ポート数
の制約
ポート数
の制約
に対する
出力レコード数
1レコード。
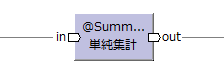
Asakusa FrameworkのOperator DSLの単純集計演算子(@Summarize)のメモ。
|
単純集計演算子は、レコードを集計キー毎に集計する演算子。
性能特性はFold(旧ドキュメントではReduce)。[/2016-02-11]
| 入力 ポート数 |
入力データモデル の制約 |
イメージ | 出力 ポート数 |
出力データモデル の制約 |
入力1レコード に対する 出力レコード数 |
|---|---|---|---|---|---|
| 1 |
|
1 | 集計モデル | 集計キー毎に 1レコード。 |
単純集計演算子の集計結果のデータモデルは、DMDLで集計モデルとして定義する必要がある。
(集計キーや集計方法を集計モデルで指定する)
集計モデルでは、集計キーによってグループ化されたデータに対して以下のような集計を行うことが出来る。
もっと複雑な集計を行いたい場合や集計前後で同じデータモデルを扱いたい場合は畳み込み演算子(@Fold)が利用できないか検討する。
最悪の場合はグループ整列演算子(@GroupSort)で集計を行う。
平均値を算出したい場合は、単純集計演算子でレコード数と合計を算出し、変換演算子(@Convert)や更新演算子(@Update)等を用いて「合計÷レコード数」を計算する。
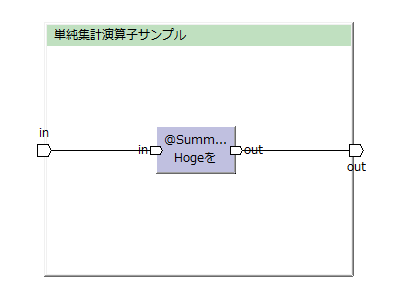
hogeを集計してhoge_totalを出力する例。
(この図はToad Editorを用いて作っています)
| 入力データ例 | 出力データ例 | |||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| in |
|
→ | out |
|
||||||||||||||||||||||||||
idでグループ化し(idを集計キーとして)、件数(レコード数)と合計を出力する。
hoge = {
id : TEXT;
value : INT;
};
summarized hoge_total = hoge => {
any id -> id;
count id -> count;
sum value -> total;
} % id;
単純集計演算子で結合した結果を表すデータモデルは、集計モデル(summarizedを先頭に付けたデータモデル)にする必要がある。
→集計モデルの書き方
import com.asakusafw.vocabulary.operator.Summarize; import com.example.modelgen.dmdl.model.Hoge; import com.example.modelgen.dmdl.model.HogeTotal;
public abstract class ExampleOperator {
/**
* HogeをHogeTotalに集計する
*
* @param hoge
* 集計対象
* @return 集計結果
*/
@Summarize
public abstract HogeTotal summarize(Hoge hoge);
}
単純集計演算子は抽象メソッドとして定義する。
引数で入力となるデータモデルを指定する。
戻り値の型は集計結果のデータモデル(集計モデル)を指定する。
import com.example.modelgen.dmdl.model.Hoge; import com.example.modelgen.dmdl.model.HogeTotal; import com.example.operator.ExampleOperatorFactory; import com.example.operator.ExampleOperatorFactory.Summarize;
private final In<Hoge> in; private final Out<HogeTotal> out;
@Override
public void describe() {
ExampleOperatorFactory operators = new ExampleOperatorFactory();
// HogeをHogeTotalに集計する
Summarize sum = operators.summarize(this.in);
this.out.add(sum.out);
}
Flow DSLでは、自分が作ったOperatorのFactoryクラス(AsakusaFWのコンパイラーによって生成される)を使用する。
メソッド名はOperatorクラスに書いたメソッド名と同じ。
戻り値の型はAsakusaFWのコンパイラーによって生成されたクラス。(メソッド名を先頭が大文字のキャメルケースに変換したもの)
出力ポートの名前のデフォルトはout。
出力ポート名を変えたい場合は@Summarizeアノテーションで指定できる。
@Summarize(summarizedPort = "out")
単純集計演算子は抽象メソッドなので、(Operatorクラスにプログラマーがメソッド本体を実装していないので)Operatorの単体テストを実装する必要は無い。
単純集計演算子では、部分集約を行うかどうかを指定できる。
部分集約とは、ストレートに言うとHadoopのCombinerを使うかどうかの指定。
普通は部分集約を行う方が実行効率が良くなる。
@SummarizeアノテーションでPartialAggregation.PARTIALを指定すると部分集約が有効になる。
特に指定しない場合はPARTIALが使われるので、あまり気にしなくて良い。
import com.asakusafw.vocabulary.flow.processor.PartialAggregation; import com.asakusafw.vocabulary.operator.Summarize; import com.example.modelgen.dmdl.model.Hoge; import com.example.modelgen.dmdl.model.HogeTotal;
public abstract class ExampleOperator {
/**
* HogeをHogeTotalに集計する
*
* @param hoge
* 集計対象
* @return 集計結果
*/
@Summarize(partialAggregation = PartialAggregation.PARTIAL)
public abstract HogeTotal summarize(Hoge hoge);
}
単純集計演算子で集計した結果を表すデータモデルは、DMDL上で集計モデルとして定義しておく必要がある。
| 例 | 説明 |
|---|---|
summarized total = 〜; |
モデル名の前に「summarized」を付ける。 |
summarized total = hoge => {
〜
