CascadingのFlowクラスについて。
|
|
Cascadingにおいて、入力Tap(source)と出力Tap(sink)とパイプを結び付け、実際にMap/Reduceの実行を行うのがFlow。
import cascading.flow.Flow; import cascading.flow.FlowConnector;
FlowConnector flowConnector = new FlowConnector();
Flow flow = flowConnector.connect("フロー名", source, sink, pipe);
flow.complete(); //実行開始
Flowを1つのプログラムの中で同時に複数指定する事が出来る。[2010-04-27]
パイプも分岐によって並列な処理を記述できるが、実際の実行は並列でなく、適当な順番で直列(シーケンシャル)に実行される(と思われる)。
フローの場合は本当に並列で実行される(らしい)。
例えばFlowAがtap1へ出力してFlowBがtap1を入力としていると、FlowAが実行されてからFlowBが実行される。
FlowAとFlowBの入出力に関係が無ければ、並列で実行される。
また、出力が新しくならない場合はフロー実行されないこともあるらしい(?)。
import cascading.cascade.Cascade; import cascading.cascade.CascadeConnector; import cascading.flow.Flow; import cascading.flow.FlowConnector; import cascading.scheme.SequenceFile; import cascading.scheme.TextLine;
// pipe1からpipe11,pipe12へ分岐
Pipe pipe1 = new Pipe("pipe1");
Pipe pipe11 = new Pipe("pipe11", pipe1);
〜
Pipe pipe12 = new Pipe("pipe12", pipe1);
〜
// pipe11の結果をpipe21で処理
Pipe pipe21 = new Pipe("pipe21");
〜
// pipe12の結果をpipe22で処理
Pipe pipe22 = new Pipe("pipe22");
〜
// sourceとsinkの設定
Tap source1 = new Hfs(new TextLine(new Fields("line")), args[0]);
Tap tap11 = new Hfs(new SequenceFile(new Fields(保存する項目)), "temp1");
Tap tap12 = new Hfs(new SequenceFile(new Fields(保存する項目)), "temp2");
Tap sink21 = new Hfs(new TextLine(), args[1], SinkMode.REPLACE);
Tap sink22 = new Hfs(new TextLine(), args[2], SinkMode.REPLACE);
// フローの構築
Map<String, Tap> taps = new HashMap<String, Tap>();
taps.put(pipe11.getName(), tap11);
taps.put(pipe12.getName(), tap12);
FlowConnector flowConnector = new FlowConnector();
Flow flow1 = flowConnector.connect("flow1", source1, taps, pipe11, pipe12);
Flow flow21 = flowConnector.connect("flow21", tap11, sink21, pipe21);
Flow flow22 = flowConnector.connect("flow22", tap12, sink22, pipe22);
Cascade cascade = new CascadeConnector().connect(flow1, flow21, flow22);
cascade.complete(); //実行
| source1 | flow1 | |
| ↓ | ||
| pipe1 | ||
| ↓ | ↓ | |
| pipe11 | pipe12 | |
| ↓ | ↓ | |
