Asakusa Framework0.10.0でFizz Buzzを作ってみる。
AsakusaFW 0.10.0のAsakusa VanillaでFizz Buzzを作ってみる。
数値が入ったファイルを入力とし、その数値をFizz Buzzに変換したファイルを出力する。
1 2 3 4 5 6 7 8 9 10
↓実行結果
1,1 2,2 3,Fizz 4,4 5,Buzz 6,Fizz 7,7 8,8 9,Fizz 10,Buzz
Asakusa Vanillaはpure Javaの実行環境なので、Windowsでも実行できる。
→実行例
一番最初に、Eclipseで扱えるFizz Buzz用プロジェクトを作成する。(Shafuの新規プロジェクト作成機能を使用する)
D:/temp/asakusa」apply plugin: 'asakusafw-m3bp' ↓ apply plugin: 'asakusafw-vanilla'
最初に、入力データ・出力データを表すクラス(モデル)を作成する。
モデルはdmdlというファイルに定義を書き、モデルジェネレーターによってJavaソースに変換される。
入力ファイル・出力ファイルの一行分のデータ構造をDMDL(Data Model Definition Language)という言語で記述する。(JSONぽい感じ。見ればすぐ分かる)
このDMDLファイル内にはまずモデル名を書くが、これがクラス名に変換される。
モデル名はファイル名と異なっていてもいいし、1つのファイル内に複数のモデルを書いてもよい。
ダブルクォーテーションで囲んだ部分が、JavaソースのJavadocコメントになる。
参考: Asakusa FrameworkのDMDLユーザーガイド
ここではmodels.dmdlというファイルを作成し、データモデルを記述する。
今回のFizz Buzzでは、入力が数値(number)、出力は数値(number)と変換後のFizzBuzz文字列(fizz_buzz)。
"数値モデル"
@directio.csv
number_model = {
"数値"
number : LONG;
};
"FizzBuzzモデル"
@directio.csv
fizz_buzz_model = {
"数値"
number : LONG;
"FizzBuzz"
fizz_buzz : TEXT;
};
「@directio.csv」というのは、そのデータモデルをDirect I/OのCSVファイルとして扱うという印。
ちなみに、今回の出力ファイルは入力ファイルにfizz_buzz項目を追加しているので、そういう形式で書くことも出来る。
"FizzBuzzモデル"
@directio.csv
fizz_buzz_model = number_model + {
"FizzBuzz"
fizz_buzz : TEXT;
};
作成したDMDLファイルからデータモデルクラス(Javaソース)を生成する。
また、@directio.csv属性が付いていると、入出力ファイルとしての定義クラス(Importer/Exporterの抽象クラス)も生成されるようになる。(ジョブフローの作成時に関係してくる)
Shafuを使う場合は以下のようにして生成する。
あるいは、DMDL EditorXを使う場合は以下のようにする。
次に、オペレーター(演算子)を作成する。
オペレーターは実際の処理(データ変換)を記述する。
オペレーター用のクラスを用意し、その中にメソッドを定義して処理を記述していく。(このメソッドは、実行時に実際に呼ばれる)
メソッドには、どのような処理を行うかに応じてAsakusa Frameworkで用意されているアノテーションを付ける必要がある。
そして、アノテーションの種類(というか処理の種類)によって、メソッドの書き方(引数や戻り値など)が変わってくる。
オペレーターはJavaの抽象クラス内に定義する決まりになっているので、最初に空のクラスを作る。
package com.example.operator;
public abstract class FizzBuzzOperator {
}
入力データ(NumberModel)を出力データ(FizzBuzzModel)に変換するので、Convert演算子を使う方法が考えられる。
(→オペレーターにUpdate演算子を使う例)
package com.example.operator; import com.asakusafw.vocabulary.operator.Convert; import com.example.modelgen.dmdl.model.FizzBuzzModel; import com.example.modelgen.dmdl.model.NumberModel;
public abstract class FizzBuzzOperator {
private final FizzBuzzModel fizzBuzzModel = new FizzBuzzModel();
@Convert
public FizzBuzzModel convertFizzBuzz(NumberModel in) {
long number = in.getNumber();
FizzBuzzModel result = this.fizzBuzzModel;
result.reset(); // 初期化
result.setNumber(number);
