
AZAREA-Cluster0.9.0で偏差値算出処理を作ってみる。
|
|
偏差値は以下のような計算式で算出できる。
プロジェクトの作成とかフロー編集ツールの使い方はWordCountサンプルと同じ。
最終的に出来上がったフロークラスの中核部分は以下の通り。
(青字は自分でコーディングした部分)
package example.flow;
@Generated("AZAREA-Cluster 1.0")
public class ScoreFlow extends EntityFlow {
@Override
protected void initialize() {
getEntityManager().defineEntityFormat("TenEntity.txt", DelimitedEntityFormat.delimiter(","));
EntityFile<TenEntity> entity1 = getInput(TenEntity.class);
Conversion<TenEntity, KamokuEntity> split = new Conversion<TenEntity, KamokuEntity>(entity1) {
@Override
protected void convert(TenEntity entity) {
// 科目毎の成績に分割
output(createKamoku(entity, 0, entity.suugaku));
output(createKamoku(entity, 1, entity.kokugo));
output(createKamoku(entity, 2, entity.rika));
output(createKamoku(entity, 3, entity.shakai));
output(createKamoku(entity, 4, entity.eigo));
output(createKamoku(entity, 5, entity.suugaku + entity.kokugo + entity.rika + entity.shakai + entity.eigo));
}
private KamokuEntity createKamoku(TenEntity entity, int kamokuId, int ten) {
KamokuEntity result = new KamokuEntity();
result.studentId = entity.studentId;
result.studentName = entity.studentName;
result.kamokuId = kamokuId;
result.ten = ten;
return result;
}
};
↑ここの変数名がsplitになっているのは、フロー上で変数名を付けてみたから。
(他のがデフォルトのentity1とかentity2のままなのは、変数名を付けるのが面倒になったから(爆)
フローを試行錯誤しながら(エンティティーを追加したり削ったりしながら)作っているときに、いちいち変数名を付けてられない^^;
後からでも変数名は変えられるし(フロー上で変えてもソース上で変えてもちゃんと反映される))
Conversion<KamokuEntity, KamokuTotalEntity> entity2 = new Conversion<KamokuEntity, KamokuTotalEntity>(split) {
@Override
protected void convert(KamokuEntity entity) {
KamokuTotalEntity result = new KamokuTotalEntity();
result.kamokuId = entity.kamokuId;
result.ten = entity.ten;
result.count = 1;
output(result);
}
};
Group<KamokuTotalEntity> entity3 = new Group<KamokuTotalEntity>(entity2, "kamokuId") {
@Override
protected void doSummarize(KamokuTotalEntity summary, KamokuTotalEntity another) {
// 科目毎の合計点を算出
summary.ten += another.ten;
summary.count += another.count;
}
};
Conversion<KamokuTotalEntity, AverageEntity> entity4 = new Conversion<KamokuTotalEntity, AverageEntity>(entity3) {
@Override
protected void convert(KamokuTotalEntity entity) {
// 科目毎の平均点を算出
AverageEntity result = new AverageEntity();
result.kamokuId = entity.kamokuId;
result.count = entity.count;
result.average = (double) entity.ten / entity.count;
output(result);
}
};
