S-JIS[2012-12-17]
変更履歴
AZAREAサンプル:WordCount
AZAREA-Cluster0.9.0でWordCountを作ってみる。
AZAREAアプリケーションの作成方法については、開発ガイドの「4
簡単なアプリケーションの開発」に手順が載っている。
全体的な手順としては、まずEclipseで専用のJavaプロジェクトを作る。
そしてエンティティクラス(入出力データを表すクラス)を用意し、フローを描く。
フローからJavaソースが生成されるので、メソッド部分をコーディングする。
- AZAREAフレームワークをインストールしたEclipseを起動する。
- 新規Javaプロジェクトを作成する。
- とりあえずazarea-wordcountとした。
- azarea-wordcountプロジェクトのビルドパスに、AZAREAフレームワークのjarファイルを追加する。
-
azarea-cluster-frameworkの下にはhadoop1とhadoop2(1系と2系)の2つのディレクトリーがあるが、どちらか片方だけを使用する。
- 今回はhadoop1を使った。(hadoop1直下の全てのjarファイルをビルドパスに追加する)
- パッケージを作成する。
- example.entity
- example.flow
- エンティティフローの編集画面を開く。
- 「新規エンティティフローを作成」ダイアログを開く。
-
パッケージエクスプローラーでexample.flowを右クリックし、「AZAREA-Cluster」→「新規エンティティフローを作成」を選ぶ。
- もしくは、パッケージエクスプローラーでexample.flowを選択し、ツールバーの「AZAREA-Cluster
Editor」をクリックする。
- パッケージ名に「example.flow」(デフォルト)、クラス名に「WordCountFlow」を入力する。
- OKボタンを押すと、WordCountFlowクラスが作られると共に編集画面(ダイアログ)が開く。
- エンティティクラスを作成する。
- 左側の「エンティティ
パッケージ選択」ボタンを押して「エンティティパッケージの選択」ダイアログを開き、「example.entity」を選択してOKボタンを押す。
- 入力データ用のエンティティを作成する。
- 「追加」ボタンを押して「エンティティクラスの追加」ダイアログを開く。
- エンティティを記入する。
- ダイアログの右側の「+」ボタンを押すとプロパティの行が追加されるので、それを編集する。
- プロパティ名はデフォルトではproperty1とかなので、それをクリックして書き換える。
- 型はプルダウンから選択する。
|
パッケージ |
example.entity |
|
クラス名 |
TextEntity |
| プロパティ名 |
型 |
| text |
String |
- 更新ボタンで確定する。
- 出力データ用のエンティティを作成する。
- 「追加」ボタンを押して「エンティティクラスの追加」ダイアログを開く。
- エンティティを記入する。
|
パッケージ |
example.entity |
|
クラス名 |
WordCountEntity |
| プロパティ名 |
型 |
| word |
String |
| count |
int |
- 更新ボタンで確定する。
- フローを作成する。
- 入力データを描く。
- エンティティ一覧で「TextEntity」を選択する。(入力データの型)
- 「getInput」のアイコンをドラッグして右側のエリアにドロップする。
- 変換処理を描く。
- エンティティ一覧で「WordCountEntity」を選択する。(変換処理の出力の型)
- 「Conversion」のアイコンをドラッグして右側のエリア(配置したgetInputの下)にドロップする。
- 集計処理を描く。
- エンティティ一覧で「WordCountEntity」を選択する。(集計処理の出力の型)
- 「Group」のアイコンをドラッグして右側のエリア(配置したConversionの下)にドロップする。
- 出力データを描く。
- エンティティ一覧で「WordCountEntity」を選択する。(出力データの型)
- 「setOutput」のアイコンをドラッグして右側のエリア(配置したGroupの下)にドロップする。
- 線で結ぶ。
- 配置したそれぞれの絵の右側に小さな矢印がある。それをドラッグして繋ぎ先の絵にドロップすると線が引かれる。
- 左上の「表示」ボタンを押して「エンティティファイルと処理を整列」を押すと綺麗に整列される。
- 集計処理の集計キーを指定する。
- 配置したGroupの絵の右上の鉛筆印をクリックし、「処理の編集」ダイアログを開く。
- 「Group固有の設定」のエンティティ列の「word」を選び、「グループ化」ボタンを押す。
- OKボタンで確定。
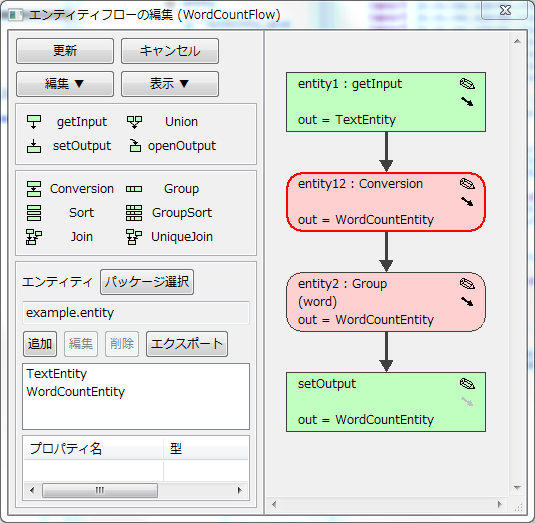
- フローを保存し、ソースの雛形を作成する。
- 左上の「更新」ボタンを押す。
- WordCountFlow#initialize()メソッド内にソースが生成される。
この時点で生成されたフローのソースは以下の通り。
package example.flow;
import example.entity.TextEntity;
import example.entity.WordCountEntity;
import jp.co.cac.azarea.cluster.Main;
import jp.co.cac.azarea.cluster.planner.job.EntityFlow;
import jp.co.cac.azarea.cluster.planner.job.SimpleEntityFlowManager;
import jp.co.cac.azarea.cluster.planner.operation.Conversion;
import jp.co.cac.azarea.cluster.planner.operation.EntityFile;