result.setFizzBuzzAsString(getFizzBuzz(number));
return result;
}
private String getFizzBuzz(long number) {
if (number % 3 == 0) {
if (number % 5 == 0) {
return "FizzBuzz";
}
return "Fizz";
} else if (number % 5 == 0) {
return "Buzz";
}
return Long.toString(number);
}
}
Convert演算子では、入力データモデルを引数で受け取り、変換後のデータモデルを返す。
Convert演算子で返すデータモデルのインスタンスは返した先で保持されるわけではないので、1つだけ作ってフィールドで保持して使い回すことが出来る。(毎回作ると初期化のコストもかかるし、GCの発生頻度も上がってしまう)
オペレーターは通常のJavaのメソッドなので、普通にJUnitでテストすることが出来る。
package com.example.operator; import static org.hamcrest.CoreMatchers.*; import static org.junit.Assert.*; import org.junit.Test; import com.example.modelgen.dmdl.model.FizzBuzzModel; import com.example.modelgen.dmdl.model.NumberModel;
/**
* {@link FizzBuzzOperator}のテスト.
*/
public class FizzBuzzOperatorTest {
@Test
public void testConvertFizzBuzz() {
testConvertFizzBuzz(1, "1");
testConvertFizzBuzz(3, "Fizz");
testConvertFizzBuzz(5, "Buzz");
testConvertFizzBuzz(15, "FizzBuzz");
}
private static void testConvertFizzBuzz(long number, String expected) {
FizzBuzzOperator operator = new FizzBuzzOperatorImpl();
NumberModel in = new NumberModel();
in.setNumber(number);
FizzBuzzModel result = operator.convertFizzBuzz(in);
assertThat(result.getNumber(), is(number));
assertThat(result.getFizzBuzzAsString(), is(expected));
}
}
ただし、Operatorクラスは抽象クラスなので、直接はインスタンス化できない。
このために具象クラス(Operatorクラス名に「Impl」が付いたクラス)が生成されているので、これを使う。
(Eclipseで自動的にソースをコンパイルする設定(デフォルトではその状態)になっている場合、Operatorのソースを保存した際にImplクラスが生成される)
次に、ジョブフローを定義する。
ここで「どのファイルを入力とし、どのオペレーターを呼んで、どのファイルへ出力するか」を記述する。
参考: Asakusa FrameworkのAsakusa DSLスタートガイド#データフローを記述する
まずは入力ファイル(Importer)を定義する。
DMDLファイル上のモデル定義に@directio.csvという属性を付けておくと 、DMDLのコンパイルを行った際にImporterの雛形クラス(抽象クラス)が生成されるので、それを継承した具象クラスを作成する。
package com.example.jobflow.port; import com.example.modelgen.dmdl.csv.AbstractNumberModelCsvInputDescription;
public class NumberModelFromCsv extends AbstractNumberModelCsvInputDescription {
@Override
public String getBasePath() {
return "fizzbuzz/input";
}
@Override
public String getResourcePattern() {
return "*.csv";
}
}
number_modelというデータモデルに@directio.csvを付けていた場合、AbstractNumberModelCsvInputDescription(Abstract+モデル名+CsvInputDescription)というクラスが生成されているので、それを使う。
ベースパスやリソースパターンはDirect I/O固有の設定。
ベースパスはディレクトリー名相当、リソースパターンがファイル名。
ベースパスは相対パスっぽい指定になる。具体的にどこになるのかは、実行環境の設定によって変わる。
入力ファイルと同様に、出力ファイル(Exporter)も定義する。
