 ���ő����������G���{�ꏈ�����t����
���ő����������G���{�ꏈ�����t����
�b�́A�܂��A�����߂�B
���́A�P�X�V�Q�N�����A�B��A���R����|�|�b�{�{�A�i�������Ȃnjv�Z�@����ɑ��āA���{��A�p��̂悤�ɐl�Ԃ��]���p���Ă�������������Ăԁ|�|�̌������s���Ɩ��������X����̂��铌�łɍs�����ƂɌ��߂��B�P�X�V�R�N�t�A���͓����ɗ����B���łɓ��Ђ��A�V�l���C�̔��N���������Ă����B���N��A�͓c����Ƒ������������V�X�e���������̐X����̌������ōĉ�A��l�̋����������n�܂����B�Ƃ͌����Ă��A���́A���x�͌��������ł̋���ł���B���̌������̓p�^�[���F������e�[�}�Ƃ��Ă����B����̓A���S�����̌���������A�����̓\�t�g�������čs���B�������A�����F���A�摜�F���Ȃǂ̓\�t�g�����ł͍ς܂��A��p�n�[�h�����������ō��Ȃ���Ȃ�Ȃ��B�����̔ėp�v�Z�@�ł͒x������̂ł���B�����ŁA�V�l�͕K���A�n�[�h�����鎖������̈�e�[�}�ł������B
TOSBAC40�ɂ͂��̂悤�ȃ{�[�h�̏�ŃR���g���[����H��
���o�X�ɑ}���BPC��PCI�o�X�ɑ}���J�[�h�ɑ�������B
 ���́A�J�Z�b�g�e�[�v�h���C�u���~�j�R���s���[�^�Ɏ��t�����B�o�b�ɃJ�Z�b�g�h���C�u�����t����̂Ƃ͖Ⴄ�B�o�b�Ȃ�A���������J�[�h�̃R���g���[���������Ă����ɃR�l�N�^���������ނ��i�������ɃJ�Z�b�g�͂����Ȃ����낤�B����A�c�`�s�ł���j�A�����̃~�j�R���i�o�b�͂P�X�W�P�N�ɂȂ�Ȃ���Ό���Ȃ��j�ɂ͂���Ȏ�y�Ȃ��͖̂����B�܂��A�o�X�ɍ����R���g���[���̐v����n�܂�B�o�X�̃^�C�~���O�`���[�g���ɂ�݂Ȃ���v�B��Ղɂh�b�������Č�������B�h�b�Ƃ����Ă��A�Q�[�g���S�����������Ă��Ȃ����̂��B�k�r�h�ł͂Ȃ��B������Y���b�ƕ��ׂČ������Ă����B���ꂪ�o������A�o�X�ɂ����A�~�j�^���[�̏㔼��������ʂ̑傫���̂���A�R�O�O���~������J�Z�b�g�e�[�v�h���C�u�ɂȂ��B�W�O�N�㔼�̂l�r�w�̃p�\�R���ɕt�����J�Z�b�g�h���C�u�͂Q�����x���������B�B�B
���́A�J�Z�b�g�e�[�v�h���C�u���~�j�R���s���[�^�Ɏ��t�����B�o�b�ɃJ�Z�b�g�h���C�u�����t����̂Ƃ͖Ⴄ�B�o�b�Ȃ�A���������J�[�h�̃R���g���[���������Ă����ɃR�l�N�^���������ނ��i�������ɃJ�Z�b�g�͂����Ȃ����낤�B����A�c�`�s�ł���j�A�����̃~�j�R���i�o�b�͂P�X�W�P�N�ɂȂ�Ȃ���Ό���Ȃ��j�ɂ͂���Ȏ�y�Ȃ��͖̂����B�܂��A�o�X�ɍ����R���g���[���̐v����n�܂�B�o�X�̃^�C�~���O�`���[�g���ɂ�݂Ȃ���v�B��Ղɂh�b�������Č�������B�h�b�Ƃ����Ă��A�Q�[�g���S�����������Ă��Ȃ����̂��B�k�r�h�ł͂Ȃ��B������Y���b�ƕ��ׂČ������Ă����B���ꂪ�o������A�o�X�ɂ����A�~�j�^���[�̏㔼��������ʂ̑傫���̂���A�R�O�O���~������J�Z�b�g�e�[�v�h���C�u�ɂȂ��B�W�O�N�㔼�̂l�r�w�̃p�\�R���ɕt�����J�Z�b�g�h���C�u�͂Q�����x���������B�B�B
