S-JIS[2011-10-01/2012-09-20] 変更履歴
ひしだま作の、ScalaのREPL上でHadoopのHDFSを操作するツール(ライブラリー)です。
ScalaのREPL上でHadoopのクラスをそのまま使うことが出来ますが、素のFileSystemやPathだけだと扱いづらいので、ちょっと便利なクラスを作ってみました。
ファイル一覧の表示やテキストファイル・シーケンスファイルの内容の表示、簡単な書き込みが出来ます。
shr.zip(172kB)[/2012-09-20]
ソース(GitHubで公開)
hadoopシェルが実行できる(パスが通っている)こと。
環境変数SCALA_HOMEが定義されていること。(Scala2.9.1で動作確認しています)
Windowsの場合はCygwinがインストールされていること。
shr.zipをダウンロードして適当な場所に解凍します。
出来たshrディレクトリーの中のshr.shを実行します。(Windowsの場合はCygwinのbashから実行)
$ cd shr $ chmod u+x *.sh $ ./shr.sh Loading shr.scala... ** Power User mode enabled - BEEP BOOP SPIZ ** ** :phase has been set to 'typer'. ** ** scala.tools.nsc._ has been imported ** ** global._ and definitions._ also imported ** ** Try :help, vals.<tab>, power.<tab> ** import org.apache.hadoop.io._ import jp.hishidama.shr._ ** Power User mode enabled - BEEP BOOP SPIZ ** ** :phase has been set to 'typer'. ** ** scala.tools.nsc._ has been imported ** ** global._ and definitions._ also imported ** ** Try :help, vals.<tab>, power.<tab> ** Welcome to Scala version 2.9.2 (Java HotSpot(TM) Client VM, Java 1.6.0_27). Type in expressions to have them evaluated. Type :help for more information.
実行すると、自動的にshr.scala(スクリプト)を読み込みます。[2012-09-02]
このスクリプトは、REPLをパワーモードに変更し、クラス類をインポートしています。[/2011-10-08]
「Power User modeになった」というメッセージが2回出ているのが気になるけど^^;、とりあえず大丈夫。
以前のバージョンでは、Scala2.9.1および2.9.2のバグにより、shr.scalaの自動読み込みは出来ませんでした。[2012-09-02]
(scalaコマンドの「-i」オプションでshr.scalaを読み込めるはずだが、途中で固まる。とりあえず「-Yrepl-sync」を付けると読み込めるので、最新版では大丈夫のはず)
もし自動的に実行されないようなら、shr.shを修正し、自分でshr.scalaを読み込んで下さい。
$ vi shr/shr.sh
hadoop scala.tools.nsc.MainGenericRunner -cp "$SHR_CLASSPATH" -Yrepl-sync -i shr.scala #hadoop scala.tools.nsc.MainGenericRunner -cp "$SHR_CLASSPATH" -i shr.scala #hadoop scala.tools.nsc.MainGenericRunner -cp "$SHR_CLASSPATH" ↓ #hadoop scala.tools.nsc.MainGenericRunner -cp "$SHR_CLASSPATH" -Yrepl-sync -i shr.scala #hadoop scala.tools.nsc.MainGenericRunner -cp "$SHR_CLASSPATH" -i shr.scala hadoop scala.tools.nsc.MainGenericRunner -cp "$SHR_CLASSPATH"
$ cd shr $ chmod u+x *.sh $ ./shr.sh Welcome to Scala version 2.9.1.final (Java HotSpot(TM) Client VM, Java 1.6.0_27). Type in expressions to have them evaluated. Type :help for more information.