package com.example.jobflow.port; import java.util.Arrays; import java.util.List; import com.example.modelgen.dmdl.csv.AbstractFizzBuzzModelCsvOutputDescription;
public class FizzBuzzModelToCsv extends AbstractFizzBuzzModelCsvOutputDescription {
@Override
public String getBasePath() {
return "fizzbuzz/result";
}
@Override
public String getResourcePattern() {
return "fizzbuzz.csv";
}
@Override
public List<String> getOrder() {
return Arrays.asList("number");
}
}
fizz_buzz_modelというモデル名に@directio.csvを付けていた場合、AbstractFizzBuzzModelCsvOutputDescription(Abstract+モデル名+CsvOutputDescription)というクラスが生成されているので、それを使う。
なお、特に指定しない場合、出力結果の並び順は不定。(AsakusaFWは分散処理するので、その方が効率が良い)
出力のソート順を指定したい場合はgetOrderメソッドでソート項目を指定する。
そして、ジョブフロークラスに「入力→処理→出力のつながり(順序・フロー)」を記述する。
package com.example.jobflow; import com.asakusafw.vocabulary.flow.FlowDescription; import com.asakusafw.vocabulary.flow.JobFlow;
@JobFlow(name = "FizzBuzzJob")
public class FizzBuzzJob extends FlowDescription {
}
JobFlowというアノテーションを付け、ジョブ名を指定する。
クラス自体はFlowDescriptionを継承する。
ジョブフローでは、コンストラクターで入力データと出力データを受け取る。
それをフィールドで保持しておき、使用する。
import com.asakusafw.vocabulary.flow.Export; import com.asakusafw.vocabulary.flow.Import; import com.asakusafw.vocabulary.flow.In; import com.asakusafw.vocabulary.flow.Out; import com.example.jobflow.port.FizzBuzzModelToCsv; import com.example.jobflow.port.NumberModelFromCsv; import com.example.modelgen.dmdl.model.FizzBuzzModel; import com.example.modelgen.dmdl.model.NumberModel;
private final In<NumberModel> numberIn;
private final Out<FizzBuzzModel> fizzBuzzOut;
public FizzBuzzJob(
@Import(name = "number", description = NumberModelFromCsv.class) In<NumberModel> numberIn,
@Export(name = "fizzBuzz", description = FizzBuzzModelToCsv.class) Out<FizzBuzzModel> fizzBuzzOut
) {
this.numberIn = numberIn;
this.fizzBuzzOut = fizzBuzzOut;
}
FlowDescriptionのdescribeメソッドをオーバーライドし、フロー(Flow DSL)を記述する。
import com.asakusafw.vocabulary.flow.util.CoreOperators; import com.example.operator.FizzBuzzOperatorFactory; import com.example.operator.FizzBuzzOperatorFactory.ConvertFizzBuzz;
@Override
protected void describe() {
FizzBuzzOperatorFactory operator = new FizzBuzzOperatorFactory();
ConvertFizzBuzz c = operator.convertFizzBuzz(numberIn);
CoreOperators.stop(c.original);
fizzBuzzOut.add(c.out);
}
Operatorクラスをコーディングすると、OperatorFactoryクラス(Operatorクラス名に「Factory」が付いたクラス)が生成される。
(Eclipseで自動的にソースをコンパイルする設定(デフォルトではその状態)になっている場合、Operatorのソースを保存した際にFactoryクラスが生成される)
