Asakusa Framework0.4のDirect I/Oで偏差値算出処理を作ってみる。[2012-12-19]
Cascadingで作った偏差値算出サンプルと同様の処理をAsakusaFW 0.4のDirect I/Oで作ってみる。
偏差値は以下のような計算式で算出できる。
| A | B | C | D | E | F | G | H | |
| 1 | student_id | student_name | suugaku | kokugo | rika | shakai | eigo | |
| 2 | 101 | 天才 | 100 | 100 | 100 | 100 | 100 | |
| 3 | 201 | 無気力 | 5 | 30 | 10 | 20 | 15 | |
| 4 | 102 | ひしだま | 90 | 85 | 80 | 50 | 10 | |
| 5 | 202 | hoge | 10 | 30 | 25 | 45 | 20 | |
| 6 | 103 | foo | 60 | 60 | 60 | 60 | 25 | |
| 7 | 204 | xxx | 80 | 77 | 90 | 40 | 44 | |
| 8 | 205 | yyy | 65 | 90 | 55 | 80 | 65 | |
| 9 | 104 | zzz | 40 | 60 | 60 | 70 | 20 | |
| 10 |
AsakusaFW用プロジェクトの作成方法はWordCountの例と同じ。
> mvn archetype:generate -DarchetypeCatalog=http://asakusafw.s3.amazonaws.com/maven/archetype-catalog-0.4.xml
| アーキタイプ | asakusa-archetype-directio |
| AsakusaFWのversion | 0.4.0 |
| groupId | afw-score |
| artifactId | afw-score |
| プロジェクトのversion | 1.0-SNAPSHOT |
| package | example |
最初にモデルを作成する。
偏差値算出で使うデータの流れに沿ってデータモデルを準備していく。
| コード | 説明 | 備考 |
|---|---|---|
"成績表" @directio.csv ten_model = { "学生番号" student_id : TEXT; "学生名" student_name : TEXT; suugaku : INT; kokugo : INT; rika : INT; shakai : INT; eigo : INT; }; |
入力データのモデル。 | |
"学生・科目毎の成績" kamoku_model = { "学生番号" student_id : TEXT; "学生名" student_name : TEXT; "科目" kamoku_id : INT; "点数" ten : INT; }; |
入力データを科目毎に分解したモデル。 科目名でなく科目IDを使うことにする。 0:数学、1:国語、2:理科、3:社会、4:英語、5:合計 |
行う演算はどの科目も同じなので、科目毎に分解せず同時に処理していくロジックも考えられるが、 今までの(AsakusaFW以外の)偏差値算出サンプルでもこのように処理してきたので、 今回もそれを踏襲する。 |
"科目毎の点数の合計" summarized kamoku_total = kamoku_model => { any kamoku_id -> kamoku_id; sum ten -> ten; count student_id -> count; } % kamoku_id; |
科目毎に平均点・人数を出す為のモデル。 集計モデルsummarizedを使用。 |
|
"科目毎の平均点" average_model = kamoku_total + { average : DOUBLE; }; |
科目毎の平均点を保持するモデル。 kamoku_totalに平均点項目を追加する形式。 |
集計モデルのDSLにはsum・count・max・minはあるのだが、 平均は無いので自分で計算する必要がある。 |
"学生・科目毎の点数と平均点" joined kamoku_average = kamoku_model -> { kamoku_id -> kamoku_id; ten -> ten; } % kamoku_id + average_model -> { kamoku_id -> kamoku_id; count -> count; average -> average; } % kamoku_id; |
科目毎の点数と平均点を結合。 | |
kamoku_average_sigma = kamoku_average + { sigma_element : DOUBLE; }; |
