お馬鹿な実験の構想:
PCオーディオに永らく取り組み、どうしたらより良い音になるのかあれやこれやと試してきた。デジタルファイル音源の再生から徐々にストリーミングに主軸が移りつつある渦中ではあるが、PCオーディオを中心としたデジタル再生の何が(どのような要素が)再生音にインパクトを与えるのか明確に、かつ論理的に語ることは難しく、改めて自分なりに整理してみたくなった。
今や半ば常識となっているかのように巷で云われることも含めて基本的なことを実証しながら、自分でも腹に落ちるというような納得感に至れれば良いな~とも考えた。デジタルだから音は変わらない、とCDの黎明期には喧伝されそれがあっけなくひっくり返ったことはある種当然の事実とは受け止めている。だが、自分なりの試行錯誤を続ける中でも、やはりどうしても納得に至らない点が多々ある。デジタル再生に於ける音質改善について論理的に整理され合点が行くような情報は実際はあまりなく、音の表現として感覚的な言葉でのみ語られていることが多い。それらをとりあえずはできる範囲で検証しながら評価できるだろうか、というもの。
コンピュータにおける演算処理に馴染んで来た自分としては、デジタルオーディオの世界であっても、絶対的な整合性を持つコンピュータの世界は厳然と存在しており、ある種の曖昧さを残したオーディオ世界とどこかに分界点があるんじゃないか、とも考えてきた。本件のきっかけは、先に行ったサーバーPC(NAS見合い)の
実験
で自分なりに有意差が認識できなかったこともあって、これをもう少し突き詰めてみたいと考えていること。また、LANケーブルのメタルと光の違い、あるいはLAN速度の違い、ハブによっても音が変わる、という辺りの因果関係については腑に落ちない疑問点も残っていることなどなど。
一方で、音の評価はまた世の一般的な理解と一致しなければ、共感を得られないこともある(だが、オーディオもシズルを売るビジネスであることを理解しておく必要があると思う)。
そこで、まずは言葉の定義や仮説を立ててみた。
(言葉の定義)
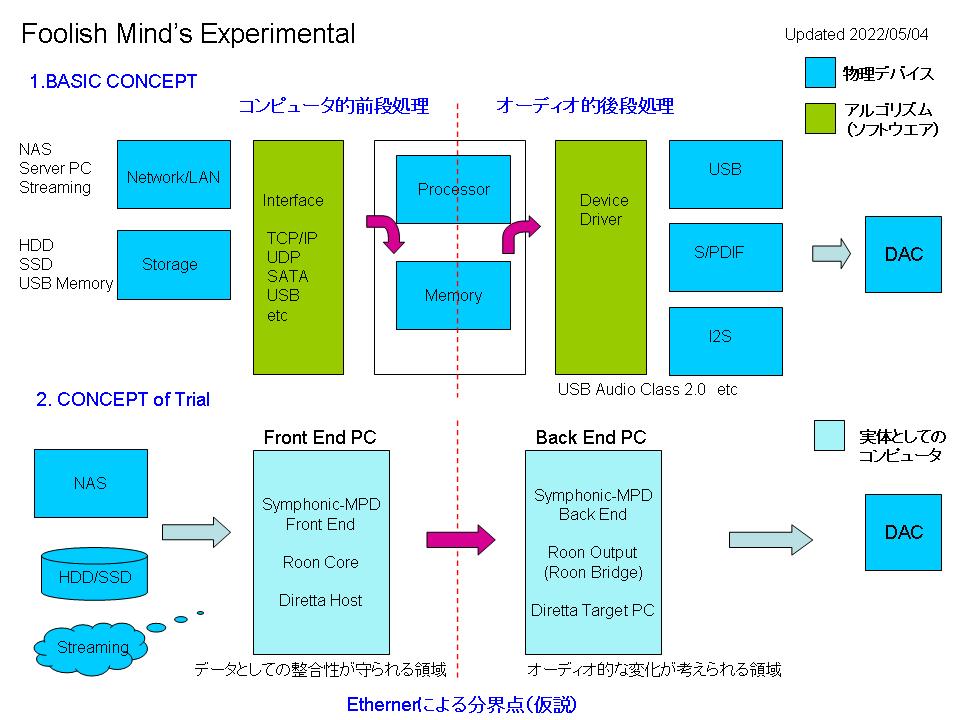
1.コンピュータ的前段処理
デジタル音源をデータ(あるいはファイル)として扱う領域。これを自分なりの表現ではあるが「コンピュータ的前段処理」と呼ぶことにする。コンピュータ的前段処理とはプロセッサー等によって(以下2.の)演算処理が行われる直前までとし、この処理に用いられるメモリー領域にデータがストアーされるまでとする。この部分はネットワーク上の伝送や各種ストレージからの読み出し等がメインとなる。
2.オーディオ的後段処理
メモリー領域にストアーされたそのデジタル音源データをオーディオ用のデジタル信号(S/PDIF、I2S、USBなど)に変換し、デバイスドライバーを経て実際の出力デバイスに渡す領域。さらにDACによってアナログ信号に変換する部分を含めて「オーディオ的後段処理」と呼ぶことにする。
実験コンセプト:
(仮説)
仮説1:コンピュータ的前段処理はその演算処理がどのようなプロセッサー(やハードウエア)ならびにOSやアプリケーションによって実行されようとも必ず一義的でなければならない。(結果が異なることはない = データとしての整合性は必ず守られる)
(注記)演算処理でもそれが「まるめ」のような処理が行われるケースであれば結果が異なることがあるかもしれない。だが、ここでは音源となるデジタルデータをメモリ領域に展開するまでを指しているので、この時点で結果が異なるようなことがあればそれはここで云うコンピュータ的な演算処理ではなくなる、の意。
仮説2:このメモリ領域上のデジタルデータをデジタルオーディオ信号に変えていく処理、さらにその後段のデジタルオーディオ信号をアナログ信号に変換する処理においては種々の要因によって異なる結果となる可能性がある。要因として(現時点で)考えらえることは、演算アルゴリズムの違い、デバイス性能の差異、また何らかの信号の劣化が電源系ノイズ(含む直流リップルノイズ)、電圧変動、クロック精度、外部振動などによって引き起こされる。D/A変換処理においては、デジタル信号が仮に厳密に同一であったとしてもデバイスを含めた性能や処理内容(アルゴリズム)の差異によってアナログ信号が完全に同一となることは無い(=DACの違いによる音の差は顕著にある、の意)。