Flow DSL(フローの記述)ではOperatorFactoryクラスを使用する。
operator.convertFizzBuzz()が、自分で作ったオペレーターを表している。
Convert演算子の場合、変換後のデータと変換前のデータがペアで返される。
今回は(というかほとんどのケースでは)変換前データは不要なので、stop演算子に渡す。
(AsakusaFWでは、演算子から出力されたデータは必ずどこかに渡す必要がある。出力したデータを使わない(不要な)場合はstop演算子に渡す。stop演算子に渡したデータは無視される(捨てられる)
ことになる)
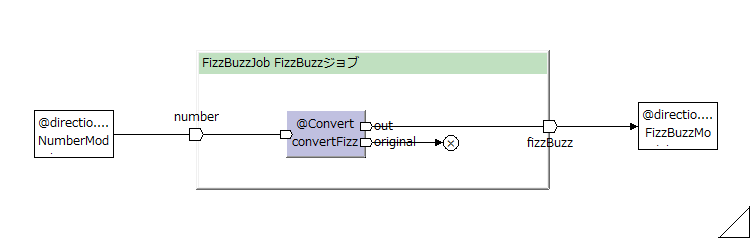
※このdescribeメソッドはAsakusaFWがジョブフローをコンパイルする際に実行される(実行することによってフロー(グラフ)を作成している)。
→ジョブフローのグラフ化(可視化)
このFizzBuzzJobは、概念的には以下のような図(フローグラフ)になる。
※この図は、Toad Editorにて、FizzBuzzJobクラスから生成
AsakusaFWでは、ジョブフロー(やFlowPart・バッチ)のテスト用クラスが用意されている。
それらを使ってJUnit4として実行できる。
(AsakusaFW 0.10.0では、フローのテストの実行にはAsakusa Vanillaが使われる)
フローのテストを行う場合はAsakusaFWの実行環境が必要なので、作っていない場合は作成する。
Shafuを使ってAsakusaFWの実行環境を作成する。
D:/temp/asakusa」パッケージエクスプローラー上でジョブフロークラスのソース(FizzBuzzJob)を右クリックして、「新規(W)」→「JUnitテスト・ケース」でJUnit4のテスト用クラスを作成する。
その際、作成先のディレクトリーは「afw-fizzbuzz/src/test/java」とする。
package com.example.jobflow; import org.junit.Test; import com.asakusafw.testdriver.JobFlowTester; import com.asakusafw.testdriver.core.PropertyName; import com.example.modelgen.dmdl.model.FizzBuzzModel; import com.example.modelgen.dmdl.model.NumberModel;
/**
* {@link FizzBuzzJob}のテスト。
*/
public class FizzBuzzJobTest {
static {
System.setProperty(PropertyName.KEY_SEGMENT_SEPARATOR, "_");
}
@Test
public void describe() {
JobFlowTester tester = new JobFlowTester(getClass());
tester.input("number", NumberModel.class).prepare("FizzBuzzJobTest.xls#number");
tester.output("fizzBuzz", FizzBuzzModel.class).verify("FizzBuzzJobTest.xls#fizzBuzz", "FizzBuzzJobTest.xls#fizzBuzz_rule");
tester.runTest(FizzBuzzJob.class);
}
}
ジョブフローのテストではJobFlowTesterを使用する。
tester.input()で入力データを指定する。
第1引数はジョブフローで指定した入力データの名前。つまりFizzBuzzJobのコンストラクターの「@Import(name = "number"」。
この名前を使って入力データのファイル名を取得しているようだ。(一致しているものが無いと、入力ファイルを作れない)
そのinputメソッドの後に続いているprepare()で、入力データのExcelファイル名(FizzBuzzJobTest.xls)とシート名を指定する。
tester.output()もtester.input()と同様。
第1引数はジョブフローの出力データの名前「@Export(name = "fizzBuzz"」。検証時にこの名前を使ってデータを取得するようだ。(一致しているものが無いと、実行が終わった後のチェックでエラーになる)
verifyメソッドの第1引数が出力データのExcelファイル名(とシート名)、第2引数がチェック用ルールのExcelファイル名(とシート名)。
ジョブフローのテストで使用するテストデータをExcelファイル(またはその他の方式で)で用意する必要がある。
参考: Asakusa FrameworkのExcelによるテストデータ定義
DMDLをコンパイルして(Javaソースの他に) デーモデル毎のExcelファイルが生成させることが出来る。
Shafuの「テストデータ・テンプレートを作成」を実行するとafw-fizzbuzz/build/excelの下にExcelファイルが生成されるので、それを 自分のテスト用Excelファイルにコピーし、その中にデータを記述する。
| A | B | C | |
| 1 | number | ||
| 2 | 1 | ||