import jp.co.cac.azarea.cluster.planner.operation.Group;
import jp.co.cac.azarea.cluster.util.Generated;
@Generated("AZAREA-Cluster 1.0")
public class WordCountFlow extends EntityFlow {
@Override
protected void initialize() {
EntityFile<TextEntity> entity1 = getInput(TextEntity.class);
Conversion<TextEntity, WordCountEntity> entity2 = new Conversion<TextEntity, WordCountEntity>(entity1) {
@Override
protected void convert(TextEntity entity) {
// TODO
WordCountEntity result = new WordCountEntity();
result.copyFrom(entity);
output(result);
}
};
Group<WordCountEntity> entity3 = new Group<WordCountEntity>(entity2, "word") {
@Override
protected void doSummarize(WordCountEntity summary, WordCountEntity another) {
// TODO
}
};
setOutput(entity3);
}
public static void main(String[] args) throws Exception {
Main.execute(SimpleEntityFlowManager.class.getName(), WordCountFlow.class.getName(), args);
}
}
TODOコメントの下に、雛形となるソースも生成されている。
再度フローを修正したい場合は、パッケージエクスプローラー上でWordCountFlow.javaを右クリックし、「AZAREA-Cluster」→「クラスを編集」を選ぶ(あるいはツールバーの「AZAREA-Cluster
Editor」をクリックする)と編集ダイアログが開く。
フローの図は別の場所に保存されている訳ではなく、ソースを解析して生成しているらしい。
したがって、編集ダイアログ上で手動で整形してもその形は保存されず、再度ダイアログを開いたときに自動で整形される。
(ソース上でentity1等の変数名を変えても反映される)
生成されたTODOコメント部分をコーディングする。
@Generated("AZAREA-Cluster 1.0")
public class WordCountFlow extends EntityFlow {
@Override
protected void initialize() {
EntityFile<TextEntity> entity1 = getInput(TextEntity.class);
Conversion<TextEntity, WordCountEntity> entity2 = new Conversion<TextEntity, WordCountEntity>(entity1) {
@Override
protected void convert(TextEntity entity) {
StringTokenizer tokenizer = new StringTokenizer(entity.text);
while (tokenizer.hasMoreTokens()) {
WordCountEntity result = new WordCountEntity();
result.word = tokenizer.nextToken();
result.count = 1;
output(result);
}
}
};
Group<WordCountEntity> entity3 = new Group<WordCountEntity>(entity2, "word") {
@Override
protected void doSummarize(WordCountEntity summary, WordCountEntity another) {
summary.count += another.count;
}
};
setOutput(entity3);
}
public static void main(String[] args) throws Exception {
Main.execute(SimpleEntityFlowManager.class.getName(), WordCountFlow.class.getName(), args);
}
}
Conversion#convert()は素のMapReduceのMapper#map()と似ている。
入力データを加工して出力データを作り、output()で出力する。
Group#doSummarize()は関数型言語のfold関数に似ている。
anotherが個々のデータで、summaryに集計していく。
AZAREAはシミュレーターを使ってそのまま実行することが出来る。
まずはテストデータを用意する。
- パッケージエクスプローラーで「example.data」パッケージを作成する。
- 「example.data」の下にTextEntity.txtを作成する。(入力エンティティと同名で拡張子がtxt)
Hello World
Hello Hadoop
Hello AZAREA
次にテストクラスを作成する。
-
パッケージエクスプローラーで「WordCountFlow.java」を右クリックし、「AZAREA-Cluster」→「テストクラスを作成」を選んで「エンティティフローのテストクラスを作成」ダイアログを開く。