sigma_element = (ten - average)2 | |
"科目毎の標準偏差の合計" summarized sigma_total = kamoku_average_sigma => { any kamoku_id -> kamoku_id; any average -> average; any count -> count; sum sigma_element -> sigma_sum; } % kamoku_id; |
||
"科目毎の標準偏差" sigma_model = { kamoku_id : INT; average : DOUBLE; sigma : DOUBLE; }; |
科目毎の標準偏差を保持するモデル。 | このモデルを使って偏差値を計算する都合上、 平均点も一緒に持つことにする。 |
"科目毎の点数と標準偏差" joined kamoku_sigma = kamoku_model % kamoku_id + sigma_model % kamoku_id; |
科目毎の点数と標準偏差を結合。 | |
"学生・科目毎の偏差値" @directio.csv score_model = kamoku_model + { "科目名" kamoku_name : TEXT; "平均点" average : DOUBLE; "偏差値" score : DOUBLE; }; |
最終的な偏差値を保持するモデル。 |
次にオペレーター(演算子)を作成する。
package example.operator; mport com.asakusafw.runtime.core.Result; import com.asakusafw.vocabulary.operator.Convert; import com.asakusafw.vocabulary.operator.Extract; import com.asakusafw.vocabulary.operator.MasterJoin; import com.asakusafw.vocabulary.operator.Summarize; import example.modelgen.dmdl.model.AverageModel; import example.modelgen.dmdl.model.KamokuAverage; import example.modelgen.dmdl.model.KamokuAverageSigma; import example.modelgen.dmdl.model.KamokuModel; import example.modelgen.dmdl.model.KamokuSigma; import example.modelgen.dmdl.model.KamokuTotal; import example.modelgen.dmdl.model.ScoreModel; import example.modelgen.dmdl.model.SigmaModel; import example.modelgen.dmdl.model.SigmaTotal; import example.modelgen.dmdl.model.TenModel;
public abstract class ScoreOperator {
| コード | 説明 | 備考 |
|---|---|---|
/** * 科目毎の成績に分割 */ @Extract public void split(TenModel tm, Result<KamokuModel> out) { out.add(createKamoku(tm, 0, ten.getSuugaku())); out.add(createKamoku(tm, 1, ten.getKokugo())); out.add(createKamoku(tm, 2, ten.getRika())); out.add(createKamoku(tm, 3, ten.getShakai())); out.add(createKamoku(tm, 4, ten.getEigo())); out.add(createKamoku(tm, 5, ten.getSuugaku() + ten.getKokugo() + ten.getRika() + ten.getShakai() + ten.getEigo())); } private KamokuModel km = new KamokuModel(); private KamokuModel createKamoku(TenModel tm, int kamoku_id, int ten) { km.setStudentId(tm.getStudentId()); km.setStudentName(tm.getStudentName()); km.setKamokuId(kamoku_id); km.setTen(ten); return km; } |