| 3 | 3 | ||
| 4 | 5 | ||
| 5 | 15 | ||
| 6 |
入力データを書く。
1行目(色付きのセル)は自動で入っている。
| A | B | C | |
| 1 | number | fizz_buzz | |
| 2 | 1 | 1 | |
| 3 | 3 | Fizz | |
| 4 | 5 | Buzz | |
| 5 | 15 | FizzBuzz | |
| 6 |
期待される出力データ(期待値データ)を書く。
1行目(色付きのセル)は自動で入っている。
fizz_buzz項目は文字列なので、セルにも文字列で入力しなければならない。
文字列項目に数値を入力する場合は、先頭にアポストロフィーを付けて「'1」のように記入する。
| A | B | C | D | E | F | |
| 1 | Format | EVR-2.0.0 | ||||
| 2 | 全体の比較 | 全てのデータを検査 [Strict] | ||||
| 3 | プロパティ | 値の比較 | NULLの比較 | コメント | オプション | |
| 4 | number | 検査キー [Key] | 通常比較 [-] | 数値 | ||
| 5 | fizz_buzz | 完全一致 [=] | 通常比較 [-] | FizzBuzz | ||
| 6 |
期待値データと実行結果データをどう比較してどういう状態ならテストOK(あるいはNG)とするかをruleシートに書く。
どのセルも初期値は自動で入っている。
今回のケースでは出力項目がnumberとfizz_buzzの2項目なので、それぞれどういう比較をするかを書く。(書くというか、実際はプルダウンになっているので、選択する)
→Excelファイルを使用せず、独自のデータを入力データにする方法
ジョブフローのテストクラスはJUnitから普通に実行できる。
テストを実行すると(AsakusaFW 0.10.0では)Asakusa Vanillaが動き、コンソールに以下のようなログが出力される。
(先頭に出ているERRORは無視してよい。(WindowsのHadoopでwinutilsが見つからない場合に出るものだが、AsakusaFWは独自のwinutils.を使用するので問題ない))
20:38:43 ERROR Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries. at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:379) 〜 at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.main(RemoteTestRunner.java:192) 20:38:43 INFO installing winutils.exe into default location: C:\Users\HISHID~1\AppData\Local\Temp\winutils-hishidama.exe 20:38:43 INFO winutils.exe is successfully installed: C:\Users\HISHID~1\AppData\Local\Temp\winutils-hishidama.exe 20:38:43 INFO Hadoop configuration path is not found 20:38:43 INFO テストを開始しています: com.example.jobflow.FizzBuzzJobTest 20:38:43 INFO テスト条件を検証しています: com.example.jobflow.FizzBuzzJobTest 20:38:44 INFO Excelシートをデータソースに利用します: file:/D:/workspace/afw-fizzbuzz/bin/com/example/jobflow/FizzBuzzJobTest.xls#number 20:38:44 INFO Excelシートをデータソースに利用します: file:/D:/workspace/afw-fizzbuzz/bin/com/example/jobflow/FizzBuzzJobTest.xls#fizzBuzz 20:38:44 INFO Excelシートをテスト条件に利用します: file:/D:/workspace/afw-fizzbuzz/bin/com/example/jobflow/FizzBuzzJobTest.xls#fizzBuzz_rule 20:38:46 INFO テスト環境を初期化しています: com.example.jobflow.FizzBuzzJobTest 20:38:46 WARN Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 20:38:46 INFO テストデータを配置しています: com.example.jobflow.FizzBuzzJobTest 20:38:46 INFO Excelシートをデータソースに利用します: file:/D:/workspace/afw-fizzbuzz/bin/com/example/jobflow/FizzBuzzJobTest.xls#number 20:38:46 INFO ジョブフローを実行しています: com.example.jobflow.FizzBuzzJob 20:38:46 