分布関数(一次元)
Xは「連続型」、 X (もしくはPX) の「確率密度関数(Probibility Density Function)」fx: R1→[0,∞]が存在して、
for ∀x∈R1
となるとき、
X ( P x )を連続型確率変数
Fを絶対連続な分布関数(→柳川p16)といい、
f(・)をX ( P x )の確率密度関数(pdf)という。
※
(1)の右辺はルベーク式積分によって定義されるのだが、
ルベーク積分の知識がないなら、
fxの広義積分
![]()
を表すと考えて差し支えない。
(
野田・宮岡『数理統計学の基礎』p.22)(ii)
(証明)
(i)確率密度関数の定義と、分布関数の性質から。(柳川p.16)
(ii)
![]()
=1 ∵
分布関数の性質(i) fx の連続点xで、
F ' X(x)=fX(x)
(ii)
※ 略記法
{ω∈Ω| a<X(ω)≦b}は{ a<X≦b }
{ω∈Ω| X (ω)∈B}は{ X∈B }
などと略記される。
野田・宮岡『数理統計学の基礎』p15.
(証明)
(i) 微積分学の基本定理から。 (柳川p16)
(ii)
P (a<X≦b)= P ({ω∈Ω| a<X(ω)≦b})=FX(b)-FX(a)
∵
定理: P ( {ω∈Ω| a<X(ω)≦b } )=Fx(b)-Fx (a) ![]() ∵確率密度関数の定義
∵確率密度関数の定義
![]() ∵
∵
(exponential distribution)
鈴木・山田『数理統計学―基礎から学ぶデータ解析―(第二版)』pp. 112-113。
・密度関数
![]()
fx(x)= 0 (x<0)
・グラフ
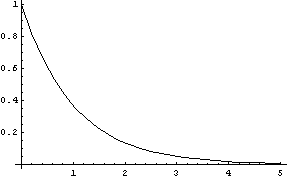
(鈴木・山田p.112)」・「記憶喪失性(『統計数学』pp.88-89)」
P ( X > x+h | X > x ) = P (X≧h)
for ∀x, h>0
※ 略記法
{ω∈Ω| a<X(ω)≦b}は{ a<X≦b }
{ω∈Ω| X (ω)∈B}は{ X∈B }
などと略記される。
野田・宮岡『数理統計学の基礎』p15.
(解釈)
(証明)
左辺:
P ( X > x+h | X > x )=P ( {ω∈Ω| X(ω) > x+h } | {ω∈Ω| X(ω) > x } ) (略記法から戻す)=
P ( {ω∈Ω| X(ω) > x+h }∩{ω∈Ω| X(ω) > x } ) /P ( {ω∈Ω| X(ω) > x })∵
条件付確率の定義 P(A|B) ≡ P (A∩B) / P(B)=
P ( {ω∈Ω| X(ω) > x+h } ) /P ({ω∈Ω| X(ω) > x } )=
[1-P ( {ω∈Ω| X(ω) > x+h } C ) ] / [ P ({ω∈Ω| X(ω) > x } C ) ]∵
余事象の確率:P(Ac)=1-P(A)=
[ 1-P ( {ω∈Ω| X(ω) ≦ x+h } ) ] / [ 1-P ({ω∈Ω| X(ω) ≦ x } ) ]=
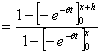
[ 1-FX ( x+h ) ]/[ 1-FX ( x ) ] ∵分布関数の定義 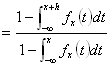 ∵
∵
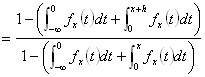
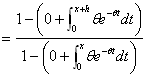 ∵
∵
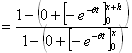
![]()
![]()
![]()
![]()
右辺:
P (X≧h) =P ( {ω∈Ω| X(ω) ≧ h } ) (略記法から戻す)= P ( {ω∈Ω| X(ω) > h } ∪ {ω∈Ω| X(ω) = h })
= P ( {ω∈Ω| X(ω) > h } )+P ( {ω∈Ω| X(ω) = h } )
∵排反なので
確率の公理(P3)より= P ( {ω∈Ω| X(ω) > h } )+P ( {ω∈Ω| X(ω) = h } )
=
1-P ( {ω∈Ω| X(ω) > h } C ) +P ( {ω∈Ω| X(ω) = h } )∵
余事象の確率:P(Ac)=1-P(A)=
1-P ( {ω∈Ω| X(ω) ≦ h } ) +P ( {ω∈Ω| X(ω) = h } )=
1-FX ( h )+0 ∵分布関数の定義 ![]() ∵
∵
![]()
![]()
![]()
![]()
∴
P ( X > x+h | X > x )=P (X≧h)(
reference)文献
1.『岩波数学辞典(第三版)』項目47C(p.128).文献
2. 佐藤坦『はじめての確率論 測度から確率へ』共立出版、1994、p.28;101.文献
3. 鈴木武・山田作太郎『数理統計学―基礎から学ぶデータ解析―(第二版)』内田老鶴圃、1998年、pp.27-26; 112-113。文献
4. 柳川堯『統計数学』近代科学社、1990年,pp.16-17; 18-19.文献
5. 野田一雄・宮岡悦良『数理統計学の基礎』共立出版、1992年、pp.22-24 。