仮説3:ただし、1.の処理の過程で自ずと発生してしまう種々の要因によって、2.の結果にインパクトを与えるような事象が起こる可能性がある。処理タイミングの許容限界や揺らぎ、遅延などハードウエア、ソフトウエア依存のもの、またプロセッサー等から発せられる高周波ノイズ、あるいは電源系ノイズや電圧変動の発生などがその要因として考えられているが、その要因の量と音質の因果関係は重層的で明確には究明されていない。
PCやネットワークオーディオ機器は、上記で仮説としている「コンピュータ的前段処理」と「オーディオ的後段処理」がひとつの機器の中で混然一体となってしまっているケースがほとんどでその場合は役割、機能を明確に分離できない。従い、それによって「音の変化」がどのような要因によって起こっているのか判然としない、論理的に説明しにくい、納得しにくいということにも繋がる。
この辺りをどうやったら明確に機能として分離した上で実験できるのか、改めて考えてみると一つの可能性ではあるが現状では意外と簡単にできるのでは? との思いに至った。例えば、当方が愛用してるSymphonic-MPDのフロントエンドとバックエンドの構成は論理的分離に近い考え方ができる。また、一般的なRoonもCoreとRoon Bridge(出力デバイス)の構成に置き換えてみればほぼ該当するし、DirettaもホストとターゲットPCの構成を眺めてみれば、この構図が成り立つようにも思える。いずれもがネットワーク(LAN = Ethernet)によって機能が分離されており、分界点が明確になっていると考えられる所以である(Ethernet自体はそれがTCP/IPあるいはUDPのどちらのプロトコルを使用する場合であってもコンピュータ処理の世界である、との認識から)。
このため、いずれの構成でも、コンピュータ的前段処理はSymphonic-MPDの場合はフロントエンドの処理、RoonならCoreでの処理、Direttaならホストでの処理という括りで考えれば良いだろう。そしてオーディオ的後段処理はバックエンド、Roon Brdige、Diretta Target PCである。この前段と後段は云うなればコンピュータ同士がネットワークで接続(実際のプロトコルやデータフォーマット、伝送タイミング等は固有であるが)された、単なるデータの受け渡し処理である。そして、デジタルオーディオに固有のクロック信号(≠サンプルレート)はこの間では受け渡されていない(クロックが打たれるのは後段処理である。この点は重要だと思う)。
そこで、上記の仮説を検証するためにはまず「オーディオ的後段処理」の機器や構成、設定パラメータなどを一切変えずに、コンピュータ的前段処理の環境を変えてみる、という実験ができる。もちろんすべてのケースを実施することはすぐにはできないので、まずはSymphonic-MPDにおけるバックエンド(オーディオ的後段処理)を設定値を含めて固定し、コンピュータ的前段処理となるフロントエンド周りの(主にハードウエア的な)環境をいろいろと変えてみる。(ただし、今回の実験ではOSとしてはシンプル軽量なArch Linux、アプリケーションとしてはSymphonic-MPDを前提とする)
取り敢えず思い付いた実験内容は以下の通り(順不同思いつくまま、もっといろいろと考えられるかと思う)
実験1:音源データの取り込み先をサーバーPC(NAS相当)とした上で
(1)サーバーPC(NAS)のプロセッサー速度を変える(1対2程度の比で)
(2)音源の置いてあるデバイスをHDD、SSDと変える
(3)音源の置いてあるデバイスをSATA(内蔵)、USB(外付け)と変える
(4)サーバーPCの機種(ハード)を変える(プロセッサーやマザーボード、メモリが変わる)
(5)サーバーPCをラズパイ4に変える(プロセッサー速度は同一レベルの設定)
実験2:音源はサーバーPCではなく、フロントエンド直下とする構成で
(1)フロントエンドPCのプロセッサー速度を変える(1対2程度の比で)
(2)音源の置いてあるデバイスをHDD、SSDと変える
(3)音源の置いてあるデバイスをSATA(内蔵)、USB(外付け)と変える
(4)フロントエンドPCの機種(ハード)を変える(プロセッサーやマザーボード、メモリが変わる)