scala> :load shr.scala Loading shr.scala... ** Power User mode enabled - BEEP BOOP SPIZ ** ** :phase has been set to 'typer'. ** ** scala.tools.nsc._ has been imported ** ** global._ and definitions._ also imported ** ** Try :help, vals.<tab>, power.<tab> ** import org.apache.hadoop.io._ import jp.hishidama.shr._
主にjp.hishidama.shr.Pathクラスを使います。(基本的にはFileSystemやPathの単なるラッパーです)
| 例 | 説明 |
|---|---|
val path = Path("/user/hdfs")
val path = "/user.hdfs".toPath
|
HDFS上のパスを指定する。 |
val file = LocalPath("/home/hishidama/zzz.txt")
val file = File("/home/hishidama/zzz.txt")
val file = "/home/hishidama/zzz.txt".toLocalPath
|
ローカルのパスを指定する。 FileとLocalPathはまったく同じで、いずれもPathを返す。 Cygwinの場合はUNIXとしてのパスを指定する。内部ではWindowsのパスに変換して保持される。 |
path.ls |
パス内のファイル・ディレクトリー一覧を表示する。 |
path.list |
パス内のファイル・ディレクトリー一覧を取得する。(Seq[Path]が返る) |
path.view |
パス(ディレクトリー・ファイル)の内容を表示するウィンドウが開く。[2011-11-10] →ビューアー |
file.show |
moreと同じ。[/2011-10-10] |
file.cat |
headと同じ。[/2011-10-10] |
file.more file.more(100) file.more(100, 10000) |
ファイルがシーケンスファイルであれば、SeqFileのmoreと同じ。[2011-10-10] それ以外であれば、ファイルをテキストとして読み込み、指定された行数ずつ表示する。 さらにデータがあるときは「more?」と表示される。 「q」を押すと終了、Enterを押すとさらに1行表示、他のキーを押すとさらに指定行数だけ表示する。 スキップバイト数の指定方法はtailと同じ。 |
file.head file.head(10) |
ファイルがシーケンスファイルであれば、SeqFileのheadと同じ。[/2011-10-10] それ以外であれば、ファイルをテキストとして読み込み、指定された行数だけ表示する。 |
file.tail file.tail(10) file.tail(10, 100000) file.tail(10, -200)
|
ファイルがシーケンスファイルであれば、SeqFileのtailと同じ。[/2011-10-10] それ以外であれば、ファイルをテキストとして読み込み、末尾から指定行数だけ表示する。 デフォルトでは先頭から全部読み込むので、大きいファイルだと効率が悪い。[/2011-10-08] スキップするバイト数を指定すると、その分を跳ばして読み込むので効率が良くなる。 スキップバイト数に負の数を指定すると、“ファイル末尾からその分戻った位置”から読み込む。 |
file.lines |
ファイルの内容を順次読み込む為のIterator[Serializable] with
Closeableを取得する。[/2012-09-20]Iteratorなので、一度しか読めない。(isTraversableAgainがfalse) テキストファイルとして読む為には「 file.asTextFile.lines」とする。この場合はIterator[String]
with Closeableとなる。シーケンスファイルの場合は「 file.asSeqFile.lines()」とする。 |
file #< "文字列" file #< """文字列1 文字列2 文字列3""" |
ファイルに文字列を書き込む。"""(
生文字リテラル)を使えば改行も可。 |
val bw = file.asTextFile.openWriter() for (i <- 1 to 10000) bw.write(i + "\n") bw.close() |
大量データをファイルに書き込む例。[/2012-09-20] |
path.cd("hishidama")
path.cd("..")