};
|
モデル名の「=」の次に集計元となるデータモデル名を指定し、 「=> { }」で集計内容のブロックを作る。 |
summarized total = hoge => {
any key -> id1;
any date -> id2;
sum value -> total_value;
min value -> min_value;
max value -> max_value;
count value -> count_value;
};
|
各プロパティーは、「集計方法 集計元プロパティー名 -> プロパティー名」で記述する。 (ちなみに、「->」の代わりに「=>」でも良い) 集計キーとなる項目は「any」にしておく。 なお、countのデータ型は常にLONGになる。 sumの型は、BYTE・SHORT・INT・LONGはLONG、FLOAT・DOUBLEはDOUBLE、DECIMALはDECIMALになる。 |
summarized total = hoge => {
any key -> id1;
any date -> id2;
sum value -> total_value;
min value -> min_value;
max value -> max_value;
count value -> count_value;
} % id1, id2;
|
「%」の後ろに集計キーを指定する。 (複数ある場合はカンマ区切りで並べる) 集計キーに使うのは、集計モデルでのプロパティー名(「->」の右側で指定した名前)。 |
単純集計演算子(集計モデル)では、平均の算出は対象外となっている。が、いくつかの演算子を組み合わせれば平均を算出することが出来る。[2013-12-30]
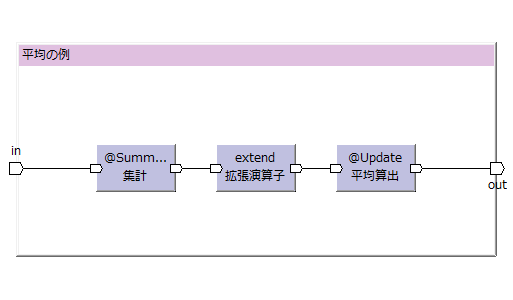
単純集計演算子で件数と合計を算出する集計モデルを生成する。
そこに拡張演算子(extend)で平均値を保持するプロパティーを追加し、更新演算子(@Update)で平均値を入れる。
hoge = {
key : TEXT;
value : INT;
};
summarized hoge_temp = hoge => {
any key -> key;
count value -> count;
sum value -> total;
} % key;
hoge_average = hoge_temp + {
average : DOUBLE;
};
import com.asakusafw.vocabulary.operator.Summarize; import com.asakusafw.vocabulary.operator.Update; import com.example.modelgen.dmdl.model.Hoge; import com.example.modelgen.dmdl.model.HogeAverage; import com.example.modelgen.dmdl.model.HogeTemp;
public abstract class AverageOperator {
/**
* 集計
*
* @param in
* 入力
* @return 集計結果
*/
@Summarize
public abstract HogeTemp summarize(Hoge in);
/**
* 平均算出
*
* @param in
* 入力
*/
@Update
public void update(HogeAverage in) {
in.setAverage((double) in.getTotal() / in.getCount());
}
}
import com.asakusafw.vocabulary.flow.FlowDescription; import com.asakusafw.vocabulary.flow.FlowPart; import com.asakusafw.vocabulary.flow.In; import com.asakusafw.vocabulary.flow.Out; import com.asakusafw.vocabulary.flow.util.CoreOperatorFactory; import com.asakusafw.vocabulary.flow.util.CoreOperatorFactory.Extend; import com.example.modelgen.dmdl.model.Hoge; import com.example.modelgen.dmdl.model.HogeAverage; import com.example.operator.AverageOperatorFactory; import com.example.operator.AverageOperatorFactory.Summarize; import com.example.operator.AverageOperatorFactory.Update;
@FlowPart
public class AverageFlowPart extends FlowDescription {
/** 入力 */
private final In<Hoge> in;
/** 出力 */
private final Out<HogeAverage> out;
public AverageFlowPart(In<Hoge> in, Out<HogeAverage> out) {
this.in = in;
this.out = out;
}
@Override
public void describe() {
AverageOperatorFactory averageOperator = new AverageOperatorFactory();
CoreOperatorFactory core = new CoreOperatorFactory();
// 集計
Summarize summarize = averageOperator.summarize(this.in);
// 拡張演算子
Extend<HogeAverage> extend = core.extend(summarize.out, HogeAverage.class);
// 平均算出
Update update = averageOperator.update(extend.out);
this.out.add(update.out);
}
}
単純集計演算子は、SQLのGROUP BYに相当する。
INSERT INTO total (id1, id2, total_value, min_value, max_value, count_value) SELECT key, date, SUM(value), MIN(value), MAX(value), COUNT(value) FROM hoge GROUP BY key, date;
ただし、SQLでは集計対象項目がNULLだったら集計対象外になるが、AsakusaFWではNullPointerExceptionになる。