ポート数
の制約
ポート数
の制約
に対する
出力レコード数
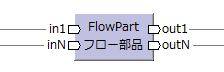
(0〜∞レコード)
Asakusa FrameworkのOperator DSLのフロー演算子(FlowPart)のメモ。
|
フロー演算子は、演算子を組み合わせて1つの演算子のように扱う演算子。
性能特性は中身次第。
| 入力 ポート数 |
入力データモデル の制約 |
イメージ | 出力 ポート数 |
出力データモデル の制約 |
入力1レコード に対する 出力レコード数 |
|---|---|---|---|---|---|
| 任意 |
|
任意 | 任意。 (0〜∞レコード) |
フロー演算子はサブルーチンのようなもの。
複数の演算子を1つのフロー演算子にまとめることにより、Flow DSLがシンプルになる。
AsakusaFWによってフローがコンパイルされるときには、フロー演算子の中身が外側に展開される。(各演算子の最適化は展開後に行われる)
したがって、実行時には、フロー演算子があることによる影響は全く無い。
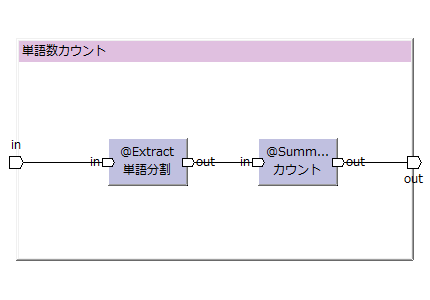
WordCountを行うフロー演算子の例。
WordCountのフロー演算子の定義(中身)は以下のようになる。
(この図はToad Editorを用いて作っています)
| 入力データ例 | 中間データ例 | 出力データ例 | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| in |
|
→ | out |
|
in | → | out |
|
||||||||||||||||
"テキスト"
text_model = {
"テキスト"
text : TEXT;
};
"単語"
word_model = {
"単語"
word : TEXT;
};
"単語数"
summarized word_count_model = word_model => {
"単語"
any word -> word;
"件数"
count word -> count;
} % word;
import java.util.StringTokenizer; import com.asakusafw.runtime.core.Result; import com.asakusafw.vocabulary.operator.Extract; import com.asakusafw.vocabulary.operator.Summarize; import com.example.modelgen.dmdl.model.TextModel; import com.example.modelgen.dmdl.model.WordCountModel; import com.example.modelgen.dmdl.model.WordModel;
public abstract class WordCountOperator {
private WordModel word = new WordModel();
/**
* 単語分割
*
* @param in
* テキスト
* @param out
* 単語
*/
@Extract
public void split(TextModel in, Result<WordModel> out) {
String text = in.getTextAsString();
StringTokenizer tokenizer = new StringTokenizer(text);
while (tokenizer.hasMoreTokens()) {
word.setWordAsString(tokenizer.nextToken());
out.add(word);
}
}
/** * カウント * * @param in * 単語 * @return 単語数 */ @Summarize public abstract WordCountModel count(WordModel in); }
Operatorに書くのはフロー演算子の中から使用するもの。(フロー演算子の定義とは関係ない)
package com.example.wordcount.flowpart;
import com.asakusafw.vocabulary.flow.FlowDescription; import com.asakusafw.vocabulary.flow.FlowPart; import com.asakusafw.vocabulary.flow.In; import com.asakusafw.vocabulary.flow.Out; import com.example.modelgen.dmdl.model.TextModel; import com.example.modelgen.dmdl.model.WordCountModel; import com.example.wordcount.WordCountOperatorFactory; import com.example.wordcount.WordCountOperatorFactory.Count; import com.example.wordcount.WordCountOperatorFactory.Split;
@FlowPart
public class WordCountFlowPart extends FlowDescription {
private final In<TextModel> in;
private final Out<WordCountModel> out;
public WordCountFlowPart(
In<TextModel> in, Out<WordCountModel> out ) { this.in = in; this.out = out; }
@Override
public void describe() {
WordCountOperatorFactory operators = new WordCountOperatorFactory();
// 単語分割
Split split = operators.split(this.in);
// カウント
Count count = operators.count(split.out);
this.out.add(count.out);
}
}
フロー演算子では、Flow DSLで処理を記述する。
フロー演算子の単体テストの実装例。
フローのテストになるので、テストドライバーを使い、入出力データを用意する必要がある。
フローのテストはスモールジョブ実行エンジンで実行される。(AsakusaFW 0.5.1の頃はHadoopを使って実行されていたので、色々環境整備しないとWindowsでは実行できなかった)[/2017-06-03]
入力データおよび出力データの検証用データ・検証ルールをExcelファイルで指定する。
