFromCsv.class) In<TextModel> in,
@Export(name = "out", description = WordCountToCsv.class) Out<WordCountModel> out
) {
this.in = in;
this.out = out;
}
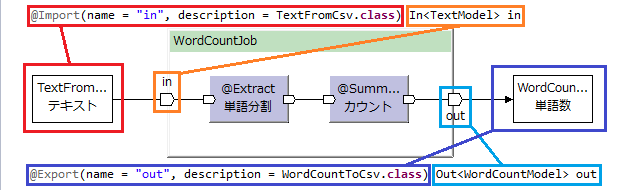
@Importで入力ファイル(インポーター)、@Exportで出力ファイル(エクスポーター)を指定する。
@Importや@Exportのnameは、バッチ実行時やテストをコーディングする際に入出力データを示す名前として使われる。
(コンストラクターの変数名と一致させておくのが分かりやすくて無難だと思われる)
descriptionには、具体的なファイルを表すImporter/Exporterクラスを指定する。
In<>でジョブフローへの入力ポート、Out<>でジョブフローからの出力ポートを指定する。
(AsakusaFWでは、演算子やジョブフローのデータの出入り口のことをポートと呼ぶ)
フローの本体はdescribeメソッドに記述する。
@Override
public void describe() {
WordCountOperatorFactory operators = new WordCountOperatorFactory();
// 単語分割
Split split = operators.split(this.in);
// カウント
Count count = operators.count(split.out);
out.add(count.out);
}
}
まず、演算子が定義されているWordCountOperator(AsakusaFWによってコンパイルされてファクトリクークラスになっている)を指定する。
そして、データフロー通り、inを入力としてsplitを呼び出し、その結果をcountに渡して最終的にoutに出力している。
Flow DSLの考え方としては、split・countという演算子を用意し、それらの演算子の入出力ポートを他の演算子や外部入出力ポートと接続している。
(結果として、演算子を呼び出す順序を記述していることになる。Flow DSLは、Asakusaアプリケーションのデータフロー(演算子の処理順序)を記述することに特化した言語である)
AsakusaFWでは作成した演算子のことを「語彙」とも呼ぶので、「語彙を使って文章(処理内容)を記述している」と捉えることも出来る。
別の見方として、普通のJavaアプリケーションとして見てみれば、普通にoperatorsのメソッドを呼び出して処理を実行しているだけとも見える。
つまり、Flow DSL(ドメイン特化言語)と名乗ってはいるが、普通のJavaアプリケーションのコーディングとそんなに変わらないとも言える。
実際には、Flow DSLはコンパイル時に解釈されて実行情報に変換される。
実際のバッチ実行時にdescribeメソッドが直接呼ばれるわけではない。
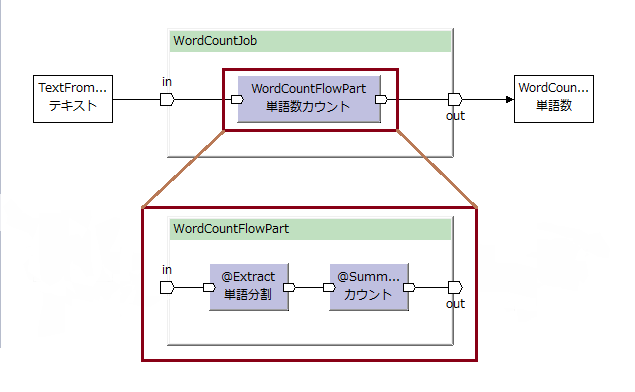
フロー演算子(FlowPart)は、いくつかの演算子をまとめてひとつの演算子として扱えるようにする。いわばサブルーチンを作るようなもの。
こうすることにより、呼び出し側では直接登場する演算子が少なくなるので、分かりやすくなる。
また、フローパートは別々のジョブフローや他のフローパートからも呼び出すことが出来るので、共通部品として使える。
WordCountくらい小さなアプリケーションだとわざわざフローパートを作る必要も無いが、例として作ってみる。
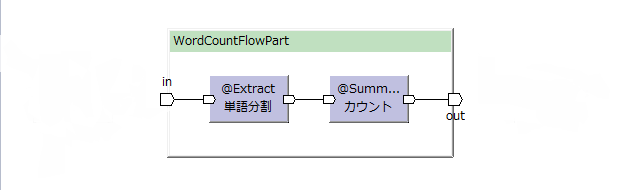
WordCountのジョブフローからはWordCountFlowPartを呼び出す。
WordCountFlowPart内で個別の演算子を呼び出す。
import com.asakusafw.vocabulary.flow.*; import com.example.modelgen.dmdl.model.TextModel; import com.example.modelgen.dmdl.model.WordCountModel; import com.example.wordcount.operator.WordCountOperatorFactory; import com.example.wordcount.operator.WordCountOperatorFactory.Count; import com.example.wordcount.operator.WordCountOperatorFactory.Split;
@FlowPart
public class WordCountFlowPart extends FlowDescription {
private final In<TextModel> in;
private final Out<WordCountModel> out;