TOSBAC40�i�ʐ^�͌�p�@TOSBAC40D�j
PC�Ō����x�A�{�[����MPU�A
��L����t���������̂��́B
OS�Ƃ������̂͑��݂����A���삵���B

���āA�n�r�ȂǂȂ�����A�h���C�o�𗇂̏�Ԃ�����Ȃ���Ȃ�Ȃ��B�ܘ_�A�A�Z���u���ł���B�����Ȃ��ƁA�h���C�o�������̂��R���g���[���������̂������ς�킩��Ȃ��B���̐蕪��������̂���ςł���B�V���N���X�R�[�v���ɂ݂Ȃ���v���[�u���h�b�̑��ɕt���A�P�Q�[�g���M�����łĂ���̂��m���߂Ă����B��J�ɋ�J���d�˂Ă���Ɖғ������鎖���o���A�l�s�|�n�r�̂悤�Ȃ��̂�������B�����̃~�j�R���V�X�e���͎��e�[�v���L���}�̂ł���B�v���O�����͎��e�[�v�Ƀp���`���ꂽ���Ńr�b�g��\�����ċL������Ă����B�]���āA�v���O�����̍쐬�A�C���A�ۑ��A�ǂݍ��݂Ȃǂ��s���v���O�����͂��ׂĎ��e�[�v����o�͂Ƃ��ď�����Ă���B�\�[�X�ȂǂȂ�����A�������t�A�Z���u�����Ď��e�[�v����̓��o�͕��������C�e�[�v�ł̓��o�͂ɕϊ����Ă������B�����̃v���O�����͏��Ȃ���L���ʼnғ�����悤�ɐ��k�ȋZ�p��p���ď�����Ă���̂ŁA���o�̓T�u���[�`���Ƃ����܂Ƃ܂����P�ʂł��ꂢ�ɏ�����Ă��炸�A�ǂ��ɓ��o�͕�����������Ă��邩��T���o�������ł���ςȎd���ł������B�u�v���O�����̒��Ŏ������g�̖��߂�����������v���O�����̓o�O��肪��ς��������Ă͂����Ȃ��v�ȂǂƁA���ł͍l���������Ȃ��e�N�j�b�N���s���Ă�������ł���B
���̍��A���a�S�O���������T�����͂���Q�l�a�̃n�[�h�f�B�X�N�i���̍��̃f�B�X�N�͂܂������[�o�u���ł���B�o�b�̂g�c�c�̂悤�ȃE�B���`�F�X�^�^�g�c�c���o��̂͂܂���̎��ł���j���ׂ̃`�[���ɓ����ė����B���x�͂c�n�r���ł���B���̂l�s�|�n�r�̐��ʂ�p���āA�摜�O���[�v�̖��c��������B���̃f�B�X�N�h���C�u�̕��͐���@�ʂ̑傫���ł������B
�������ē��ЂP�N�ڂ��I������B���̍��A�X�����under-the-table�����Ƃ������Ƃ�������Ɍ����Ă����B���R����̌����́A�܂��������̐����e�[�}�ɂȂ��Ă͂��Ȃ��Bunder-the-table�Ȃ̂ł���B�����Ƃ������̂́A��Ƃł���w�ł��X�P�W���[���Ƃ������̂�����B�ł��邩�ǂ���������Ȃ����猤������̂ɂ�������炸�X�P�W���[���������āA���������܂łɂ����B������A�Ƃ���������Ȃ���Ȃ�Ȃ��B����͖����ł��邪�A���̒��͖����ɖ����Ă�����̂ł���B