- ダイアログの各フィールドに入力する。
| ソースフォルダー |
src(デフォルト) |
本当はtestとかを別に用意すべきかな? |
| パッケージ |
example.flow(デフォルト) |
|
| クラス名 |
WordCountFlowTest |
|
| テスト対象 |
example.flow.WordCountFlow(デフォルト) |
|
| テストデータのパス |
D:\workspace\azarea-wordcount\src\example\data |
「フォルダー参照」ボタンでdataディレクトリーを指定する。 |
- これでWordCountFlowTest.javaが作られる。
package example.flow;
import java.io.IOException;
import jp.co.cac.azarea.cluster.planner.job.SimpleEntityFlowManager;
import jp.co.cac.azarea.cluster.tester.MapReduceJobManagerTester;
import jp.co.cac.azarea.cluster.util.Generated;
@Generated("AZAREA-Cluster 1.0")
public class WordCountFlowTest {
public static void main(String[] args) throws IOException {
MapReduceJobManagerTester tester = new MapReduceJobManagerTester(new SimpleEntityFlowManager());
tester.test("../data", WordCountFlow.class.getName());
}
}
WordCountFlowTestを実行すると、シミュレーターを使ってテストが実行される。
コンソールに以下の様なメッセージが表示される。
Output directory : file:/D:/workspace/azarea-wordcount/azarea/result/20121217_232749_635
[Input EntityFile]
EntityFile:#WordCountFlow-1(TextEntity.txt):TextEntity (39 bytes)
[Output EntityFile]
Group:#WordCountFlow-Group-1(WordCountEntity.txt):WordCountEntity <- [Conversion:#WordCountFlow-Conversion-1]:WordCountEntity by [word ASC]
[Operations]
Conversion:#WordCountFlow-Conversion-1:WordCountEntity <- [EntityFile:#WordCountFlow-1(TextEntity.txt)]:TextEntity
Group:#WordCountFlow-Group-1(WordCountEntity.txt):WordCountEntity <- [Conversion:#WordCountFlow-Conversion-1]:WordCountEntity by [word ASC]
[Job #1]
Operation
Conversion:#WordCountFlow-Conversion-1:WordCountEntity <- [EntityFile:#WordCountFlow-1(TextEntity.txt)]:TextEntity
Group:#WordCountFlow-Group-1(WordCountEntity.txt):WordCountEntity <- [Conversion:#WordCountFlow-Conversion-1]:WordCountEntity by [word ASC]
Distributing [word]
12/12/17 23:27:49 INFO util.DateCheckerImpl: Trial version is available until 2013/02/23 09:00:00.000.
Start job : SimpleEntityFlowManager<example.flow.WordCountFlow>#1/1
Summarizer = jp.co.cac.azarea.cluster.planner.summarizer.EntityFlowBasicSummarizer
Input entity=TextEntity.txt (class=example.entity.TextEntity, path=file:/D:/workspace/azarea-wordcount/classes/example/data/TextEntity.txt)
End converting (1 ms, 3 entities).
End summarizing (13 ms, 2 entities).
End merging (3 ms, 4 entities).
Operation input: #WordCountFlow-Conversion-1 : 3
Operation input: #WordCountFlow-Group-1 : 6
Operation output: #WordCountFlow-Conversion-1 : 6
Operation output: #WordCountFlow-Group-1 : 4
Ouput entity WordCountEntity.txt
word=AZAREA,count=1
word=Hello,count=3
word=World,count=1
word=Hadoop,count=1
End job (49 ms).
All jobs succeeded (225 ms).
