ネットワークのテスト手法は状況次第でいろいろと思いますが、テストの中で下記は頻繁に行われると思います。
- PC 間の ping/traceroute
- NW 機器のステータス取得
これらの作業を楽にするために、下記のツールを作成しました。このwebページではこれらの使い方を紹介します。
- TTLGen
- RouTexDF
- exp_analyzer
- exp_remote_manager/exp_remote_agent
こうしたツールが必要となる背景を少し説明させてください。
下記のようなテスト環境があったとします。
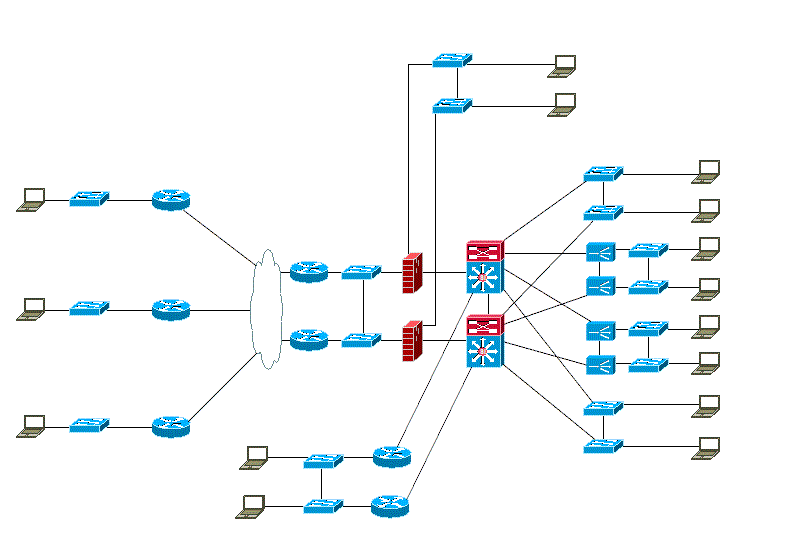
- NW機器 : 35台
- PC : 15台
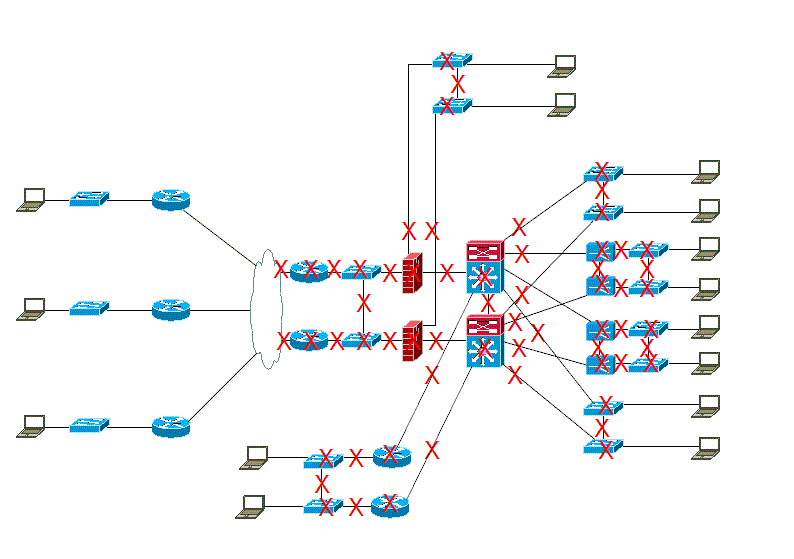
この環境で一通り障害テストを行うとして、リンク障害/機器障害はこれだけあります。 これは冗長された部分に [X] を付けただけですが、実際にはモジュール障害や冗長電源障害などもあるので、もっと増えるかもしれません。全体ではなく一部を追加構築するだけならテストケースはずっと減るでしょう。
ここでは計算しやすくするためざっくり 60 ケースと仮定します。
ひとつの障害ケースの中では下記の作業を行うと仮定します。
- 障害発生時の ping 断時間を確認
- 障害発生時の traceroute を確認
- 障害発生時の機器ステータスを確認
- 障害復旧時の ping 断時間を確認
- 障害復旧時の traceroute を確認
- 障害復旧時の機器ステータスを確認
上記の確認を行うにあたって、ログの取得回数は下記になります。
- ping の取得 : 1ケースあたり2回 * 60 ケース * 15台 = 1800
- traceroute の取得 : 1ケースあたり2回 * 60 ケース * 15台 = 1800
- NW機器ステータスの取得 : 1ケースあたり2回 * 60 ケース * 35台 = 4200
上記のような作業を手作業でやろうとするのは現実的ではなく、多くの方が何らかのツールで作業の自動化を図っていると思います。
手間の問題だけでなく、自動化しないとログの取得漏れが多く発生すると予想されます。 テストが終わってからログ欠けが発覚し、手戻った経験は誰にでもあると思います。テスト環境が残っていればまだ良いですが、環境をバラした後だったりすると目も当てられません。
上記のような背景があり、ツールを作成してきました。
- TTLGen
- RouTexDF
- exp_analyzer
- exp_remote_manager/exp_remote_agent
それぞれのツールは help を読んでいただければ使い方に困ることは無いと思いますが、この web ページではこれらのツールについて紹介していきます。
また、exp_remote_manager/exp_remote_agent については、使い方を説明しています。
ひとつ注意していただきたいことがあります。
こうしたツールを利用したテスト手法の改善はあくまで戦術の話であり、スケジュールや人員アサインといった戦略上の問題を解決するものではありません。
つまり、「テスト手法を改善すればスケジュールを短くできる/人を減らせる。」と考えることは非常に危険です。
それでは、ツールを利用したテスト手法の改善は何をもたらすのでしょうか?
個人的には下記のように考えています。
- ログ/エビデンスの漏れによる手戻りの回避。
- 手を動かす時間を減らし、考える時間を増やす。
- 作業メンバーの疲弊の回避。(人は疲れてくるとデタラメになりますが、それを責めることはできません。)
それともうひとつ。
ここに書かれた手法よりもっと良い手法があると思っていますので、そうした話があればぜひ聞いてみたいと思っています。