ポート数
の制約
ポート数
の制約
に対する
出力レコード数
データモデル
いずれかのポートに
必ず1レコード出力される。
(各ポートは0〜1レコード)
Asakusa FrameworkのOperator DSLのマスター分岐演算子(@MasterBranch)のメモ。
|
マスター分岐演算子は、レコードに合致するマスターレコードの内容に応じてトランザクション(明細)レコードを別々の出力先に振り分ける演算子。
性能特性はJoin(旧ドキュメントではReduce、最適化によってはMap)。[/2016-02-11]
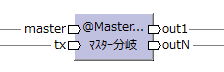
| 入力 ポート数 |
入力データモデル の制約 |
イメージ | 出力 ポート数 |
出力データモデル の制約 |
入力1レコード に対する 出力レコード数 |
|
|---|---|---|---|---|---|---|
| 2 | master | (マスター) |
|
任意 | 全てtxと同じ データモデル |
txの1レコードに対し いずれかのポートに 必ず1レコード出力される。 (各ポートは0〜1レコード) |
| tx | ||||||
どういう内容のときにどこに出力するかをプログラマーが実装する。
マスター分岐演算子は、出力後にマスターデータは使用しないが、マスターデータの内容に応じて処理を分岐したい場合に使う。
マスターと結合した新しいデータモデルを出力したい場合はマスター結合演算子(@MasterJoin)を使う。
合致するマスターが存在するかどうかを確認するだけの場合はマスター確認演算子(@MasterCheck)を使う。
(マスターデータは出力しないが)結合したマスターデータの値によってトランザクションレコードの値を変更したい場合はマスターつき更新演算子(@MasterJoinUpdate)を使う。
hoge_transactionに合致するhoge_masterの内容に応じて処理を分岐させる例。
(この図はToad Editorを用いて作っています)
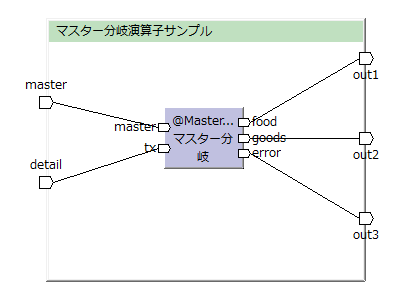
| 入力データ例 | 出力データ例 | |||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| master |
|
→ | food |
|
||||||||||||||||||||||||||||||
| → | goods |
|
||||||||||||||||||||||||||||||||
| tx |
|
|||||||||||||||||||||||||||||||||
| → | error |
|
||||||||||||||||||||||||||||||||
hoge_master = {
id : TEXT;
name : TEXT;
group : INT;
};
hoge_transaction = {
date : DATE;
master_id : TEXT;
value : LONG;
};
import com.asakusafw.vocabulary.model.Key; import com.asakusafw.vocabulary.operator.MasterBranch; import com.example.modelgen.dmdl.model.HogeMaster; import com.example.modelgen.dmdl.model.HogeTransaction;
public abstract class ExampleOperator {
/**
* マスターのグループに応じて処理を分岐する
*
* @param master
* マスターデータ。存在しない場合は{@code null}
* @param tx
* トランザクションデータ
* @return 分岐先を表すオブジェクト
*/
@MasterBranch
public Group branchWithJoin(
@Key(group = "id") HogeMaster master,
@Key(group = "master_id") HogeTransaction tx
) {
if (master == null) {
// 合致するマスターが存在しない
return Group.ERROR;
}
int group = master.getGroup();
if (0 <= group && group < 100) {
return Group.FOOD;
}
if (100 <= group && group < 200) {
return Group.GOODS;
}
return Group.ERROR;
}
public enum Group {
FOOD,
GOODS,
ERROR,
}
}
マスター分岐演算子では、出力先を表す列挙型(この例ではGroup)を返すメソッド(この例ではbranchWithJoin())を定義する。
列挙型なので、命名規則は大文字のスネークケースにする。(単語を大文字で書き、単語と単語をつなぎたい場合は「_(アンダースコア)」を使用する)
メソッドの第1引数でマスターとなるデータモデル、第2引数でトランザクション(明細)となるデータモデルを指定する。
各引数には@Keyアノテーションを付けて、結合キーを指定する。
複数の項目を結合キーとする場合は「@Key(group = { "key1", "key2" })」のように波括弧でくくってカンマ区切りで指定する。
MasterBranchでは、マスターを表す第1引数にnullが来ることがあるので、nullチェックが必要。[2015-03-22]
トランザクションに合致するマスターが無い場合、第1引数がnullになる。(トランザクションを表す第2引数がnullになることは無い)
(他のMaster系演算子では、合致するマスターが無い場合はmissedに出力される。特にMasterJoinUpdateでは、この場合、自分がコーディングしたメソッドは呼ばれないので、常にマスターが来る前提でコーディングできる)
※メソッド内では引数で渡されたデータモデルの値を変更するようなコーディングをしてしまうことも出来るが、ここで値を変えても出力データが変わるわけではない。