path.cd("hi*")
|
指定された相対位置の新しいPathを返す。(change directory) 存在しないディレクトリーの場合は例外が発生する。 ワイルドカードを指定した場合は、マッチした最初のパスとなる。 |
path.file("hishidama/zzz.txt")
path.file("../zzz.txt")
path.file("hishidama/*.txt")
|
指定された相対位置の新しいPathを返す。[2011-10-03] 存在しないファイルの場合は例外が発生する。 ワイルドカードを指定した場合は、マッチした最初のパスとなる。 |
path.child("hishidama/*.txt")
|
指定された相対位置の新しいPathを返す。[/2011-10-05] ワイルドカードは解釈せず、そのままパスの一部となる。 新しいファイルやディレクトリーを作る際のパスの指定に使用する想定。 |
file.copy(path) |
ファイルをコピーする。 |
path.merge("*.txt", File("result.txt"))
|
複数のファイルをマージ(結合)して1つのファイルにコピーする。 |
その他にも色々なメソッドがあるので、jp.hishidama.shr.Pathのソースを見て下さい(爆)
(REPLの機能により、file.やpath.でタブキーを押せばメソッド一覧が表示されます)
基本的には、パスの変数を用意し、それに対してメソッドを呼び出します。[2011-10-03]
scala> val f = LocalPath("/home/hishidama")
f: jp.hishidama.shr.Path = file:/D:/cygwin/home/hishidama/
scala> f.ls
file:/D:/cygwin/home/hishidama/asakusa
file:/D:/cygwin/home/hishidama/wordcount
file:/D:/cygwin/home/hishidama/zzz.txt
res0: jp.hishidama.shr.Path = file:/D:/cygwin/home/hishidama/
lsコマンドの実行結果の一番最後に出ているのは、現在のPathです。
ScalaのREPLでは、ピリオドからメソッド呼び出しを書き始めた場合、前の行の実行結果に対するメソッド呼び出しとなります。
したがって、lsコマンドを実行した後、続けてcdやlsを呼び出すことが出来ます。
scala> f.ls
file:/D:/cygwin/home/hishidama/asakusa
file:/D:/cygwin/home/hishidama/wordcount
file:/D:/cygwin/home/hishidama/zzz.txt
res0: jp.hishidama.shr.Path = file:/D:/cygwin/home/hishidama/
scala> .cd("w*")
res1: jp.hishidama.shr.Path = file:/D:/cygwin/home/hishidama/wordcount
scala> .ls
file:/D:/cygwin/home/hishidama/wordcount/input
file:/D:/cygwin/home/hishidama/wordcount/output
file:/D:/cygwin/home/hishidama/wordcount/wordcount.jar
res2: jp.hishidama.shr.Path = file:/D:/cygwin/home/hishidama/wordcount
scala> .cd("in*").ls
file:/D:/cygwin/home/hishidama/wordcount/input/hello.txt
res3: jp.hishidama.shr.Path = file:/D:/cygwin/home/hishidama/wordcount/input
scala> .file("*.txt").head(2)
Hello World
Hello Scala
Scalaでは、メソッド呼び出しではピリオドを省略できます。
引数が1つのメソッドであれば、ピリオドの他に丸括弧も省略できます。
scala> f.ls scala> f ls scala> res4.head(2) scala> res4 head 2
SequenceFileを扱うクラスも作りました。[2011-10-08]
メソッドはjp.hishidama.shr.SeqFileのソースを見て下さい。
| 例 | 説明 |
|---|---|
val path = Path("/user/hdfs/seq1.dat")
val sf = SeqFile(path) val sf = path.asSeqFile
|
シーケンスファイルを指定する。 ファイルが存在しない場合は例外が発生する。 キーと値の型はNothingになる。[2012-09-20] |
val sf = SeqFile[Text, IntWritable](path) val sf = path.asSeqFile[Text, IntWritable] sf: jp.hishidama.shr.SeqFile[org.apache.hadoop.io.Text,org.apache.hadoop.io.IntWritable] = SeqFile(/user/hdfs/seq1.dat,org.apache.hadoop.io.Text,org.apache.hadoop.io.IntWritable) |