フローパートのFlow DSLは、@FlowPartアノテーションを付け、FlowDescriptionを継承する。
@JobFlowと異なり、nameを付ける必要は無い(というか、付けられない)。
コンストラクターで、フローパートの入出力ポートを記述する。
public WordCountFlowPart(
In<TextModel> in,
Out<WordCountModel> out
) {
this.in = in;
this.out = out;
}
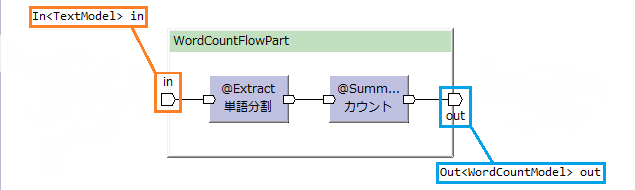
In<>でフローパートへの入力ポート、Out<>でフローパートからの出力ポートを指定する。
(AsakusaFWでは、演算子(フローパートも含む)やジョブフローのデータの出入り口のことをポートと呼ぶ)
フローの本体はdescribeメソッドに記述する。
(これは、ジョブフロー版WordCountのジョブフロークラスのdescibeメソッドと全く同一になる)
@Override
public void describe() {
WordCountOperatorFactory operators = new WordCountOperatorFactory();
// 単語分割
Split split = operators.split(this.in);
// カウント
Count count = operators.count(split.out);
out.add(count.out);
}
}
Flow DSLでは、コンストラクターでIn/Outをフィールドに移送し、describeメソッドではフィールドを使うようになっている。
本当なら、フローの入出力ポートを表すin,outはdescribeメソッドの引数にあると、コンストラクターでわざわざフィールドに移送する必要は無いと思う。
// イメージ
public void describe(In<TextModel> in, Out<WordCountModel> out) {
〜
}
しかしそうするとdescribeメソッドの引数はアプリケーション次第で変わってしまうので、describeメソッドを親クラスで定義しておいてオーバーライドする、ということが出来なくなってしまう。
だから現在のような形になっているのだと思う。
(とは言え、コンストラクターの引数はコンパイル時に解析しているので、同様のことをdescribeメソッドでやるようにすれば出来なくはない気がする。
が、FlowPartのテストドライバーに入出力データ入りのインスタンスを渡せなくなるから駄目か。…runTest()の引数にIn/Outを移せば出来るか?
あるいはコンストラクター内でフローを全部記述してしまうとか。
でもこれも、テストドライバーに渡す為のインスタンスを生成しただけでフローを実行しちゃうことになるから駄目だな)
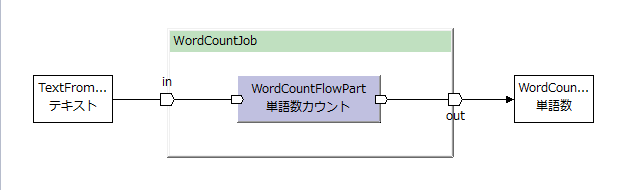
フローパートを呼び出すジョブフロー側は、ジョブフロー版WordCountJobとほとんど同じで、呼び出す演算子が異なるのみ。
したがって、describeメソッドの中が異なるだけで、コンストラクターは全く同じ。
@JobFlow(name = "WordCountJob")
public class WordCountJob extends FlowDescription {
〜
@Override
public void describe() {
WordCountFlowPartFactory wordCountFlowPartFactory = new WordCountFlowPartFactory();
// 単語数カウント
WordCountFlowPart wordCount = wordCountFlowPartFactory.create(this.in);
this.out.add(wordCount.out);
}
}
フローパートクラスはコンパイルされてファクトリークラスが作られる。
(通常の演算子(オペレーター)では、ファクトリークラスのインスタンスに演算子メソッドが定義されているが、)
フローパートではファクトリーのcreateメソッドを呼び出すようにコーディングする。
WordCountJobとWordCountFlowPartを例にすると、ジョブフローとフローパートは以下のようになる。
| フローの図 | Flow DSLのコンストラクター | |
|---|---|---|
| ジョブフロー | |
public WordCountJob( @Import(name = "in", description = TextFromCsv.class) In<TextModel> in, @Export(name = "out", description = WordCountToCsv.class) Out<WordCountModel> out ) { this.in = in; this.out = out; } |
| フローパート | |
public WordCountFlowPart(
In<TextModel> in,