UniqueJoin<KamokuEntity, AverageEntity, SigmaEntity> entity5 = new UniqueJoin<KamokuEntity, AverageEntity, SigmaEntity>(split, entity4, "kamokuId") {
@Override
protected void merge(KamokuEntity main, AverageEntity sub) {
SigmaEntity result = new SigmaEntity();
result.kamokuId = main.kamokuId;
result.average = sub.average;
result.count = sub.count;
result.sum = Math.pow(main.ten - sub.average, 2);
output(result);
}
@Override
protected void merge(KamokuEntity main) {
// たぶん、マッチするものが無いときに呼ばれる
// 今回は必ずマッチするはず
throw new IllegalStateException(main.toString());
}
};
Group<SigmaEntity> entity6 = new Group<SigmaEntity>(entity5, "kamokuId") {
@Override
protected void doSummarize(SigmaEntity summary, SigmaEntity another) {
summary.sum += another.sum;
}
};
Conversion<SigmaEntity, SigmaEntity> entity7 = new Conversion<SigmaEntity, SigmaEntity>(entity6) {
@Override
protected void convert(SigmaEntity entity) {
// 科目毎の標準偏差を算出
SigmaEntity result = new SigmaEntity();
result.copyFrom(entity);
result.sigma = Math.sqrt(entity.sum / entity.count);
output(result);
}
};
UniqueJoin<KamokuEntity, SigmaEntity, ScoreEntity> entity8 = new UniqueJoin<KamokuEntity, SigmaEntity, ScoreEntity>(split, entity7, "kamokuId") {
@Override
protected void merge(KamokuEntity main, SigmaEntity sub) {
// 学生・科目毎の偏差値を算出
ScoreEntity result = new ScoreEntity();
result.copyFrom(sub);
result.copyFrom(main);
result.kamokuName = 科目名[main.kamokuId];
result.score = (main.ten - sub.average) * 10 / sub.sigma + 50;
output(result);
}
@Override
protected void merge(KamokuEntity main) {
// たぶん、マッチするものが無いときに呼ばれる
// 今回は必ずマッチするはず
throw new IllegalStateException(main.toString());
}
};
setOutput(entity8); }
static final String 科目名[] = { "数学", "国語", "理科", "社会", "英語", "合計" };
public static void main(String[] args) throws Exception {
Main.execute(SimpleEntityFlowManager.class.getName(), ScoreFlow.class.getName(), args);
}
}
集計を行う場合はGroupクラスを使用する。
ただ、Groupの入力と出力は同じEntityクラスでないといけないようだ。
集計元と集計結果クラスを変えたい場合は、集計前にConversionクラスで一旦集計結果クラスに変換する。
(もしかするともっと良い方法があるのかもしれないが)
あと、doSummarize()メソッドは
データが8件あると7回呼ばれる。
データが2件だと1回だけ呼ばれると思われる。
データが1件しか無いときは呼ばれないと思われる。
データの結合はJoinまたはUniqueJoinクラスで行う。
今回は他方がマスターに当たるので、UniqueJoinで実装してみた。
件数の多い方がmain、マスター(件数が少ない方)がsubになるようにコーディングしないといけないようだ。
フローの図を見てみないと分かりづらいが、偏差値算出の処理は一つのデータを複数の処理で使っている。
こういった分岐は、フロー上で特に何も考えず線を複数箇所に向けて引けばいいので、簡単。
入力データをCSV形式にしたい場合は、エンティティーフォーマットを定義する。
initialize()メソッドの先頭でDelimitedEntityFormatによってフォーマットを指定する。