入力データを科目毎に分割する処理。 5教科合計もここで作成する。 |
|
/** * 科目毎の合計点を算出 */ @Summarize public abstract KamokuTotal sumKamoku(KamokuModel kamoku); |
点数の合計と人数をカウントする処理。 | どの項目を合算し、どの項目をカウントするのかは DMDLの方で記述してある。 |
private AverageModel am = new AverageModel(); /** * 科目毎の平均点を算出 */ @Convert public AverageModel averageKamoku(KamokuTotal kamoku) { am.setKamokuId(in.getKamokuId()); am.setTen(in.getTen()); am.setCount(in.getCount()); am.setAverage((double) in.getTen() / in.getCount()); return am; } |
平均点を計算する処理。 引数として合計点数と人数を受け取っている。 |
平均点以外の項目は移送しているだけだが DMDL上はkamoku_totalの項目をaverage_modelが継承しているので データ移送のメソッドが用意されたりすると便利そうなんだが。 |
/** * 科目毎の点数と平均点を結合 * * @param am 平均点(マスター) * @param km 学生・科目毎の点数 * @return */ @MasterJoin public abstract KamokuAverage joinKamokuAverage(AverageModel am, KamokuModel km); |
各学生の点数レコードと平均点レコードを結合する。 | 第1引数のデータモデルがマスターとなる。 |
private KamokuAverageSigma kas = new KamokuAverageSigma(); @Convert public KamokuAverageSigma convertSigmaElement(KamokuAverage in) { kas.setKamokuId(in.getKamokuId()); kas.setTen(in.getTen()); kas.setCount(in.getCount()); kas.setAverage(in.getAverage()); kas.setSigmaElement(Math.pow(in.getTen() - in.getAverage(), 2)); return kas; } |
標準偏差の合算用の値を算出する。 | |
/** * 科目毎の標準偏差の合算 */ @Summarize public abstract SigmaTotal sumSigma(KamokuAverageSigma in); |
||
private SigmaModel sigma = new SigmaModel(); /** * 科目毎の標準偏差を算出 * * @param in * @return */ @Convert public SigmaModel convertSigma(SigmaTotal in) { sigma.setKamokuId(in.getKamokuId()); sigma.setAverage(in.getAverage()); sigma.setSigma(Math.sqrt(in.getSigmaSum() / in.getCount())); return sigma; } |
標準偏差を算出する処理。 | |
/** * 科目毎の点数と標準偏差を結合 * * @param sm 標準偏差(マスター) * @param km 学生・科目毎の点数 * @return */ @MasterJoin public abstract KamokuSigma joinKamokuSigma(SigmaModel sm, KamokuModel km); |
各学生の点数レコードと標準偏差レコードを結合する。 | 第1引数のデータモデルがマスターとなる。 |
static final String 科目名[] = {
"数学", "国語", "理科", "社会", "英語", "合計"
};
private ScoreModel score = new ScoreModel();