| tap11 | tap12 | |
| ↓ | ↓ | flow21,flow22 |
| pipe21 | pipe22 | |
| ↓ | ↓ | |
| sink21 | sink22 | |
あるパイプから出力し、別のパイプの入力とするTap(上記のtap11,tap12)は、TextLineでなくSequenceFileを使うようだ。
SequenceFileのfieldsには、パイプから出力する項目(次パイプの入力となる項目)を指定する。
フロー(FlowConnector#connect())自体は、通常のフローの作り方と同じ。
それを実行する為にCascadeというクラスに一旦まとめる。
CascadeConnector#connect()には、フローを順不同で指定する。実行順序は内部で勝手に決めてくれる。
Cascadingの内部では、パイプ(とsource・sink)を実行順序で並び替えた、有向グラフ(向きの指定のあるグラフ(ノードと矢印))を作っている。
(この為にjgrapht-*.jarが使われている模様)
Flowでは、その有向グラフのデータであるdotファイルを生成することが出来る。
そしてこのdotファイルから、有向グラフの実際の図を生成することが出来る。(→Graphvizというツールを使用)
例えばWordCountサンプルの有向グラフを出力するには、以下のようにする。
(complete()を呼んでMap/Reduceを実行する代わりに、writeDOT()でdotファイルを出力する)
FlowConnector flowConnector = new FlowConnector();
Flow flow = flowConnector.connect("wordcount", source, sink, pipe);
// flow.complete();
flow.writeDOT("C:/temp/graphviz/wordcount.dot");
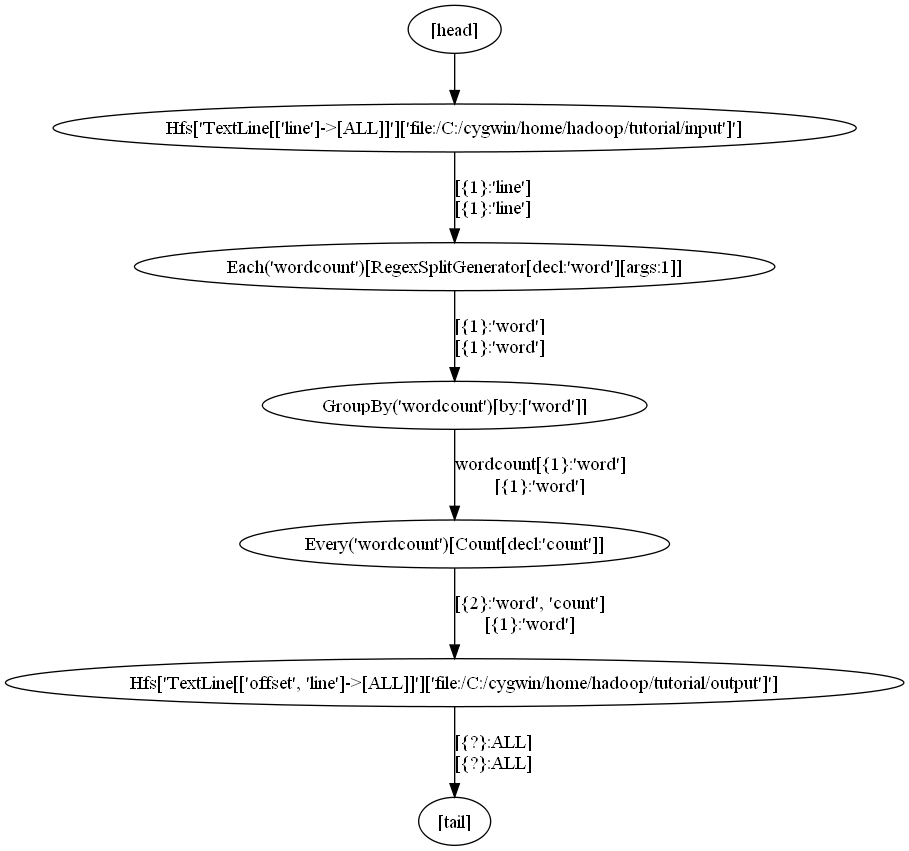
↓(wordcount.dot)
digraph G {
1 [label = "Every('wordcount')[Count[decl:'count']]"];
2 [label = "Hfs['TextLine[['offset', 'line']->[ALL]]']['file:/C:/cygwin/home/hadoop/tutorial/output']']"];
3 [label = "GroupBy('wordcount')[by:['word']]"];
4 [label = "Each('wordcount')[RegexSplitGenerator[decl:'word'][args:1]]"];
5 [label = "Hfs['TextLine[['line']->[ALL]]']['file:/C:/cygwin/home/hadoop/tutorial/input']']"];
6 [label = "[head]"];
7 [label = "[tail]"];
1 -> 2 [label = "[{2}:'word', 'count']\n[{1}:'word']"];
4 -> 3 [label = "[{1}:'word']\n[{1}:'word']"];
3 -> 1 [label = "wordcount[{1}:'word']\n[{1}:'word']"];
6 -> 5 [label = ""];
2 -> 7 [label = "[{?}:ALL]\n[{?}:ALL]"];
5 -> 4 [label = "[{1}:'line']\n[{1}:'line']"];
}
↓(Gveditによる画像化)
丸で囲まれているのが処理(主にパイプ)。
sourceやsinkも出ている。(中間ファイル出力がある場合はTempHfsも出てくる)
矢印の脇に出ているのが、出力項目名。各項目名の左側のとげ括弧で囲まれている数字は、項目数。
上段がグループキー項目名(たぶんFields.GROUP(もしかするとFields.ALL)で取得できる項目)、下段が値項目名(たぶんFields.VALUESで取得できる項目)。
EachではFields.GROUPもFields.VALUESも同じになる為、同じ項目名が二重に出ている。
WordCountくらいだと一本道なのでこういう図のありがたみはあまり無いかもしれないが、パイプが分岐したり結合したりしてくると、処理順序を確認するのに便利かもしれない。