(エンティティーの編集画面でCSVやTSVを選択できるようになっていればいいのに…)
#番号,名前,数学,国語,理科,社会,英語 101,天才,100,100,100,100,100 201,無気力,5,30,10,20,15 102,ひしだま,90,85,80,50,10 202,hoge,10,30,25,45,20 103,foo,60,60,60,60,25 204,xxx,80,77,90,40,44 205,yyy,65,90,55,80,65 104,zzz,40,60,60,70,20
カンマの後ろに空白を入れていないのは、空白があると数値のパースに失敗してエラーになるから。
(trim()してパースして欲しいものだ)
「#」から始まっている行はコメント行として自動的に除外してくれる。
シミュレーターによって実行するクラスは以下の通り。
package example.flow;
import java.io.IOException;
import jp.co.cac.azarea.cluster.planner.job.SimpleEntityFlowManager;
import jp.co.cac.azarea.cluster.tester.MapReduceJobManagerTester;
import jp.co.cac.azarea.cluster.util.Generated;
@Generated("AZAREA-Cluster 1.0")
public class ScoreFlowTest {
public static void main(String[] args) throws IOException {
MapReduceJobManagerTester tester = new MapReduceJobManagerTester(new SimpleEntityFlowManager());
tester.test("../data", ScoreFlow.class.getName());
}
}
JUnitによってテスト結果を検証するクラスは以下の通り。
package example.flow;
import static org.junit.Assert.*;
import java.io.IOException;
import org.junit.Test;
import jp.co.cac.azarea.cluster.planner.job.SimpleEntityFlowManager;
import jp.co.cac.azarea.cluster.tester.MapReduceJobManagerTester;
public class ScoreFlowUnitTest {
@Test
public void scoreFlow() throws IOException {
MapReduceJobManagerTester tester = new MapReduceJobManagerTester(new SimpleEntityFlowManager());
assertTrue(tester.testAndAssert("../data", "../expected2", ScoreFlow.class.getName()));
}
}
検証データはexample/expected2/ScoreEntity.txtとして置いてある。
実はこれらのソースはWordCountサンプルと同じプロジェクト(同じパッケージ)で作ったのだが、
入力ファイルは同じディレクトリーにあっても必要なファイルだけ選んで読み込んでくれるが、
検証データは指定ディレクトリーにある全ファイルを使おうとするようだ。
当初はWordCountサンプルと同じexpectedディレクトリーの下にScoreEntity.txtを置いていたのだが、
そこにあったWordCountEntity.txtも読み込んで「マッチする出力が無い」というエラーになった(苦笑)
なので、当サンプルの検証ディレクトリーはexpected2にした。
なお、実行する度に「プロジェクト/azarea/result」の下に日付時刻ディレクトリーがどんどん増えていくので、適宜手で消す必要がある。
(最終結果ファイルだけでなく処理途中の中間ファイルもそこに置かれているので、デバッグに便利そう)
ScoreFlowクラスを選択した状態でAZAREA-Cluster Editorを起動すると、ソースを解釈してフローを表示してくれる。
出来上がったフローは以下の通り。(svgファイル出力機能で出力してみた)
えらく縦長(苦笑)なのはまぁ仕方ないとしても、問題は、実は偏差値算出のフローは途中で分岐して最後に合流していること。その部分が全く見えなくなっている。
手動で整形して見えるようにしてやると、こんな感じになる。
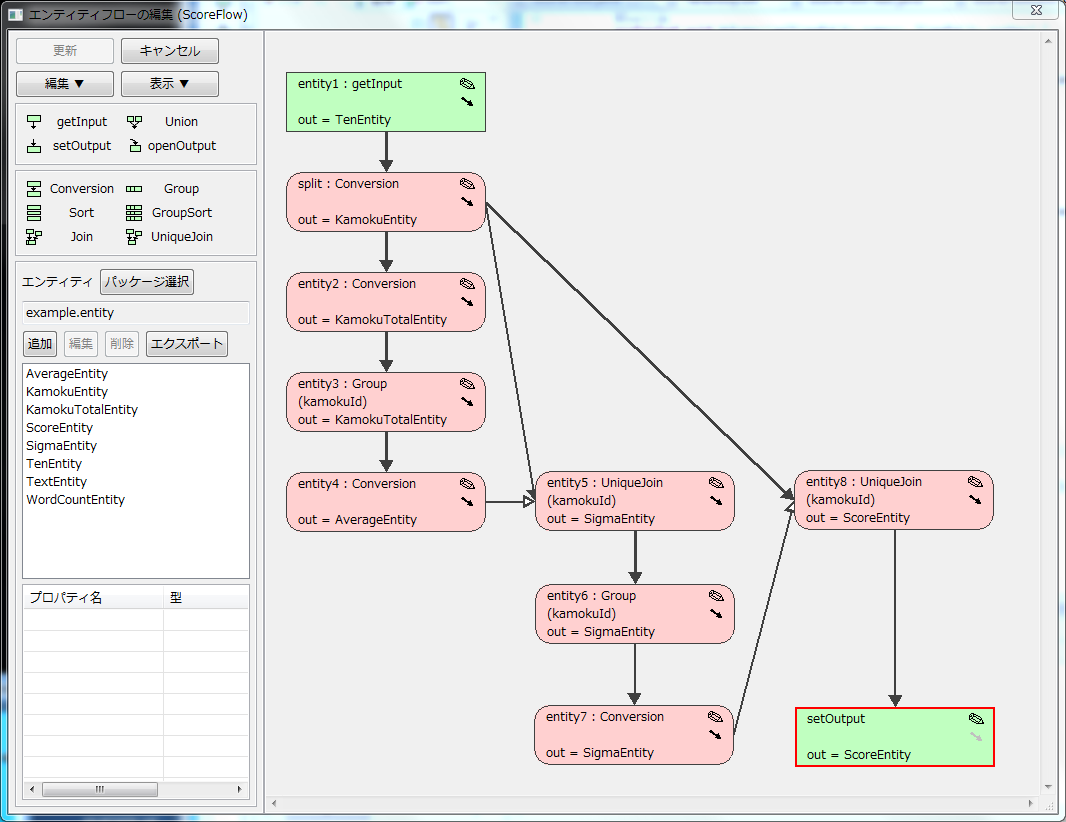
フローを表示する度に一直線になってしまうので、毎回手でずらさないといけないのは、さすがに面倒すぎる…。
それと、それぞれの枠(エンティティー)が仕様上の(何をするものなのかの)名称が出て欲しい。
Conversionだから変換なのは分かるが、「科目毎の成績に分割」とか「科目毎の標準偏差を算出」とかの図になっていないと、フローを見ても何をするものなのかよく分からない。
(もしかすると、このフローの図はコーディング的な(エンティティーの受け渡し順序の)分かりやすさを目指しているが、仕様を分かりやすく描く目的ではないということかな?)