シーケンスファイルのキーと値の型を指定する方法。[2012-09-20] |
sf.isSequenceFile |
指定されたファイルがシーケンスファイルならtrueを返す。 |
sf.keyClassName sf.valClassName sf.keyClass sf.valClass res3: java.lang.String = org.apache.hadoop.io.Text |
シーケンスファイルのキーと値のクラス名やClassを返す。 |
sf.describe |
シーケンスファイルの各情報を文字列化したListを返す。 (toString()のようなもの。当クラスのtoString()は簡略化した情報だけ返す) |
sf.more (abc,123) |
シーケンスファイルの内容を表示する。[2011-10-10] 1行はキーと値のタプルを文字列化したものとなる。 (showはmoreと同じ) |
sf.head sf.head(10) |
シーケンスファイルの先頭を表示する。 (catはheadと同じ[2011-10-10]) |
sf.tail sf.tail(10) sf.tail(10, 10000) sf.tail(10, -500) |
シーケンスファイルの末尾を表示する。 スキップバイト数を指定した場合、その分だけ跳ばした位置以降のsyncから読み込む。 負の数を指定した場合はファイルの末尾からその分戻った位置以降のsyncとなる。 (シーケンスファイルは、数レコード毎に位置を示すデータ(sync)が置かれる) |
val i = sf.lines() i.foreach(println) i.close()
|
シーケンスファイルの内容を1行ずつ取得する。(キーと値のタプルのIteratorを返す) 型パラメーターでキーと値のクラスを指定しないとNothingになってしまう。 |
val i = sf.lines({ new Text }, { new IntWritable })
val i = sf.lines(NullWritable.get, new MyWritable)
|
linesの別の指定方法。 キーと値のインスタンスを生成する関数を渡す。 (このインスタンスにファイルから読み込んだデータが書き込まれる) |
独自のWritableを使う場合は、そのWritableが入ったjarファイルをクラスパスに指定する必要があります。[/2011-10-10]
それには環境変数SHR_CLASSPATHを使います。(Cygwinであっても、UNIX形式のパスで指定する)
$ export SHR_CLASSPATH=/tmp/sample-hadoop.jar
$ ./shr.sh
scala> :load shr.scala
scala> val sf = SeqFile(File("/tmp/seqwc.dat"))
sf: jp.hishidama.shr.SeqFile = SeqFile(file:/D:/cygwin/tmp/seqwc.dat,org.apache.hadoop.io.NullWritable,sample.WordCountWritable)
scala> sf.show
((null),WordCountWritable{getCount=123, getWord=Hello})
((null),WordCountWritable{getCount=456, getWord=World})
WritableにtoString()が実装されていない場合は、ゲッターメソッドを呼び出して表示されます。
Asakusa Frameworkのデータモデル(Writable)は、クラスパスを指定すると表示できます。[2011-10-10]
クラスパスを自分で明示的に指定したい場合は、以下のようにします。
Windows(Cygwin)の場合 $ export SHR_CLASSPATH=$(cygpath -u "$ASAKUSA_HOME/batchapps/bid/lib/jobflow-WordCountJob.jar"):$(cygpath -u "$ASAKUSA_HOME/core/lib/asakusa-runtime.jar") UNIXの場合 $ export SHR_CLASSPATH=$ASAKUSA_HOME/batchapps/bid/lib/jobflow-WordCountJob.jar:$ASAKUSA_HOME/core/lib/asakusa-runtime.jarこの「jobflow-WordCountJob.jar」はジョブフローのテスト実行用に作られているjarファイルで、Writableのクラス定義が入っています。
AsakusaFWのWritableクラス(DMDLで生成されたクラス)はDataModelインターフェースを実装している為、それが入っているasakura-runtime.jarも必要となります。
※「asakusa-runtime.jar」はAsakusaFW0.2系のファイル名であり、AsakusaFW0.4系では「asakusa-runtime-all.jar」にする必要があります。[2012-09-02]
