ポート数
の制約
ポート数
の制約
に対する
出力レコード数
(0〜∞レコード)
Asakusa FrameworkのOperator DSLのグループ結合演算子(@CoGroup)のメモ。
|
グループ結合演算子は、複数の入力をキーでグルーピングし、キーが一致するデータ毎に処理して複数種類(複数データモデル)・複数レコードの出力を行う。
性能特性はCoGroup(旧ドキュメントではReduce)。[/2016-02-11]
| 入力 ポート数 |
入力データモデル の制約 |
イメージ | 出力 ポート数 |
出力データモデル の制約 |
入力1レコード に対する 出力レコード数 |
|---|---|---|---|---|---|
| 任意 |
|
任意 | 任意。 (0〜∞レコード) |
グループ結合演算子はAsakusaFWの演算子の中で最強(何でも記述できる)の演算子なので、他の演算子の組み合わせで処理が出来るようなら、そちらにすることを検討すべき。
(極端に言えば、グループ結合演算子だけあれば全て書けてしまう。しかしグループ結合演算子だけでフローを構成すると最適化されない)
入力ポートが1つの場合はグループ整列演算子(@GroupSort)を使う。
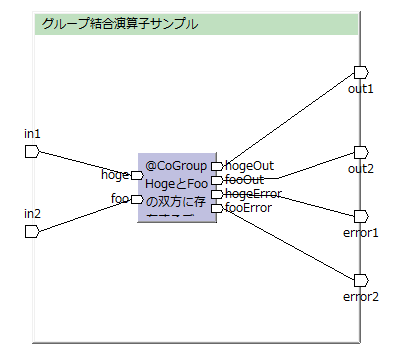
hogeとfooをIDでグループ化し、双方に1レコードずつ存在する場合だけ出力し、それ以外はエラーとして出力する例。
(この図はToad Editorを用いて作っています)
| 入力データ例 | 出力データ例 | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| hoge |
|
→ | hogeOut |
|
||||||||||||||||
| → | fooOut |
|
||||||||||||||||||
| foo |
|
→ | hogeError |
|
||||||||||||||||
| → | fooError |
|
||||||||||||||||||
hoge = {
id : TEXT;
name : TEXT;
};
foo = {
hoge_id : TEXT;
value : LONG;
};
import java.util.List; import com.asakusafw.runtime.core.Result; import com.asakusafw.vocabulary.model.Key; import com.asakusafw.vocabulary.operator.CoGroup; import com.example.modelgen.dmdl.model.Foo; import com.example.modelgen.dmdl.model.Hoge;
public abstract class ExampleOperator {
/**
* HogeとFooの双方に1レコードずつ存在するデータを出力する
*
* @param hogeList Hogeのグループ毎のリスト
* @param fooList Fooのグループ毎のリスト
* @param hogeOut 成功したHoge
* @param fooOut 成功したFoo
* @param hogeError 失敗したHoge
* @param fooError 失敗したFoo
*/
@CoGroup
public void checkUp(
@Key(group = "id") List<Hoge> hogeList,
@Key(group = "hoge_id") List<Foo> fooList,
Result<Hoge> hogeOut,
Result<Foo> fooOut,
Result<Hoge> hogeError,
Result<Foo> fooError
) {
if (hogeList.size() == 1 && fooList.size() == 1) {
// 双方に1レコードずつ存在する場合は突合成功
hogeOut.add(hogeList.get(0));
fooOut.add(fooList.get(0));
} else {
// それ以外はエラー
for (Hoge hoge : hogeList) {
hogeError.add(hoge);
}
for (Foo foo : fooList) {
fooError.add(foo);
}
}
}
}
引数の最初の方で、入力ポートを表すList<データモデル>を指定する。
各引数には@Keyアノテーションを付けて、結合キーを指定する。
複数の項目を結合キーとする場合は「@Key(group = { "key1", "key2" })」のように波括弧でくくってカンマ区切りで指定する。
また、@Keyアノテーションのorderでソートキーを指定できる。
いずれかのListには必ず1件以上データが入ってくる。[2017-02-11]
結合キーに合致するデータが無い場合は、そのデータを表すListは空(0件)の状態で渡ってくる。[2015-03-22]
入力ポートの引数の次に、出力ポートを表すResult<データモデル>を指定する。
import com.example.modelgen.dmdl.model.Foo; import com.example.modelgen.dmdl.model.Hoge; import com.example.operator.ExampleOperatorFactory; import com.example.operator.ExampleOperatorFactory.CheckUp;
private final In<Hoge> in1; private final In<Foo> in2; private final Out<Hoge> out1; private final Out<Foo> out2; private final Out<Hoge> error1; private final Out<Foo> error2;
@Override
public void describe() {
ExampleOperatorFactory operators = new ExampleOperatorFactory();