「entity1」とかの変数名部分にそういう名前を入れればいいのかもしれないが、これはプログラム上の変数名なので、プログラムが変に見える可能性がある^^;
ついでに言えば、フロー上に(エンティティーとは別に)コメントを書きたくなるかも(笑)
「この一連の処理は●●をするもの」みたいな。
jarファイルを生成してHadoopクラスターで実行してみたところ、6個のMapReduceジョブとして実行された。
(ちょっとジョブ数が多い気もするけど、素直にMapReduceで作ればこんなものかな?
ちなみに、AsakusaFWでは4個のMapReduceジョブに最適化された。[2012-12-19])
$ hadoop fs -put TenEntity.txt azarea-score/input/TenEntity.txt $ hadoop jar ScoreFlow.jar -i=azarea-score/input -o=azarea-score/output
ジョブの進行状況がコンソールに出力される。
| 1 |
distributed.DistributedMapReduceExecuter: Job No.1 job.MapReduceJob: Create job "SimpleEntityFlowManager<example.flow.ScoreFlow>#1/6". job.MapReduceJob: ScoreFlowの1番目のConversion |
科目毎の成績に分割 |
| 2 |
distributed.DistributedMapReduceExecuter: Job No.2 job.MapReduceJob: Create job "SimpleEntityFlowManager<example.flow.ScoreFlow>#2/6". job.MapReduceJob: Operations in this job: job.MapReduceJob: ScoreFlowの2番目のConversion job.MapReduceJob: ScoreFlowの1番目のGroup |
科目毎の合計点を算出 |
| 3 |
distributed.DistributedMapReduceExecuter: Job No.3 job.MapReduceJob: Create job "SimpleEntityFlowManager<example.flow.ScoreFlow>#3/6". job.MapReduceJob: Operations in this job: job.MapReduceJob: ScoreFlowの3番目のConversion |
科目毎の平均点を算出 |
| 4 |
distributed.DistributedMapReduceExecuter: Job No.4 job.MapReduceJob: Create job "SimpleEntityFlowManager<example.flow.ScoreFlow>#4/6". job.MapReduceJob: Operations in this job: job.MapReduceJob: ScoreFlowの1番目のUniqueJoin job.MapReduceJob: ScoreFlowの2番目のGroup |
標準偏差を出す為の集計 |
| 5 |
distributed.DistributedMapReduceExecuter: Job No.5 job.MapReduceJob: Create job "SimpleEntityFlowManager<example.flow.ScoreFlow>#5/6". job.MapReduceJob: Operations in this job: job.MapReduceJob: ScoreFlowの4番目のConversion |
科目毎の標準偏差を算出 |
| 6 |
distributed.DistributedMapReduceExecuter: Job No.6 job.MapReduceJob: Create job "SimpleEntityFlowManager<example.flow.ScoreFlow>#6/6". job.MapReduceJob: Operations in this job: job.MapReduceJob: ScoreFlowの2番目のUniqueJoin |
学生・科目毎の偏差値を算出 |
どのクラスがどこのMapReduceで実行されているかが表示されるのは良いが、「n番目」という表記は分かりづらい(苦笑)
フローの図の各エンティティーに名前を付けられれば、それを表示すると良さそう。
あと、「-d」でReducer数が指定できるが、これは予想通り全ジョブに効いてしまう模様。個別に指定したい場合もあると思うのだが…。
$ hadoop jar ScoreFlow.jar -i=azarea-score/input -o=azarea-score/output -d=1
もし個別にReducer数を指定できるなら、フローの図の方で「この部分のReducerは1でよい」とか指定できるといいかも。
(最適化の妨げになる可能性はあるが、AZAREAはどれくらい最適化してくれるんだろう?
今回の例だと、No.4でUniqueJoinとGroupをひとつのMapReduceでやる位の最適化は入っているみたいだ。
この場合だと、Reducer数の指定をUniqueJoinとGroupで別々にやったら困るだろうなぁ)