当ツールの最新版では、環境変数ASAKUSA_HOMEが設定されている場合は以下のものは自動的にクラスパスに含めるので、明示的に自分で指定する必要はありません。[/2012-09-02]
さらに、当ツールの実行中にjarファイルを検索することも出来るので、jobflowのjarファイルを事前に指定する必要もありません。[2011-11-30]
scala> :load shr.scala
scala> val sf = SeqFile(File("/home/hishidama/output/wc-r-00000"))
sf: jp.hishidama.shr.SeqFile = SeqFile(file:/D:/cygwin/home/hishidama/output/wc-r-00000,org.apache.hadoop.io.NullWritable,jp.hishidama.afw.wordcount.modelgen.dmdl.model.WordCountModel)
scala> sf.show
((null),{class=word_count_model, word=Asakusa, count=1})
((null),{class=word_count_model, word=Hello, count=3})
((null),{class=word_count_model, word=Hadoop, count=1})
((null),{class=word_count_model, word=World, count=1})
AsakusaFWのWritableクラスはtoString()が実装されている為、それを使って表示されます。
“クラスパスに入っていないクラス”を使っているシーケンスファイルを表示しようとすると(クラスがロードできなくて)例外が発生します。[2011-10-12]
scala> val sf = SeqFile(File("/tmp/seqwc.dat"))
sf: jp.hishidama.shr.SeqFile = SeqFile(file:/D:/cygwin/tmp/seqwc.dat,org.apache.hadoop.io.NullWritable,sample.WordCountWritable)
scala> sf.show
java.lang.RuntimeException: java.io.IOException: WritableName can't load class: sample.WordCountWritable
at org.apache.hadoop.io.SequenceFile$Reader.getValueClass(SequenceFile.java:1630)
〜
Caused by: java.io.IOException: WritableName can't load class: sample.WordCountWritable
at org.apache.hadoop.io.WritableName.getClass(WritableName.java:73)
at org.apache.hadoop.io.SequenceFile$Reader.getValueClass(SequenceFile.java:1628)
... 35 more
Caused by: java.lang.ClassNotFoundException: sample.WordCountWritable
at scala.tools.nsc.interpreter.AbstractFileClassLoader.findClass(AbstractFileClassLoader.scala:51)
at java.lang.ClassLoader.loadClass(ClassLoader.java:306)
〜
このとき、REPLを一旦終了して環境変数SHR_CLASSPATHにクラスの入っているjarファイルを指定するのが正攻法ですが
REPLの再起動は時間がかかるし面倒なので、その場でクラスパスを追加する方法を考案しました。
scala> val jar = sf.findValClassJar("/tmp") …/tmpの下から(サブディレクトリーも含めて)valClassの定義されているjarファイルを探す
jar: Seq[java.io.File] = List(D:\cygwin\tmp\sample-hadoop.jar)
scala> conf.addClassPath(jar) …confのクラスローダーにjarファイルを追加する
scala> sf.show …再び実行してみると、ちゃんと表示される!
((null),WordCountWritable{getCount=123, getWord=Hello})
((null),WordCountWritable{getCount=456, getWord=World})
キーがText、値がIntWritableであるシーケンスファイルを作って書き込む例です。
val path = Path("/user/hdfs/seq1.dat")
val sf = SeqFile.createWriter[Text, IntWritable](path)
sf.append(new Text("abc"), new IntWritable(123))