// HogeとFooの双方に1レコードずつ存在するデータを出力する
CheckUp checkUp = operators.checkUp(this.in1, this.in2);
this.out1.add(checkUp.hogeOut);
this.out2.add(checkUp.fooOut);
this.error1.add(checkUp.hogeError);
this.error2.add(checkUp.fooError);
}
Flow DSLでは、自分が作ったOperatorのFactoryクラス(AsakusaFWのコンパイラーによって生成される)を使用する。
メソッド名はOperatorクラスに書いたメソッド名と同じ。
戻り値の型はAsakusaFWのコンパイラーによって生成されたクラス。(メソッド名を先頭が大文字のキャメルケースに変換したもの)
メソッドの引数はOperatorクラスのメソッドに入力ポート(List<データモデル>)として指定したデータ。
出力ポートの名前は、Operatorクラスのメソッドに出力ポート(Result<データモデル>)として指定した変数名が使われる。
グループ結合演算子の単体テストの実装例。
package com.example.operator;
import static org.hamcrest.CoreMatchers.is; import static org.junit.Assert.assertThat; import java.util.Arrays; import java.util.List; import org.junit.Test; import com.asakusafw.runtime.testing.MockResult; import com.example.modelgen.dmdl.model.Foo; import com.example.modelgen.dmdl.model.Hoge;
/**
* {@link ExampleOperator}のテスト.
*/
public class ExampleOperatorTest {
@Test
public void checkUp() {
ExampleOperator operator = new ExampleOperatorImpl();
Hoge hoge = new Hoge();
hoge.setIdAsString("aaa");
List<Hoge> hogeList = Arrays.asList(hoge);
Foo foo = new Foo();
foo.setValue(123);
List<Foo> fooList = Arrays.asList(foo);
MockResult<Hoge> hogeOut = new HogeMockResult();
MockResult<Foo> fooOut = new FooMockResult();
MockResult<Hoge> hogeError = new HogeMockResult();
MockResult<Foo> fooError = new FooMockResult();
operator.checkUp(hogeList, fooList, hogeOut, fooOut, hogeError, fooError);
{
assertThat(hogeOut.getResults().size(), is(1));
assertThat(hogeOut.getResults().get(0), is(hoge));
}
{
assertThat(fooOut.getResults().size(), is(1));
assertThat(fooOut.getResults().get(0), is(foo));
}
assertThat(hogeError.getResults().size(), is(0));
assertThat(fooError.getResults().size(), is(0));
}
@Test
〜エラーケース〜
}
Operatorのテストクラスは、通常のJavaのJUnitのテストケースクラスとして作成する。
テスト対象のOperatorクラス自身は抽象クラスだが、Operatorクラス名の末尾に「Impl」の付いた具象クラスがAsakusaFWによって生成されるので、それを使う。
グループ結合演算子では引数にResultが使われているので、その引数にはMockResultを渡す。
OperatorメソッドでResultに追加したデータモデルは、MockResult内のリストに追加されていく。MockResult#getResults()でそのリストを取得できる。
ただし、Operatorクラス側でデータモデルのインスタンスを使い回している場合は、MockResultのリストにそのインスタンスを追加するだけだと、後から値を確認したくても最後の値しか取れない。
そこで、MockResult#bless()をオーバーライドし、インスタンスのコピーを返すようにする。こうすると、MockResultのリストにはコピーしたインスタンスが保持される。
public class HogeMockResult extends MockResult<Hoge> {
@Override
protected Hoge bless(Hoge result) {
Hoge copy = new Hoge();
copy.copyFrom(result);
return copy;
}
}
public class FooMockResult extends MockResult<Foo> {
@Override
protected Foo bless(Foo result) {
Foo copy = new Foo();
copy.copyFrom(result);
return copy;
}
}
グループ結合演算子では、入出力のデータモデルの他にも引数を指定することが出来る。
こうすると、引数の内容分だけ異なる同じ演算子(処理内容)をいくつかの場所で使用できるようになる。
先の例に値引数を追加する例。