Out<WordCountModel> out
) {
this.in = in;
this.out = out;
}
|
見て分かる通り、(フロー名の違いを除くと、)入出力ファイルを表すインポーター・エクスポーターの有無がジョブフローとフローパートの異なる点。
Flow DSLのコンストラクターでも、フローパートには@Import・@Exportが無い。
(なお、データフロー本体(describeメソッド内)は完全に同一となる)
ジョブフローはアプリケーションとして完成したデータフローなので、入出力ファイル(外部入出力)が決定されていなければならない。
フローパートは部品(データフローの一部分)なので、外部入出力はフローパートを使う側によって決まる。したがって、フローパートでは入出力ファイルは指定しない。
Flow DSLのフローを設計する上での基本的な考え方。[2013-11-04]
AsakusaFWはバッチアプリケーションを作る為のフレームワークであり、入力と出力はファイルである。(RDBのテーブルも扱えるけど、論理的にはファイルと同じ)
つまり、バッチアプリケーションは、入力ファイルを加工して出力ファイルを得る。
バッチアプリケーション内部も、バッチアプリケーションと同じ。
最終的な出力ファイルを得る為に、ちょっとずつ加工した中間ファイルを作り出す。
中間ファイルは、元のデータを加工したり集計したり、データ同士を結合したりして作る。
そういった加工処理の最小粒度が個々の演算子になる。
※考え方としては、各演算子の出力結果は中間ファイルだが、実際に実行される際には逐一中間ファイルが作られるわけではない。
※あるいは、ファイルではなくデータモデルのリストと考えた方がAsakusaFWの実態に近いかもしれない。List<A>を加工して中間のList<B>を作り、最終的にList<Z>を作り出す。
Flow DSLは、なぜデータフローの図(グラフ)ベースでなく、テキストベースのDSLなのか?
(GUIで図形を配置する方式ではなく、テキストで記述する方式なのか?)
Asakusa Frameworkは、「設計をきちんと行い、設計から直接DSLに記述(コーディング)する」という思想になっている。
AsakusaFWにおける設計では、データフローの図を描くことになる。
図が描けてしまえば、後はオペレーター(演算子)のコーディングを行い、Flow DSLでそれらを呼び出すよう記述する。
設計の図とFlow DSLは1:1になる(ように設計する)ので、対応が分かりやすい。
ということであれば、最初からFlow DSLはデータフローの図で記述してもいいんじゃないか?と思ってしまう。
しかし、WordCountくらいシンプルであれば図を描くのもそれほど大変ではないが、
演算子が数十個以上にもなってくると、図形(演算子)を配置して線を結ぶのも一苦労になってくる。
(一画面に入り切らないので、線を結びたい図形へ移動するのにスクロールさせないといけないとか)
設計では試行錯誤して図形(演算子)を追加削除するので、整列とかの操作は専用ツールに任せた方が楽だろう。
そういうGUIツールを作る労力と、テキストベースのDSL(しかもホスト言語をJavaとする内部DSL)を作る労力を比較すれば、GUIツールを作るのはかなり難しそうだ。
それに、テキストベースのDSLであれば、演算子の線を引く(演算子同士を接続する)というのは「オペレーターのメソッドの引数にデータの変数を指定する」という形になる。
これはプログラマーにとってはいつもやっていることであり、何も難しくない。
特にDSLのホスト言語としてJavaを使っていれば、Javaのエディター(Eclipse等のIDE)の機能を使うという恩恵が受けられる。(入力補完がとても便利)
間違った接続をする、つまりオペレーターの引数に本来指定できない変数を指定すると、データ型が異なるのでコンパイルエラーになってすぐ分かる。
演算子の追加削除(コピペ)なんかもテキストなら簡単だ。変数名の変更なんかも簡単だし。
(ちなみに、内部DSLを作るのに適していると言われるScala等が採用されなかったのは、AsakusaFWが作られた当時はScala
IDEがまだ未熟であったのと、SIerが使っているのはやはりJavaが多いからだろうと思う(AsakusaFWが実行基盤としているHadoopもJavaだし))
つまり、AsakusaFWが想定する大規模なバッチアプリケーションでは、図を描くよりもテキストベースの方がコーディングしやすいという考えで、Flow DSLはテキストベースになっているのだろう。
とは言っても、やはり元がデータフローなので、データフローで見えた方が分かりやすいのは確か。
設計のデータフローと実装されたFlow DSLがちゃんと一致しているかを確認する場合も、実装側がグラフ化された方が比較しやすい。
記述されたFlow DSLをGraphvizによってグラフ化(DSLの可視化(フローグラフの生成))する機能があるのもその一環だろう。
また、AsakusaFWのサービスであるNode0 DBRではFlow DSLを(Graphvizのとは違った形で)グラフ化する機能を提供している。