また、azarea-wordcountプロジェクトの下に「azarea/result/日時」というディレクトリーが作られ、その下にWordCountEntity.txtが生成される。
(EclipseのワークスペースをF5キーで更新すると見えるようになる)
#word count
AZAREA 1
Hello 3
World 1
Hadoop 1
デフォルトのファイル名は出力データのエンティティクラス名と同じ。(編集画面でsetOutputの鉛筆印をクリックして出てくるダイアログで「中間出力」にチェックを付けるとファイル名を指定できる)
また、ヘッダー行が出力されている。
テストクラスでは、実行結果を検証することも出来る。
(開発ガイドの「8.5 実行結果の検証」)
事前に検証データ(正しい結果データ)を用意しておく。
- パッケージエクスプローラーで「example.expected」パッケージを作成する。
- 「example.expected」の下にWordCountEntity.txtを作成する。(出力エンティティと同名で拡張子がtxt)
Hello 3
World 1
Hadoop 1
AZAREA 1
※検証データはソートされている必要は無い。キーで自動的に判別される。
そして、テストクラスを作成する。
package example.flow;
import static org.junit.Assert.*;
import java.io.IOException;
import org.junit.Test;
import jp.co.cac.azarea.cluster.planner.job.SimpleEntityFlowManager;
import jp.co.cac.azarea.cluster.tester.MapReduceJobManagerTester;
public class WordCountFlowUnitTest {
@Test
public void wordCountFlow() throws IOException {
MapReduceJobManagerTester tester = new MapReduceJobManagerTester(new SimpleEntityFlowManager());
assertTrue(tester.testAndAssert("../data", "../expected", WordCountFlow.class.getName()));
}
}
これをJUnitとして実行すればよい。
※ソート順も確認したい場合は「tester.setIgnoreRowOrder(false);」を加える。
作成したアプリケーションは、jarファイル化してHadoopクラスターで実行することが出来る。
- jarファイルを作成する。
-
パッケージエクスプローラーでWordCountFlow.javaを右クリックし、「AZAREA-Cluster」→「JARファイルを作成」を選択して「JARファイル作成」ダイアログを開く。
- 各項目を入力する。
| JARファイル名 |
WordCountFlow.jar |
| メインクラス |
example.flow.WordCountFlow |
| JAR対象フォルダー |
全てのフォルダー/classes |
| JAR対象ライブラリ |
AZAREA-Clusterライブラリ |
- 「作成」ボタンを押下すると、azarea-wordcountプロジェクトの直下にWordCountFlow.jarが生成される。
- 生成したjarファイルをHadoopクライアントのマシンにコピーする。
- それから、入力データをHDFS上に用意する。
(ファイル名をTextEntity.txtにする必要がある)$ vi hello.txt
$ hadoop fs -put hello.txt azarea-wordcount/input/TextEntity.txt
- アプリケーションを実行する。
(入出力場所にはディレクトリーを指定する)$ hadoop jar WordCountFlow.jar -i=azarea-wordcount/input -o=azarea-wordcount/output
- 出力結果を確認する。
$ hadoop fs -ls azarea-wordcount/output
Found 4 items
drwxr-xr-x - hishidama supergroup 0 2012-12-18 00:52 /user/hishidama/azarea-wordcount/output/WordCountEntity.txt
-rw-r--r-- 2 hishidama supergroup 52 2012-12-18 00:51 /user/hishidama/azarea-wordcount/output/_applicationContext.dat
drwxr-xr-x - hishidama supergroup 0 2012-12-18 00:51 /user/hishidama/azarea-wordcount/output/_logs
drwxr-xr-x - hishidama supergroup 0 2012-12-18 00:52 /user/hishidama/azarea-wordcount/output/_unhandled-1
$ hadoop fs -ls azarea-wordcount/output/WordCountEntity.txt
-rw-r--r-- 2 hishidama supergroup 0 2012-12-18 00:51 /user/hishidama/azarea-wordcount/output/WordCountEntity.txt/part-r-00000
-rw-r--r-- 2 hishidama supergroup 21 2012-12-18 00:51 /user/hishidama/azarea-wordcount/output/WordCountEntity.txt/part-r-00001