INFO start jobflow: dummy - FizzBuzzJob 20:38:46 INFO start phase: MAIN (1 tasks) 20:38:46 INFO DAG starting: {user=hishidama, batch=dummy, flow=FizzBuzzJob, stage=N/A, execution=FizzBuzzJobTest-a57fbf5a-3875-48d8-b6ef-f8ea4c19938b, arguments={}}, vertices=4 20:38:46 INFO start graph: vertices=4 20:38:46 INFO finish vertex: DirectFileOutputSetup(1) (_directio-setup) in 13ms 20:38:47 INFO finish vertex: ExternalInput(number) (v0) in 59ms 20:38:47 INFO finish vertex: DirectFileOutputPrepare(Spec(id=fizzBuzz, basePath=fizzbuzz/result)) (v1) in 81ms 20:38:47 INFO finish vertex: DirectFileOutputCommit(1) (_directio-commit) in 141ms 20:38:47 INFO finish graph: vertices=4, elapsed=391ms 20:38:47 INFO DAG finished: {user=hishidama, batch=dummy, flow=FizzBuzzJob, stage=N/A, execution=FizzBuzzJobTest-a57fbf5a-3875-48d8-b6ef-f8ea4c19938b, arguments={}}, vertices=4, elapsed=425ms 20:38:47 INFO Direct I/O file input: 1 entries 20:38:47 INFO number: 20:38:47 INFO number of input records: 4 20:38:47 INFO input file size in bytes: 13 20:38:47 INFO (TOTAL): 20:38:47 INFO number of input records: 4 20:38:47 INFO input file size in bytes: 13 20:38:47 INFO Direct I/O file output: 1 entries 20:38:47 INFO fizzBuzz: 20:38:47 INFO number of output records: 4 20:38:47 INFO output file size in bytes: 34 20:38:47 INFO (TOTAL): 20:38:47 INFO number of output records: 4 20:38:47 INFO output file size in bytes: 34 20:38:47 INFO finish jobflow: dummy - FizzBuzzJob 20:38:47 INFO 実行結果を検証しています: com.example.jobflow.FizzBuzzJobTest 20:38:47 INFO Excelシートをデータソースに利用します: file:/D:/workspace/afw-fizzbuzz/bin/com/example/jobflow/FizzBuzzJobTest.xls#fizzBuzz 20:38:47 INFO Excelシートをテスト条件に利用します: file:/D:/workspace/afw-fizzbuzz/bin/com/example/jobflow/FizzBuzzJobTest.xls#fizzBuzz_rule
最後にBatch DSLで「どのジョブフローを実行するか」を記述する。
(ひとつのバッチの中で複数のジョブフローを実行するように記述できるのだが、実際のところ、そういう書き方をすることは滅多に無い)
参考: Asakusa FrameworkのAsakusa DSLスタートガイド#バッチを記述する
package com.example.batch; import com.asakusafw.vocabulary.batch.Batch; import com.asakusafw.vocabulary.batch.BatchDescription; import com.example.jobflow.FizzBuzzJob;
/**
* FizzBuzzバッチ
*/
@Batch(name = "FizzBuzzBatch", comment = "FizzBuzzバッチ")
public class FizzBuzzBatch extends BatchDescription {
@Batchアノテーションのnameで付けた名前が、バッチを実行するとき(asakusa runコマンド)に指定する名前となる。
(個人的には、クラス名と同じ名前にしておく方が分かりやすいと思う)
@Batchアノテーションのcommentでバッチの日本語名を付けておくと、asakusa listコマンドで表示される。