@CoGroup public void checkUp( @Key(group = "id") List<Hoge> hogeList, @Key(group = "hoge_id") List<Foo> fooList, Result<Hoge> hogeOut, Result<Foo> fooOut, Result<Hoge> hogeError, Result<Foo> fooError, int hogeSize, int fooSize ) { if (hogeList.size() == hogeSize && fooList.size() == fooSize) { // 双方に存在する場合は突合成功 hogeOut.add(hogeList.get(0)); fooOut.add(fooList.get(0)); } else { // それ以外はエラー for (Hoge hoge : hogeList) { hogeError.add(hoge); } for (Foo foo : fooList) { fooError.add(foo); } } }
出力ポートを示す引数以降を通常のJavaメソッドと同様に自由な引数とすることが出来る。(ただしプリミティブのみ)
@Override
public void describe() {
ExampleOperatorFactory operators = new ExampleOperatorFactory();
// HogeとFooの双方に1レコードずつ存在するデータを出力する
CheckUp checkUp = operators.checkUp(this.in1, this.in2, 1, 1);
〜
}
演算子を使用するFlow DSLで、引数に具体的な値を指定する。
グループ結合演算子のOperatorクラスのメソッドで入力データを表すList<データモデル>は、
デフォルトでは少量のデータ、つまりメモリー内に乗り切るデータ量が想定されている。
その為、1つのグループに大量のデータが来るとOutOfMemoryErrorになってしまう。
1つのグループで大量のデータを扱いたい場合は、@CoGroupアノテーションでInputBuffer.ESCAPEを指定する。
(デフォルトではInputBuffer.EXPANDが指定されている)
import java.util.List; import com.asakusafw.vocabulary.flow.processor.InputBuffer; import com.asakusafw.vocabulary.model.Key; import com.asakusafw.vocabulary.operator.CoGroup;
@CoGroup(inputBuffer = InputBuffer.ESCAPE)
public void checkUp(
@Key(group = "id") List<Hoge> hogeList,
@Key(group = "hoge_id") List<Foo> fooList,
〜
) {
〜
}
ただし、ESCAPEを指定すると、入力のListの使い方に制限がかかる。
あと、メモリーに乗り切らないということは一時ファイルにデータが置かれることもあるということなので、処理速度も遅くなる可能性がある。
グループ結合演算子では、入力データをソートすることが出来る。
ソートキーは、結合キーとは別に指定できる。
@CoGroup public void checkUp( @Key(group = "id", order = "name") List<Hoge> hogeList, @Key(group = "hoge_id", order = "value") List<Foo> fooList, 〜 ) { 〜 }
@Keyアノテーションのorderにソートキーを指定する。
| 例 | 説明 |
|---|---|
order = "key" |
ソート項目を1つ指定する例。 ソート順は昇順となる。 |
order = "key ASC" order = "key DESC" |
ASCを指定すると昇順になる。 DESCを指定すると降順になる。 |
order = { "key1 ASC", "key2 ASC" }
|
複数のソート項目を指定する例。 |
このソートは、あくまでもグループ結合演算子の入力データに対するソート。
グループ結合演算子から出力したデータは、必ずしも出力した順序になるとは限らない。
最終的な出力ファイルをソートしたい場合は、Direct I/OだとExporterクラスでソートキーを指定する。
AsakusaFW 0.9.1で、入力データを(Listでなく)Iterableで受け取ることが出来るようになった。[2017-04-30]
GroupSortのIterableの例を参照。(Iterableの使い方はGroupSortと同じ)
AsakusaFW 0.9.1以降では、インスタンスを一度ずつしか使用しない場合は、@Onceを付けて明示できる。[2017-04-30]
(AsakusaFW 0.10.0で正式機能となった。[2017-12-11])
GroupSortの@Onceの例を参照。(@Onceの使い方はGroupSortと同じ)
AsakusaFW 0.9.1以降では、入力データ(ListやIterable)に@Spillを付けることが出来る。[2017-04-30]
(AsakusaFW 0.10.0で正式機能となった。[2017-12-11])
これを付けると、(InputBuffer.ESCAPEと同じように)入力データ数が多い場合に、ファイルへ退避するようになる。
InputBuffer.ESCAPEはCoGroupアノテーションで指定するので、入力の種類(入力ポート)が複数ある場合は全部に効いてしまう。
@Spillは入力ポート毎に個別に指定できる。
import com.asakusafw.vocabulary.model.Spill;
@CoGroup
public void checkUp(
@Key(group = "id", order = "name") List<Hoge> hogeList,
@Key(group = "hoge_id", order = "value") @Spill List<Foo> fooList,
〜
) {
〜
}