DMDLをコンパイルすると、プロジェクト/target/excel(gradle版の場合はプロジェクト/build/excel)の下にExcelファイルの雛形が生成される。
これをsrc/test/resourcesの下のフロー演算子のパッケージ名と同じ場所にコピーし、その中にデータを記述する。
| A | B | C | |
| 1 | text | ||
| 2 | Hello Hadoop World | ||
| 3 | Hello Asakusa | ||
| 4 | |||
| 5 |
入力データはinputシートに書く。
1行目(色付きのセル)は自動で入っている。
| A | B | C | |
| 1 | word | count | |
| 2 | Asakusa | 1 | |
| 3 | Hadoop | 1 | |
| 4 | Hello | 2 | |
| 5 | World | 1 | |
| 6 |
期待される出力データをoutputシートに書く。
1行目(色付きのセル)は自動で入っている。
| A | B | C | D | E | |
| 1 | Format | EVR-1.0.0 | |||
| 2 | 全体の比較 | 全てのデータを検査 [Strict] | |||
| 3 | プロパティ | 値の比較 | NULLの比較 | コメント | |
| 4 | word | 検査キー [Key] | NULLなら常に失敗 [DA] | 単語 | |
| 5 | count | 完全一致 [=] | NULLなら常に失敗 [DA] | 件数 | |
| 6 |
outputシートに書かれているデータと実際のデータをどう比較してどういう状態ならテストOK(あるいはNG)とするかをruleシートに書く。
どのセルも初期値は自動で入っている。
(「コメント」の“単語”や“件数”は、DMDLに自分が記述した各項目のコメント)
今回のケースでは出力項目がwordとcountの二項目なので、それぞれどういう比較をするかを書く。(書くというか、実際はプルダウンになっているので、選択する)
※ExcelファイルをEclipse外のエディターで編集したら、Eclipse上でF5を押して反映させる(srcからclassesへコピーさせる)必要がある。
package com.example.wordcount.flowpart;
import org.junit.Test; import com.asakusafw.testdriver.FlowPartTester; import com.asakusafw.vocabulary.flow.FlowDescription; import com.asakusafw.vocabulary.flow.In; import com.asakusafw.vocabulary.flow.Out; import com.example.modelgen.dmdl.model.TextModel; import com.example.modelgen.dmdl.model.WordCountModel;
/**
* {@link WordCountFlowPart}のテスト.
*/
public class WordCountFlowPartTest {
@Test
public void describe() {
FlowPartTester tester = new FlowPartTester(getClass());
In<TextModel> in = tester.input("in", TextModel.class).prepare("text_model.xls#input");
Out<WordCountModel> out = tester.output("out", WordCountModel.class).verify("word_count_model.xls#output", "word_count_model.xls#rule");
FlowDescription flowPart = new WordCountFlowPart(in, out);
tester.runTest(flowPart);
}
}
フロー演算子のテストにはFlowPartTesterを使う。
tester.input()で入力データを指定する。
第1引数はフロー演算子で指定した入力データの名前。つまりWordCountFlowPartのコンストラクターの変数名。
そのinput()メソッドの後に続いているprepare()で、入力データのExcelファイル名およびシート名を指定する。
tester.output()で出力データを指定する。
第1引数はフロー演算子で指定した出力データの名前。つまりWordCountFlowPartのコンストラクターの変数名。
verify()メソッドの第1引数が出力データのExcelファイル名およびシート名、第2引数がチェック用ルールのExcelファイル名およびシート名。
tester.runTest()にフロー演算子のオブジェクトを渡すとテストが実行される。
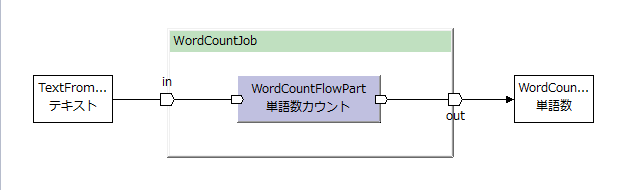
定義したフロー演算子を使う側(ジョブフローや別のフロー演算子)の実装例。
import com.asakusafw.vocabulary.flow.FlowDescription; import com.asakusafw.vocabulary.flow.In; import com.asakusafw.vocabulary.flow.Out; import com.example.modelgen.dmdl.model.TextModel; import com.example.modelgen.dmdl.model.WordCountModel; import com.example.wordcount.flowpart.WordCountFlowPartFactory; import com.example.wordcount.flowpart.WordCountFlowPartFactory.WordCountFlowPart;
@Override
public void describe() {
WordCountFlowPartFactory wordCountFlowPartFactory = new WordCountFlowPartFactory();
// 単語数カウント
WordCountFlowPart wordCount = wordCountFlowPartFactory.create(this.in);
this.out.add(wordCount.out);
}
Flow DSLでは、自分が作ったFlowPartのFactoryクラス(AsakusaFWのコンパイラーによって生成される)を使用する。
メソッド名は常にcreate。
戻り値の型はAsakusaFWのコンパイラーによって生成されたクラス。(フロー演算子のクラス名と同じ。(名前は同じだが別物なので注意))
フロー演算子の出力ポートの名前は、FlowPartのコンストラクターに記述した変数名。