@Override
public void describe() {
run(FizzBuzzJob.class).soon();
}
}
describeメソッドをオーバーライドし、どのジョブフローを実行するかを記述する。
実行するジョブのClassをrun()で指定し、soon()で「すぐ(前提条件が無いので最初に)実行する」という意味になる。
バッチまでプログラミングが完成したら、実行環境にデプロイ(配備)することで、バッチを実行することが出来る。
→運用環境の構築
Asakusa Vanillaなら、開発環境(Windows)上で実行することも簡単に出来る。
Shafuを使ってバッチアプリケーションを開発環境上にデプロイすることが出来る。
Windowsのコマンドプロンプトから(asakusaコマンドで)バッチがインストールされた事を確認できる。
> path %PATH%;%ASAKUSA_HOME%\bin
> asakusa list batch -v
vanilla.FizzBuzzBatch:
class: com.example.batch.FizzBuzzBatch
comment: FizzBuzzバッチ
@Batchアノテーションのnameに「FizzBuzzBatch」と指定している場合、Asakusa Vanilla用のバッチIDは「vanilla.FizzBuzzBatch」となる。
Windowsのコマンドプロンプトから(asakusaコマンドで)バッチを実行することが出来るのだが、入出力ファイルのパスだけ設定する必要がある。
〜 <property> <name>com.asakusafw.directio.root.fs.path</name> <value>D:/temp/directio</value> </property> 〜
root.fs.pathで入出力ファイルのディレクトリーを設定する。
「D:/temp/directio」とした場合、Importerのベースパス「fizzbuzz/input」・リソースパターン「*.csv」を合わせて「D:/temp/directio/fizzbuzz/input/*.csv」が読み込まれ、
出力先はExporterのベースパス「fizzbuzz/result」・リソースパターン「fizzbuzz.csv」と合わせて「D:/temp/directio/fizzbuzz/result/fizzbuzz.csv」となる。
入力データの例。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Windowsのコマンドプロンプトからasakusa runコマンドでバッチを実行できる。
@Batchアノテーションのnameに「FizzBuzzBatch」と指定している場合、Asakusa Vanilla用のバッチIDは「vanilla.FizzBuzzBatch」となる。
> path %PATH%;%ASAKUSA_HOME%\bin
> asakusa run vanilla.FizzBuzzBatch
21:20:10 INFO DAG starting: {user=hishidama, batch=vanilla.FizzBuzzBatch, flow=FizzBuzzJob, stage=N/A, execution=96b8216b-0da3-4b36-a66a-0f4d76850f42, arguments={}}, vertices=4
21:20:10 INFO start graph: vertices=4
21:20:10 INFO finish vertex: DirectFileOutputSetup(1) (_directio-setup) in 21ms
21:20:10 INFO finish vertex: ExternalInput(number) (v0) in 285ms
21:20:10 INFO finish vertex: DirectFileOutputPrepare(Spec(id=fizzBuzz, basePath=fizzbuzz/result)) (v1) in 79ms
21:20:10 INFO finish vertex: DirectFileOutputCommit(1) (_directio-commit) in 123ms
21:20:10 INFO finish graph: vertices=4, elapsed=532ms
21:20:10 INFO DAG finished: {user=hishidama, batch=vanilla.FizzBuzzBatch, flow=FizzBuzzJob, stage=N/A, execution=96b8216b-0da3-4b36-a66a-0f4d76850f42, arguments={}}, vertices=4, elapsed=651ms
21:20:10 INFO Direct I/O file input: 1 entries
21:20:10 INFO number:
21:20:10 INFO number of input records: 20
21:20:10 INFO input file size in bytes: 71
21:20:10 INFO (TOTAL):
21:20:10 INFO number of input records: 20