/** * 学生・科目毎の偏差値を算出 */ @Convert public ScoreModel convertScore(KamokuSigma in) { score.setStudentId(in.getStudentId()); score.setStudentName(in.getStudentName()); score.setKamokuId(in.getKamokuId()); score.setKamokuNameAsString(科目名[in.getKamokuId()]); score.setTen(in.getTen()); score.setAverage(in.getAverage()); score.setScore((in.getTen() - in.getAverage()) * 10 / in.getSigma() + 50); return score; } |
偏差値を算出する処理。 科目IDから科目名への変換もここで行っている。 |
AsakusaFW 0.2.1(batchapp)で標準偏差算出プログラムを書いたときはCoGroupを使用したが、CoGroupは最適化の妨げとなるので、あまり推奨されていない。
今回はMasterJoinとSummarize・Convertに置き換えた。
コーディングはちょっと面倒になったが、生成されるMapReduceが最適化されるなら、その方が良い。
入出力ファイルのファイル名を記述するクラスを作成する。
| 入力ファイル | 出力ファイル |
|---|---|
| afw-score/src/main/java/example/jobflow/ TenFromCsv.java |
afw-score/src/main/java/example/jobflow/ ScoreToCsv.java |
package example.jobflow; import example.modelgen.dmdl.csv.AbstractTenModelCsvInputDescription; |
package example.jobflow; import example.modelgen.dmdl.csv.AbstractScoreModelCsvOutputDescription; |
/** * 成績表ををDirect I/Oで入力する。 */ public class TenFromCsv extends AbstractTenModelCsvInputDescription { @Override public String getBasePath() { return "input"; } @Override public String getResourcePattern() { return "ten.csv"; } @Override public DataSize getDataSize() { return DataSize.LARGE; } } |
/** * 偏差値をDirect I/Oで出力する。 */ public class ScoreToCsv extends AbstractScoreModelCsvOutputDescription { @Override public String getBasePath() { return "result"; } @Override public String getResourcePattern() { return "score.csv"; } } |
DMDLで「@directio.csv」アノテーションを付けると、Abstract
InputDescription/OutputDescriptionクラスが自動生成される。
ファイル名を記述するクラスでは、Descriptionクラスを継承してファイル名部分を記述する。
入力ファイルではデータサイズを指定できる。
特に、小さなマスターである場合はTINYやSMALLを指定する。そうすると、最適化によってサイドデータとして扱ってくれる可能性がある。
オペレーターを組み合わせてジョブを作成する。
package example.jobflow;
import com.asakusafw.vocabulary.flow.Export; import com.asakusafw.vocabulary.flow.FlowDescription; import com.asakusafw.vocabulary.flow.Import; import com.asakusafw.vocabulary.flow.In; import com.asakusafw.vocabulary.flow.JobFlow; import com.asakusafw.vocabulary.flow.Out; import com.asakusafw.vocabulary.flow.Source; import com.asakusafw.vocabulary.flow.util.CoreOperatorFactory; import example.modelgen.dmdl.model.KamokuModel; import example.modelgen.dmdl.model.ScoreModel; import example.modelgen.dmdl.model.TenModel; import