(むしろフレームワーク側でデータが初期化されず次レコードの判定でおかしな挙動になる可能性もありそうなので、すべきではない)
値を変更したい場合はマスターつき更新演算子(@MasterJoinUpdate)を使用する。
import com.example.modelgen.dmdl.model.HogeMaster; import com.example.modelgen.dmdl.model.HogeTransaction; import com.example.operator.ExampleOperatorFactory; import com.example.operator.ExampleOperatorFactory.BranchWithJoin;
private final In<HogeMaster> master; private final In<HogeTransaction> detail; private final Out<HogeTransaction> out1; private final Out<HogeTransaction> out2; private final Out<HogeTransaction> out3;
@Override
public void describe() {
ExampleOperatorFactory operators = new ExampleOperatorFactory();
// マスター分岐
BranchWithJoin branch = operators.branchWithJoin(this.master, this.detail);
this.out1.add(branch.food);
this.out2.add(branch.goods);
this.out3.add(branch.error);
}
Flow DSLでは、自分が作ったOperatorのFactoryクラス(AsakusaFWのコンパイラーによって生成される)を使用する。
メソッド名はOperatorクラスに書いたメソッド名と同じ。
戻り値の型はAsakusaFWのコンパイラーによって生成されたクラス。(メソッド名を先頭が大文字のキャメルケースに変換したもの)
メソッドの引数は第1引数がマスターデータ、第2引数がトランザクション(明細)データ。
出力ポートの名前は、列挙型で定義した各列挙子の名前(FOODとかGOODSとか)を先頭が小文字のキャメルケースに変換したものになる。
(例:列挙子が「ERROR_PRICE」だったら、出力ポート名は「errorPrice」になる)
マスター分岐演算子の単体テストの実装例。
package com.example.operator;
import static org.hamcrest.CoreMatchers.is; import static org.junit.Assert.assertThat; import org.junit.Test; import com.example.modelgen.dmdl.model.Hoge; import com.example.operator.ExampleOperator.Group;
/**
* {@link ExampleOperator}のテスト.
*/
public class ExampleOperatorTest {
@Test
public void branchWithJoinNull() {
ExampleOperator operator = new ExampleOperatorImpl();
HogeMaster master = null;
HogeTransaction tx = new HogeTransaction();
Group result = operator.branchWithJoin(master, tx);
assertThat(result, is(Group.ERROR));
}
@Test
public void branchWithJoinFood() {
test(0, Group.FOOD);
test(99, Group.FOOD);
}
@Test
public void branchWithJoinGoods() {
test(100, Group.GOODS);
test(199, Group.GOODS);
}
@Test
public void branchWithJoinError() {
test(-1, Group.ERROR);
test(200, Group.ERROR);
}
private void test(int group, Status expected) {
ExampleOperator operator = new ExampleOperatorImpl();
HogeMaster master = new HogeMaster();
master.setGroup(group);
HogeTransaction tx = new HogeTransaction();
Group result = operator.branchWithJoin(master, tx);
assertThat(result, is(expected));
}
}
Operatorのテストクラスは、通常のJavaのJUnitのテストケースクラスとして作成する。
テスト対象のOperatorクラス自身は抽象クラスだが、Operatorクラス名の末尾に「Impl」の付いた具象クラスがAsakusaFWによって生成されるので、それを使う。
マスター分岐演算子は、マスター結合+分岐+分割で同様の処理を行うことが出来る。
(分割演算子(@Split)は、結合モデルを結合元のデータモデルに戻す演算子)
が、どう見てもマスター分岐演算子の方が(見た目の分かりやすさも実行効率も)良い。
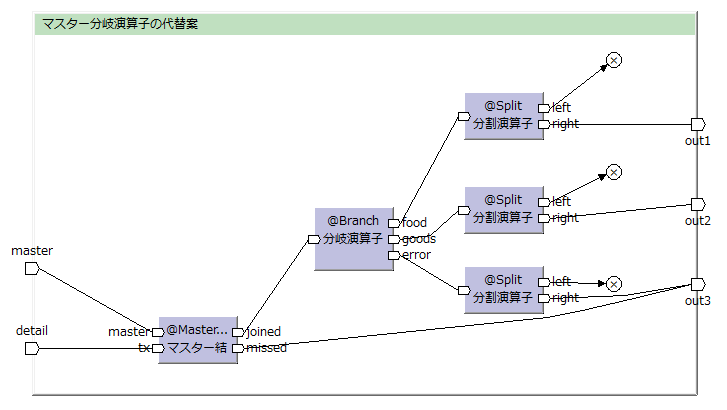
逆に言うと、後の処理で結合したデータを使うなら、マスター結合+分岐にする。
マスター分岐演算子は、SQLのJOINに似ている。
INSERT INTO food SELECT tx.* FROM tx INNER JOIN master ON master.id = tx.master_id WHERE 0 <= master.group AND master.group < 100;