21:20:10 INFO input file size in bytes: 71
21:20:10 INFO Direct I/O file output: 1 entries
21:20:10 INFO fizzBuzz:
21:20:10 INFO number of output records: 20
21:20:10 INFO output file size in bytes: 148
21:20:10 INFO (TOTAL):
21:20:10 INFO number of output records: 20
21:20:10 INFO output file size in bytes: 148
出力結果は以下の通り。
1,1 2,2 3,Fizz 4,4 5,Buzz 6,Fizz 7,7 8,8 9,Fizz 10,Buzz 11,11 12,Fizz 13,13 14,14 15,FizzBuzz 16,16 17,17 18,Fizz 19,19 20,Buzz
オペレーターにUpdate演算子を使う例。
(→オペレーターにConvert演算子を使う例)
今回の出力のデータモデル(fizz_buzz_model)は入力(number_model)にfizz_buzz項目を追加した形になっている。
こうした場合、extend演算子(「項目が追加されたデータモデル」に変換する演算子)でデータモデルを変換し、追加された項目に対してUpdate演算子で更新するという方法が使える。
package com.example.operator;
import com.asakusafw.vocabulary.operator.Update;
import com.example.modelgen.dmdl.model.FizzBuzzModel;
public abstract class FizzBuzzOperator {
@Update
public void updateFizzBuzz(FizzBuzzModel in) {
long number = in.getNumber();
in.setFizzBuzzAsString(getFizzBuzz(number));
}
〜
}
package com.example.operator; import static org.hamcrest.CoreMatchers.*; import static org.junit.Assert.*; import org.junit.Test; import com.example.modelgen.dmdl.model.FizzBuzzModel;
/**
* {@link FizzBuzzOperator}のテスト.
*/
public class FizzBuzzOperatorTest {
@Test
public void testUpdateFizzBuzz() {
testUpdateFizzBuzz(1, "1");
testUpdateFizzBuzz(3, "Fizz");
testUpdateFizzBuzz(5, "Buzz");
testUpdateFizzBuzz(15, "FizzBuzz");
}
private static void testUpdateFizzBuzz(long number, String expected) {
FizzBuzzOperator operator = new FizzBuzzOperatorImpl();
FizzBuzzModel in = new FizzBuzzModel();
in.setNumber(number);
operator.updateFizzBuzz(in);
assertThat(in.getFizzBuzzAsString(), is(expected));
}
}
describeメソッドの中(とimport文)以外はConvert演算子を使ったジョブフローと同じ。
〜 import com.asakusafw.vocabulary.flow.Source; import com.asakusafw.vocabulary.flow.util.CoreOperators; 〜 import com.example.operator.FizzBuzzOperatorFactory; import com.example.operator.FizzBuzzOperatorFactory.UpdateFizzBuzz;
@Override
public void describe() {
FizzBuzzOperatorFactory operator = new FizzBuzzOperatorFactory();
Source<FizzBuzzModel> extend = CoreOperators.extend(numberIn, FizzBuzzModel.class);
UpdateFizzBuzz update = operator.updateFizzBuzz(extend);
fizzBuzzOut.add(update.out);
}
このFizzBuzzJobは、概念的には以下のような図(フローグラフ)になる。
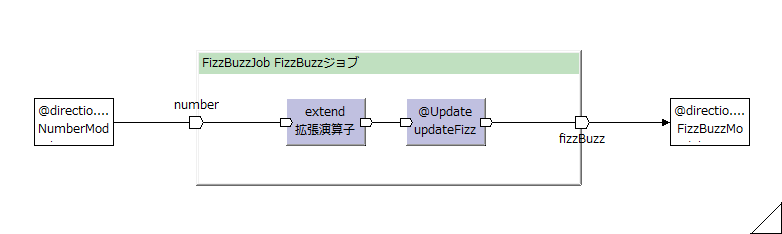
※この図は、Toad Editorにて、FizzBuzzJobクラスから生成
ジョブフローのテストはConvert演算子を使ったジョブフローのテストと全く同じ。(入出力が変わった訳ではないので)