example.operator.ScoreOperatorFactory; import example.operator.ScoreOperatorFactory.AverageKamoku; import example.operator.ScoreOperatorFactory.ConvertScore; import example.operator.ScoreOperatorFactory.ConvertSigma; import example.operator.ScoreOperatorFactory.convertSigmaElement; import example.operator.ScoreOperatorFactory.JoinKamokuAverage; import example.operator.ScoreOperatorFactory.JoinKamokuSigma; import example.operator.ScoreOperatorFactory.SumKamoku; import example.operator.ScoreOperatorFactory.SumSigma;
@JobFlow(name = "standardScore")
public class ScoreJob extends FlowDescription {
final In<TenModel> ten;
final Out<ScoreModel> scoreOut;
public ScoreJob(@Import(name = "ten", description = TenFromCsv.class) In<TenModel> ten,
@Export(name = "score", description = ScoreToCsv.class) Out<ScoreModel> score) {
this.ten = ten;
this.scoreOut = score;
}
@Override
protected void describe() {
CoreOperatorFactory core = new CoreOperatorFactory();
ScoreOperatorFactory operators = new ScoreOperatorFactory();
// 学生・科目毎の成績に分割
Source<KamokuModel> kamoku = operators.split(ten).out;
// 平均点を算出
SumKamoku sumKamoku = operators.sumKamoku(kamoku);
AverageKamoku averageKamoku = operators.averageKamoku(sumKamoku.out);
core.stop(averageKamoku.original);
// 標準偏差を算出
JoinKamokuAverage kamokuAverage = operators.joinKamokuAverage(averageKamoku.out, kamoku);
core.stop(kamokuAverage.missed);
convertSigmaElement sigmaSum = operators.convertSigmaElement(kamokuAverage.joined);
core.stop(sigmaSum.original);
SumSigma sumTotal = operators.sumSigma(sigmaSum.out);
ConvertSigma sigma = operators.convertSigma(sumTotal.out);
core.stop(sigma.original);
// 学生・科目毎の偏差値を算出
JoinKamokuSigma kamokuSigma = operators.joinKamokuSigma(sigma.out, kamoku);
core.stop(kamokuSigma.missed);
ConvertScore score = operators.convertScore(kamokuSigma.joined);
core.stop(score.original);
scoreOut.add(score.out);
}
}
ほぼ一本道で進んでいるように見えるが、最初に作ったkamokuだけ何度も使用している。
→ジョブフローのグラフ化(可視化)
Convertは変換した出力の他に変換前の出力も出る。
また、MasterJoinは結合されたjoinedの他にマスターが無かった場合のmissedもあるが、今回のケースではマスターが無いことはありえないので、missedは無視してよい。
出力を捨てる(どのファイルにも出力しない)場合は、coreのstop演算子に出力しておく。