-rw-r--r-- 2 hishidama supergroup 20 2012-12-18 00:51 /user/hishidama/azarea-wordcount/output/WordCountEntity.txt/part-r-00002
-rw-r--r-- 2 hishidama supergroup 0 2012-12-18 00:51 /user/hishidama/azarea-wordcount/output/WordCountEntity.txt/part-r-00003
-rw-r--r-- 2 hishidama supergroup 29 2012-12-18 00:51 /user/hishidama/azarea-wordcount/output/WordCountEntity.txt/part-r-00004
-rw-r--r-- 2 hishidama supergroup 0 2012-12-18 00:51 /user/hishidama/azarea-wordcount/output/WordCountEntity.txt/part-r-00005
$ hadoop fs -cat azarea-wordcount/output/WordCountEntity.txt/part-r-00004
#word count
AZAREA 1
World 1
シミュレーターではWordCountEntity.txtというテキストファイルに出力されていたが、
HadoopクラスターではWordCountEntity.txtというディレクトリーに出力されている^^;
Reducer数はデフォルトでは最大の個数(タスク数)で実行するようになっているらしい。
実行時オプション「-d」でReducerの個数を指定することが出来る。
また、入力データもファイルでなく(TextEntity.txtという名の)ディレクトリーにすることが出来る。
出力ディレクトリーは既存ディレクトリーを指定できるが、実行前にクリアはされないようなので自分でクリアする必要がある。
$ hadoop fs -put hello.txt azarea-wordcount/input2/TextEntity.txt/hello.txt
$ hadoop fs -rmr azarea-wordcount/output
$ hadoop jar WordCountFlow.jar -i=azarea-wordcount/input2 -o=azarea-wordcount/output -d=1
$ hadoop fs -ls azarea-wordcount/output/WordCountEntity.txt
-rw-r--r-- 2 hishidama supergroup 46 2012-12-18 01:14 /user/hishidama/azarea-wordcount/output/WordCountEntity.txt/part-r-00000
$ hadoop fs -cat azarea-wordcount/output/WordCountEntity.txt/part-r-00000
#word count
AZAREA 1
Hadoop 1
Hello 3
World 1
ちなみに、Hadoopジョブのログはこんな感じ。
[Input EntityFile]
EntityFile:#WordCountFlow-1(TextEntity.txt):TextEntity (38 bytes)
[Output EntityFile]
Group:#WordCountFlow-Group-1(WordCountEntity.txt):WordCountEntity <- [Conversion:#WordCountFlow-Conversion-1]:WordCountEntity by [word ASC]
[Operations]
Conversion:#WordCountFlow-Conversion-1:WordCountEntity <- [EntityFile:#WordCountFlow-1(TextEntity.txt)]:TextEntity
Group:#WordCountFlow-Group-1(WordCountEntity.txt):WordCountEntity <- [Conversion:#WordCountFlow-Conversion-1]:WordCountEntity by [word ASC]
[Job #1]
Operation
Conversion:#WordCountFlow-Conversion-1:WordCountEntity <- [EntityFile:#WordCountFlow-1(TextEntity.txt)]:TextEntity
Group:#WordCountFlow-Group-1(WordCountEntity.txt):WordCountEntity <- [Conversion:#WordCountFlow-Conversion-1]:WordCountEntity by [word ASC]
Distributing [word]
12/12/18 01:14:36 INFO distributed.DistributedMapReduceExecuter: max tasks = 6
12/12/18 01:14:36 INFO util.DateCheckerImpl: Trial version is available until 2013/02/23 09:00:00.000.
12/12/18 01:14:36 INFO distributed.DistributedMapReduceExecuter: Job No.1
12/12/18 01:14:36 INFO job.MapReduceJob: Create job "SimpleEntityFlowManager<example.flow.WordCountFlow>#1/1".