(5)フロントエンドをラズパイ4に変える(プロセッサー速度は同一レベルの設定)
実験3:ハブ周り
(1)ハブの通信速度を変える(100M、1G)(注)オーディオ用ハブに変えてみたいが現状環境無し
(2)フロントエンド、バックエンドは直結としハブを介在させない(ハブによる劣化要因の有無)
実験4:LANケーブルをメタルから光に変える (注)光ファイバー対応の環境は現状無し
(注記1)なお当然ながらバックエンド側の性能によっては、本来これら前段の何らかの可変要素によって起っているはずの変化を表現できない、という可能性(危険性)はある。しかしながら、Symphonic-MPDのバックエンドとして使用しているものは、高精度クロックへの換装、プロセッサー周りとクロックへ個別のアナログ安定化電源を供給、各種ノイズ対策など考えられる武装は施してあるものなので、一応実験としては成り立つものと考えた。同様に更に後段となる下流オーディオ機器(デジチャン~アンプ~スピーカー)の能力にも依存する。何よりも重要なポイントは、音の変化を聴き分ける自分の判別能力であるが、これは正直心許ないので正しい答えにはならないかもしれないと思う。また、現有機器の関係から上記すべての実験はすぐにはできないし、冗長的な実験内容もあるので、多少の割愛も必要かも。
(注記2)サーバーPC、フロントエンドPCについては、いろいろと対策を行ったファンレスPCとノーマルPCを使い分ける方法で逆説的にその対策の効果を検証する。なお、追加の実験として、ある程度最適解と思われるフロントエンドの構成があぶり出せた段階で、今度はバックエンドを各種対策実施済のものから素の状態のバックエンドに切り替えることでバックエンド側での音質に係わる対策の検証ができるかもしれない。
ここまで考えてみて、仮説1.に対する実験として充分かどうか、また意味のある実験環境か、など正直多少の疑問も無しとはしないが、まずはやって見ることが先決だろう。結果として何か見えてくるものがあるかもしれない。だが、おそらく難しいのは仮説3.の部分の検証だろうな~と思う。ここに至らないと音が変わるという「発生メカニズム」、「要因分析」、「改善施策(のイメージ)」には昇華できなさそう。まぁ、まずはできる範囲で、多少なりとも切り分けができれば、というスタンスでもやむを得ないか。
4way MW16TX構成の設定値(2022年3月10日更新)
| 項目 |
帯域 |
備考 |
| Low |
Mid-Low |
Mid-High |
High |
使用スピーカー
ユニット |
- |
Sony
SUP-L11 |
SB Acoustics
MW16TX |
Sony
SUP-T11 |
Scan Speak
D2908 |
- |
能率
能率(90dB基準相対差) |
dB |
97.0 (+7.0) |
87.5 (-2.5) |
110.0 (+20.0) |
93.0 (+3.0) |
|
DF-65の
出力設定 |
dB |
+1.0 |
+1.0 |
-9.0 |
+4.0 |
|
マスターボリューム
アッテネーション |
dB |
-9.0 |
-2.0 |
-3.0 |
-0.0 |
|
パワーアンプでの
GAIN調整 |
dB |
0 |
0 |
-12.0 |
-12.0 |
|
スピーカーの
想定出力レベル |
dB |
89.0 |
86.5 |
86.0 |
85.0 |
|
クロスオーバー
周波数 |
Hz |
~
140 |
140
~
560 |
560
~
3150 |
4000
~
|
High Pass
~
Low Pass |
スロープ特性
設定 |
dB/oct |
flat-18 |
48-48 |
48-24 |
24-flat |
|
DF-55 DELAY
設定 |
cm |
-8.0 |
+19.5 |
-37.0 |
+25.0 |
相対位置と
測定ベース |
| 極性 |
- |
Norm |
Norm |
Norm |
Norm |
|
DF-55 DELAY COMP
(Delay自動補正) |
- |
ON |
自動補正する |
DF-55デジタル出力
(Full Level保護) |
- |
OFF |
保護しない |
|