(AsakusaFWでは必ずどこかに出力しないといけない為)
オペレーターの単体テストとかはちょっと省略して、ジョブフローのテストを書いてみた。
ackage example.jobflow;
import org.junit.Test; import com.asakusafw.testdriver.JobFlowTester; import example.modelgen.dmdl.model.ScoreModel; import example.modelgen.dmdl.model.TenModel;
/**
* {@link ScoreJob}のテスト。
*/
public class ScoreJobTest {
@Test
public void testDescribe() {
JobFlowTester tester = new JobFlowTester(getClass());
tester.input("ten", TenModel.class).prepare("score.xls#input");
tester.output("score", ScoreModel.class).verify("score.xls#output", "score.xls#rule");
tester.runTest(ScoreJob.class);
}
}
| A | B | C | D | E | F | G | H | |
| 1 | student_id | student_name | suugaku | kokugo | rika | shakai | eigo | |
| 2 | 101 | 天才 | 100 | 100 | 100 | 100 | 100 | |
| 3 | 201 | 無気力 | 5 | 30 | 10 | 20 | 15 | |
| 4 | 102 | ひしだま | 90 | 85 | 80 | 50 | 10 | |
| 5 | 202 | hoge | 10 | 30 | 25 | 45 | 20 | |
| 6 | 103 | foo | 60 | 60 | 60 | 60 | 25 | |
| 7 | 204 | xxx | 80 | 77 | 90 | 40 | 44 | |
| 8 | 205 | yyy | 65 | 90 | 55 | 80 | 65 | |
| 9 | 104 | zzz | 40 | 60 | 60 | 70 | 20 | |
| 10 |
一番左のA列に注目。student_id(学生番号)は数値だが、DMDL上はTEXTで定義している。
この場合、セルに数値のまま入れておくと、テスト実行時に以下のような例外が発生する。(2, 1)というのは、row=2・col=1のことだと思われる。
java.lang.IllegalStateException: java.io.IOException: (file:/home/hishidama/asakusa-develop/workspace/afw-score/target/test-classes/example/jobflow/score.xls#input, 2, 1)の形式を判別できませんでした。先頭に ' を付けて文字列を表すようにしてください at com.asakusafw.testdriver.JobFlowTester.runTest(JobFlowTester.java:96) 〜 Caused by: java.io.IOException: (file:/home/hishidama/asakusa-develop/workspace/afw-score/target/test-classes/example/jobflow/score.xls#input, 2, 1)の形式を判別できませんでした。先頭に ' を付けて文字列を表すようにしてください at com.asakusafw.testdriver.excel.ExcelDataDriver$Engine.stringProperty(ExcelDataDriver.java:241) 〜
Excelで文字列扱いさせるにはセル内のデータの先頭にアポストロフィー「'」を付けるので、付けたら通るようになった。
(文字列扱いになったので、シート上も左寄せになる。数値項目(例えば点数は数値)は右寄せで表示される)
むしろ、アポストロフィーを付けないと駄目。シート上でセルの書式を文字列にしただけでは駄目だった。
(DMDLファイル上TEXTで指定された項目をExcelデータでは文字列にしないといけないのは、AsakusaFWの仕様で決まっている)
| A | B | C | D | E | F | G | H | |
| 1 | student_id | student_name | kamoku_id | kamoku_name | ten | average | score | |