12/12/18 01:14:36 INFO job.MapReduceJob: Combiner = null
12/12/18 01:14:36 INFO job.MapReduceJob: Summarizers = 1
12/12/18 01:14:36 INFO job.MapReduceJob: Distribution count = 1
12/12/18 01:14:36 INFO job.MapReduceJob: Reducer count = 1
12/12/18 01:14:36 INFO job.MapReduceJob: Input paths=[hdfs://namenode:50010/user/hishidama/azarea-wordcount/input2/TextEntity.txt]
12/12/18 01:14:36 INFO job.MapReduceJob: Max input split size = 9223372036854775807
12/12/18 01:14:36 INFO job.MapReduceJob: Output path = hdfs://namenode:50010/user/hishidama/azarea-wordcount/output
12/12/18 01:14:36 INFO job.MapReduceJob: Output entities = [WordCountEntity.txt]
12/12/18 01:14:36 INFO job.MapReduceJob: Output format class = class jp.co.cac.azarea.cluster.reduce.EntityOutputFormat
12/12/18 01:14:36 INFO job.MapReduceJob: Operations in this job:
12/12/18 01:14:36 INFO job.MapReduceJob: WordCountFlowの1番目のConversion
12/12/18 01:14:36 INFO job.MapReduceJob: WordCountFlowの1番目のGroup
12/12/18 01:14:37 INFO input.FileInputFormat: Total input paths to process : 1
12/12/18 01:14:37 INFO mapred.JobClient: Running job: job_201210022208_0029
12/12/18 01:14:38 INFO mapred.JobClient: map 0% reduce 0%
12/12/18 01:14:44 INFO mapred.JobClient: map 100% reduce 0%
12/12/18 01:14:51 INFO mapred.JobClient: map 100% reduce 33%
12/12/18 01:14:53 INFO mapred.JobClient: map 100% reduce 100%
12/12/18 01:14:54 INFO mapred.JobClient: Job complete: job_201210022208_0029
12/12/18 01:14:54 INFO mapred.JobClient: Counters: 32
12/12/18 01:14:54 INFO mapred.JobClient: Job Counters
12/12/18 01:14:54 INFO mapred.JobClient: Launched reduce tasks=1
12/12/18 01:14:54 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=6034
12/12/18 01:14:54 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
12/12/18 01:14:54 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
12/12/18 01:14:54 INFO mapred.JobClient: Launched map tasks=1
12/12/18 01:14:54 INFO mapred.JobClient: Data-local map tasks=1
12/12/18 01:14:54 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=9307
12/12/18 01:14:54 INFO mapred.JobClient: AZAREA
12/12/18 01:14:54 INFO mapred.JobClient: Input: TextEntity.txt=3
12/12/18 01:14:54 INFO mapred.JobClient: Operation input: #WordCountFlow-Group-1=6
12/12/18 01:14:54 INFO mapred.JobClient: Output: WordCountEntity.txt=4
12/12/18 01:14:54 INFO mapred.JobClient: Operation output: #WordCountFlow-Group-1=4
12/12/18 01:14:54 INFO mapred.JobClient: Operation output: #WordCountFlow-Conversion-1=6
12/12/18 01:14:54 INFO mapred.JobClient: Operation input: #WordCountFlow-Conversion-1=3
12/12/18 01:14:54 INFO mapred.JobClient: FileSystemCounters
12/12/18 01:14:54 INFO mapred.JobClient: FILE_BYTES_READ=72
12/12/18 01:14:54 INFO mapred.JobClient: HDFS_BYTES_READ=708
12/12/18 01:14:54 INFO mapred.JobClient: FILE_BYTES_WRITTEN=123333
12/12/18 01:14:54 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=46
12/12/18 01:14:54 INFO mapred.JobClient: Map-Reduce Framework
12/12/18 01:14:54 INFO mapred.JobClient: Map input records=3
12/12/18 01:14:54 INFO mapred.JobClient: Reduce shuffle bytes=72
12/12/18 01:14:54 INFO mapred.JobClient: Spilled Records=8
12/12/18 01:14:54 INFO mapred.JobClient: Map output bytes=58
12/12/18 01:14:54 INFO mapred.JobClient: CPU time spent (ms)=1570
12/12/18 01:14:54 INFO mapred.JobClient: Total committed heap usage (bytes)=147591168
12/12/18 01:14:54 INFO mapred.JobClient: Combine input records=0
12/12/18 01:14:54 INFO mapred.JobClient: SPLIT_RAW_BYTES=150
12/12/18 01:14:54 INFO mapred.JobClient: Reduce input records=4
12/12/18 01:14:54 INFO mapred.JobClient: Reduce input groups=4
12/12/18 01:14:54 INFO mapred.JobClient: Combine output records=0
12/12/18 01:14:54 INFO mapred.JobClient: Physical memory (bytes) snapshot=245874688
12/12/18 01:14:54 INFO mapred.JobClient: Reduce output records=4
12/12/18 01:14:54 INFO mapred.JobClient: Virtual memory (bytes) snapshot=1066672128
12/12/18 01:14:54 INFO mapred.JobClient: Map output records=4
AZAREA目次へ戻る /
技術メモへ戻る
メールの送信先:ひしだま