sf.append("def", 456)
sf.close()
TextやIntWritableに関してはString・Intとの暗黙変換が定義してあるので、そのまま使うことが出来ます。
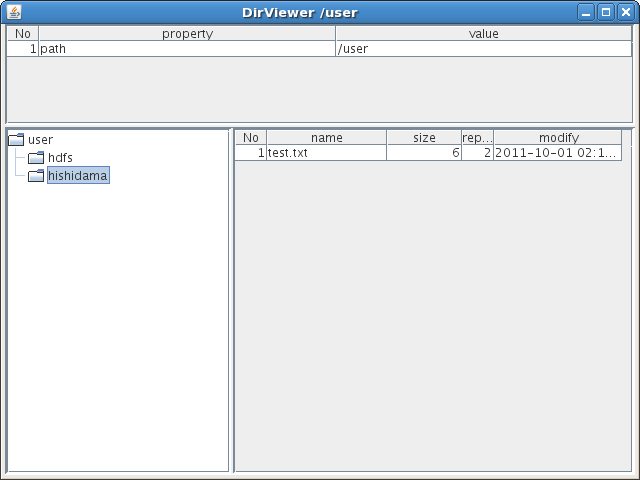
Pathに対してviewを実行すると、ビューアーが開きます。[2011-11-10]
PathがディレクトリーのときはDirViewer、シーケンスファイルのときはSeqFileViewer、それ以外のファイルのときはTextViewerが開きます。
※ウィンドウが1つでも開いていると、「:quit」ではREPLが終了しません。「exit」だと警告は出ますがウィンドウごとREPLが終了します。
scala> Path("/user").ls
hdfs://namenode:50010/user/hdfs
hdfs://namenode:50010/user/hishidama
res1: jp.hishidama.shr.Path = /user
scala> res1.view
DirViewerでは、ツリーのディレクトリー部分をクリックすると右側にそのディレクトリーのファイル一覧が表示されます。
ファイル一覧の「No」をダブルクリックするとそのファイルの内容を表示するウィンドウが開きます。
まだまだ未完成なので、各ファイルの先頭100件が文字列で表示できる程度ですが…。
(ネームノードのポート50070「http://namenode:50070/dfshealth.jsp」をブラウザーで開いて「Browse
the filesystem」リンクからHDFSの中が照会できるので、そちらの方が完成度は高いですが
当ツールではシーケンスファイルの中身も簡単に見られます!(笑))
このライブラリーを使わなくても、ScalaのREPL上でHadoopのクラスをそのまま使うことが出来る。[2011-10-03]
ただ、その場合はHadoopのクラス(Javaのクラス)をそのまま使うことになり、色々と面倒なので、便利なメソッド(というか、自分が使いたいと思った処理)を用意するライブラリーを作った。
このライブラリーでは、HadoopのPathのラッパーのようなクラスを作って、そこにメソッドを色々用意している。
Scalaではpimp my libraryパターン(暗黙変換)によって、既存クラスに独自メソッドを追加する(ように見せる)ことが出来る。
つまり今回の場合は、HadoopのPathにメソッドを追加する形でも良いわけである。
そうしなかった理由は、REPLではメソッドを補完する(変数にピリオドを付けてからタブキーを押すと、そのクラスのメソッド一覧が表示される)ことが出来るが、暗黙変換のメソッドは補完対象に表示されないから。
JavaのIntegerが-128〜127をキャッシュしているように、IntWritableもキャッシュして使おうと思ったのだが。[2011-10-08]
キャッシュされたインスタンスの中を更新されると困るので、setをオーバーライドして無効化しておいた。
new IntWritable(n) { private[this] val frozen = true override def set(n: Int) { if (frozen) throw new UnsupportedOperationException() super.set(n) } }IntWritable#set()はコンストラクターからも呼ばれるので、最初の1回だけは親クラスのset()を呼び出し、それ以外は例外を発生させる。
その為にfrozenというフラグを使っている。
一見、frozenにはtrueをセットしているだけなので、set()で常に例外が投げられるように見えるが、親クラスのコンストラクター呼び出し中は自分のクラスのフィールドの初期化は終わっていないので、frozenはfalseになっている。
初期化順序に依存(しかも初期化されていないフィールドを使用)していて、はっきり言って、良くないコーディング例の筆頭(爆)
ところがSequenceFileでは、念の入ったことに、書き込むクラスが指定されたクラスと完全に一致しているかどうかをチェックしている。
つまり、IntWritableの子クラスはIntWritableとして認識されない(苦笑)
SHR_CLASSPATHという環境変数を用意し、scalaコマンドの-cpにそれを指定するようにしている。[2011-10-08]
SHR_CLASSPATHで指定されている場所に入っているクラスをREPL上から使う場合は特に問題ないが、
Hadoopの場合はClassLoaderをconf(Configuration)内に保持しており、そこにはscalaの-cpで指定された場所は含まれない。
(つまり、独自Writableを含んだSequenceFileを読み込もうとした場合、SHR_CLASSPATHに入っているクラスは見つけられない。また、HADOOP_CLASSPATHに指定しても駄目だった)
confにはsetCladdLoaderというメソッドがあるので、クラスローダーを設定することが出来る。
REPLではパワーモードだとクラスローダーを取得することが出来るので、起動時にパワーモードに変更してconfに設定することにした。
:power conf.setClassLoader(intp.classLoader)