| 2 | 101 | 天才 | 2 | 理科 | 100 | 60 | 63.87375951238592 | |
| 3 | 101 | 天才 | 0 | 数学 | 100 | 56.25 | 63.23821580326409 | |
| 4 | 101 | 天才 | 5 | 合計 | 500 | 278.25 | 67.99729272586669 | |
| 5 | 101 | 天才 | 3 | 社会 | 100 | 58.125 | 67.86190412715338 | |
| 6 | 101 | 天才 | 1 | 国語 | 100 | 66.5 | 63.56931586558015 | |
| 7 | 101 | 天才 | 4 | 英語 | 100 | 37.375 | 71.58220049611475 | |
| 8 | 102 | ひしだま | 2 | 理科 | 80 | 60 | 56.93687975619296 | |
| 9 | 102 | ひしだま | 1 | 国語 | 85 | 66.5 | 57.49350279143978 | |
| 10 | 102 | ひしだま | 5 | 合計 | 315 | 278.25 | 52.982640395380386 | |
| 11 | 102 | ひしだま | 3 | 社会 | 50 | 58.125 | 46.534257408164265 | |
| 12 | 102 | ひしだま | 4 | 英語 | 10 | 37.375 | 40.565864453794156 | |
| 13 | 102 | ひしだま | 0 | 数学 | 90 | 56.25 | 60.21233790537516 | |
| 14 |
double型の比較は大丈夫かちょっと心配だったが、基本は大丈夫。
はまったのは、有効桁数がExcelとJavaで異なること。Excelの方が1桁少ない。
G列のscore(偏差値)の値は、正しい値はCascadingのサンプルに出ているものなので
そのままExcelに貼り付けたら、末尾1桁が削れてしまって検証結果が一致しない。
ここでもExcel上のデータを文字列にしてやったら全桁入れられた。(アポストロフィーを付けず、セルの書式を文字列にするだけでOKだった)
あと、データは一番上の行の項目名で判定しているようなので、列ごと入れ替えても問題なかった。
(上記の例ではkamoku_nameとtenが入れ替えてある)
| A | B | C | D | E | |
| 1 | Format | EVR-1.0.0 | |||
| 2 | 全体の比較 | 余計なデータを無視 [Expect] | |||
| 3 | プロパティ | 値の比較 | NULLの比較 | コメント | |
| 4 | student_id | 検査キー [Key] | 通常比較 [-] | 学生番号 | |
| 5 | student_name | 完全一致 [=] | 通常比較 [-] | 学生名 | |
| 6 | kamoku_id | 検査キー [Key] | 通常比較 [-] | 科目 | |
| 7 | ten | 完全一致 [=] | 通常比較 [-] | 点数 | |
| 8 | kamoku_name | 完全一致 [=] | 通常比較 [-] | 科目名 | |
| 9 | average | 完全一致 [=] | 通常比較 [-] | 平均点 | |
| 10 | score | 完全一致 [=] | 通常比較 [-] | 偏差値 | |
| 11 |
今回は学生番号と科目IDがキーなので、2項目を検査キーに指定している。
また、outputシートには全出力データは書いていない。そこで、「全体の比較」に「余計なデータを無視」を指定してある。つくづくよく準備されてるw
テストを実行すると、実際にHadoop(スタンドアローンモード)が実行される。
今回の場合は4つのMapReduceジョブが実行された。
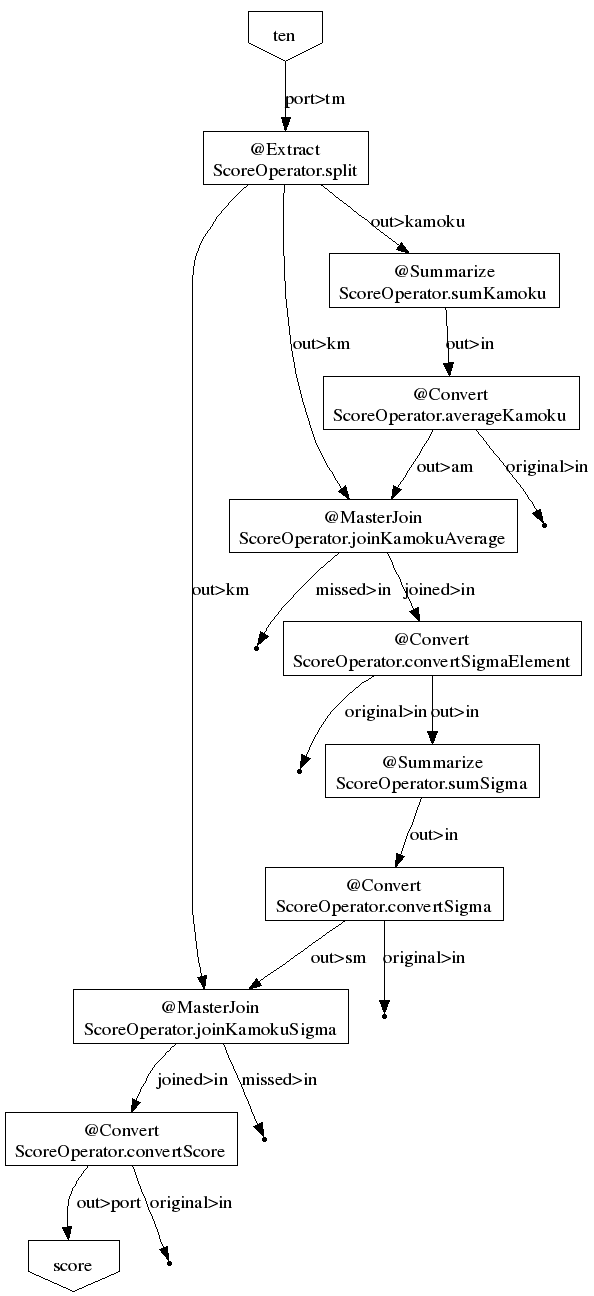
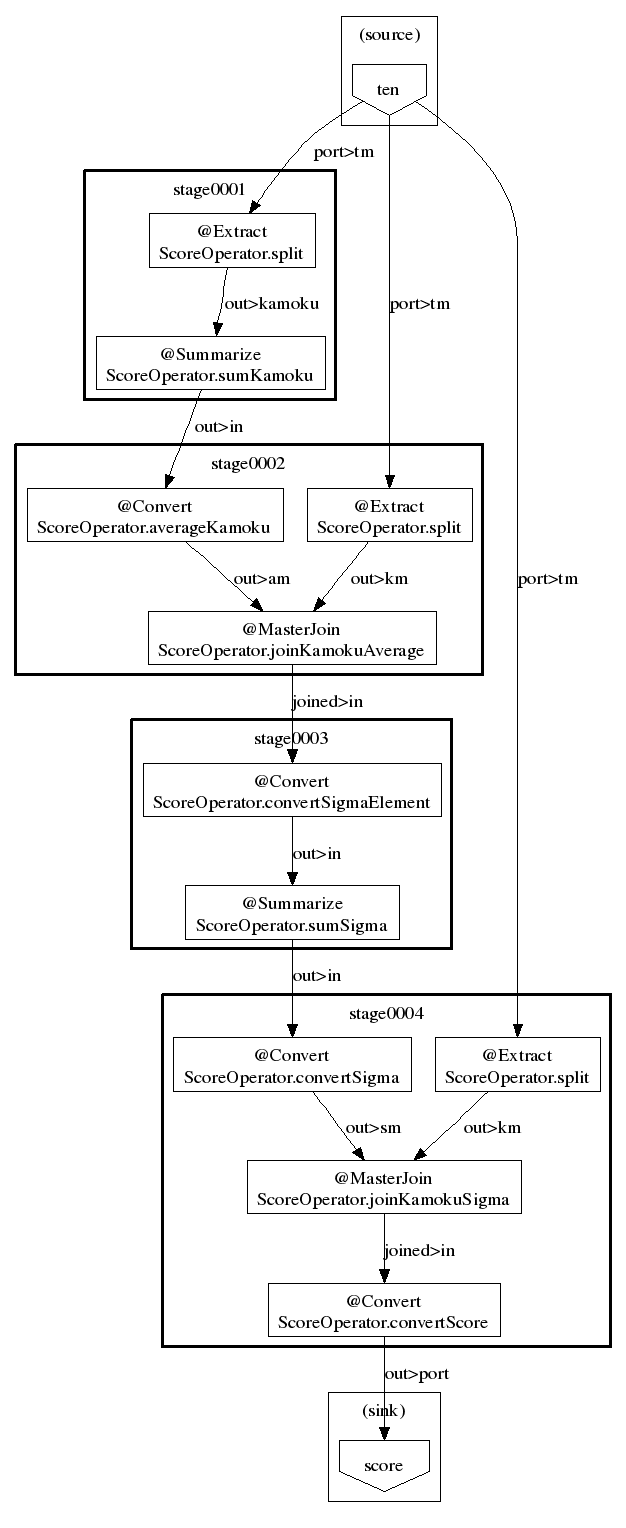
フローグラフとステージグラフは以下の通り。
| フローグラフ | ステージグラフ |
|---|---|
| ジョブフロー(演算子の呼び出し順) | 生成されるステージ(MapReduceジョブ) |
|
|
ステージグラフを見ると、ステージが4つ(すなわちMapReduceジョブが4つ)あるのが分かる。
また、一番最初のsplitが3箇所に存在している。
同じ処理を3回も実行するのは無駄なようにも思えるが、Hadoopではジョブ数を減らす方が全体的な実行時間を短く出来る事があるので、こうなっているのだろう。
Convertは基本的にMap処理だが、stage0004ではMasterJoinの後、すなわちReduce処理で実行するようになっている。
このような最適化もやってくれるというわけだ。