���s�ɋ������A�������̐��c����ɂ͌����e�[�}�͕K���Q�͗p�ӂ��A�{�e�[�}���v���ɔC���Ȃ����ɔ����Ă����Ȃ���Ȃ�Ȃ��Ƌ�����Ă����B�X����͂����under-the-table�ƌĂ�ł����̂ł���B����on-the-table�����́A�����F���ł������B�����Ƃ��A���͂�����͗]�肵�Ȃ������B������͉͓c���l�ӃR�[�h�@�Ȃǂ��Ă��āA�ϋɓI�ɍs���Ă����B���́A���ʁA���{����������铹������s���Ă����B��̂c�n�r�|�|�s�n�r�o�h�b�r�|�k�Ɩ��������|�|�����̈�ł���B�͓c���H�ꂩ��A�����X����̉����Ŋ����p�^�[����A�����v�����^���d����Ă����肵���B�����v�����^�Ƃ����Ă��A���^�①�ɂ̂悤�Ȑ}�̂̏�Ƀg�C���b�g�[�p�̂悤�Ȋ��������ڂ��Ă�����x�̂��̂ł��������A�����́A�������o�邾���ł��肪���������B
���͂��̎����A�Ӗ���͂��ǂ����Ă�낤���A�Ƃ����悤�Ȏ����l���Ă����B�������ꌤ�����̕��ތ�b�\�Ƃ����A�P����Ӗ��ŕ��ނ����\�|�|�Ƃ����Ă��A�R�O�O�y�[�W�ʂ̒P�s�{�ł���|�|���ɂ߂���������𑗂��Ă����B�Ӗ���͂ǂ��납�A�����Ɗ�b�I�Ȍ`�ԑf��͂��A�\����͂��ł��Ă��Ȃ��Ƃ���ŁA�����Ȃ蔭�z���Ӗ���͂ɔ��ł��܂��Ƃ��낪��i���B�i����ǂ������j�����u���̑�w�|�b�g�o�炵���Ƃ���ł���B�V�S�N�x���I���ɋ߂Â������̂�����A�͓c���A�X�����������ϊ�������悤�Ɍ����Ă���A�ƌ����B�͓c����ɂ��A����͉͓c����̒�Ăƌ������ł���B���������̌��n����ƐX����ɉ����ł��邩�Ɩ���ċ@�B�|��Ƃ������v��Ƃ��F�X���������̈�炵���B
���������ϊ��Ƃ����̂́A���łɋ�B��w�ł��m�g�j�ł������͏I����Ă����B�ܘ_�A�������I����Ă����ƌ������ƂƁA�������������Ă���Ƃ������ƂƂ͑S�R�ʂ̘b�ł���B��w�͊�b�������I���ƁA�y�[�p�i�_���j�������ďI�����A���̃e�[�}�Ɉڂ��Ă����B��p�҂́A���̂[�p��ǂ�ŁA�����ǂ��܂ł��ǂ��܂ł͉\���Ȃǂ̖ڏ������̂ł���B�ܘ_�A�����������Ŏ~�߂Ȃ��ő��s���Ă��ǂ��̂ł��邪�A�H�w�̌������w�œO��I�ɍs���̂͂��Ȃ����B���Ƃ��A���������ϊ��ł́A���ł́A�P�O����A�Q�O����Ƃ���������p���Ă��邪�A���������ϊ����������Ă��Ȃ����_�ŁA�ǂ̂悤�ɂ��Ă��̂悤�Ȏ�������邱�Ƃ��ł���̂ł��낤���B
�����A���玚�̊����R�[�h��S���o���Ă������Z�\�҂����ĉp���L�[�{�[�h���x�̃L�[�{�[�h�Ŋ������^�b�`���b�\�h�œ��͂����Ƃ��������B�q�`�h�m�o�t�s���L���ł������B������R�[�����̂悤�ȕ������̗p���Ă����B�������đł��ꂽ�����̓L�[�{�[�h�̉��ɕt���Ă���@�B���̎��e�[�v�p���`���Ŏ��e�[�v�ɏo�͂��ꂽ�B����łȂ���A�t���L�[�{�[�h�ƌĂԂQ�玚���Ƃ��S�玚���̊����L�[����ׂ�����ȃL�[�{�[�h�Ń^�C�v���ē��͂��邵���Ȃ������B�P�Q�i�V�t�g�ȂǂƂ����������̂ł������B���͔�͂P���Q�~�ł������B���A�����p�^�[���ɂ��Ă������ɂȂ�����ł���B�f�U�C�i�[�ɂP���f�U�C�����Ă��炤�ƁA�P���~���x���������B�t���Z�b�g�ȂǂƂĂ����Ȃ��̂ł���B�P�X�V�O�N�㏉���ŁA�呲�̏��C�����T�A�U���~�ł���B���̂悤�Ȍo�ϓI�ȗ��R�������āA��b�����ŏI��鎖�����������̂ł���B
���s��w�ł͂��łɂP�X�U�O�N��ɁA���A�����A���c����炪���w���Ƌ����ŋ@�B�|��̌������I���Ă����B������łɂȂ��Ă��邩������Ȃ����A���̎��̐��ʂ��A�u�k�Ђ̃u���[�o�b�N�X����u�|��R���s���[�^�v1969.9.20�Ƃ��Ĉ�ʌ����ɂ��{���łĂ���B���������ϊ��́A�m�g�j���I�����Ă����B��w�̓����܂��ʂ��Ă��Ȃ����ЂQ�N�ڂ̎��ɂ́A����ȏ̒��ŁA�ǂ����č��A���������ϊ���������Ȃ������B�������A��ɏ������悤�ɁA���ς�炸���������ׂ̊������͂���܂Ƃ��ɂł��Ȃ�����ł������̂ł���B�Ȃɂ����������ǂ̂悤�ɂ��ē��͂���̂��A�����{���Ɏ������Ȃ���Ή������n�܂�Ȃ��̂ł���B�@�B�|��̌������A�|��Ƃ͂ǂ̂悤�ȃ��J�j�Y���ōs�����Ƃ��\�Ȃ̂��Ƃ����A���S���Y���̌����͍s���Ă��A���ۂ̓��{��̓��o�͂̓��[�}����A�J�^�J�i�ł������̂ł���B����������ɂ�������A�Ō�͐l�Ԃ���ŏ������d���Ȃ������B���̂悤�Ȏ���ł��������Ƃ𗝉����Ȃ��Ɖ��������ϊ��̐^�̈Ӌ`�͕�����Ȃ��B���̍��A�N�����������ϊ������p�ɂȂ�Ƃ͎v���Ă��Ȃ������B���̏�A�����͈�i�����ĊF�A���p���Ȃǂ͍l�����ɏI����Ă��܂��Ă���̂ł���B����������Ȃ���p�ׂ̈Ɍ����J��������̂ł���B���C�̍����ł͂Ȃ������B
���������ϊ��V�X�e����p�������[�h�v���Z�b�T���o�_���B1977�N�āA���k��w�ŊJ���ꂽ�d
�q�ʐM�w��̕���S�����Ŕ��\�B���̎������畐�c���͓c����ɑ����ĎQ�����Ă���B

����������A�P�X�V�U�N���̎��ɂȂ邪�A�{�Ђ��p�����[�h�v���Z�b�T������ƌ������Ƃ��A�m�l�|�|�N���������o���Ă��Ȃ��|�|�������Ă��ꂽ�B���ẮA�f�������ɍs���̂ňꏏ�ɍs���Ȃ����ƌ������ł������B���[�h�v���Z�b�V���O�Ƃ����T�O�́A�č��h�a�l�������U�O�N��̏I��荠�A���\���Ă����B�l�s�^�r�s�Ƃ����傫�ȃV�X�e�����������Ă����BST�iSelectric Typewriter)�ŏ������������A�l�s(Magnetic Tape)�ɋL�����čė��p����Ƃ����T�O�ł������B�l�s�ƌ����Ă��J�Z�b�g�ł͂Ȃ��B�Â߂̂r�e�f��ɏo�Ă���悤�ȁA�l�̔w��������傫�ȃh���C�u�ł���B�p��ł́A���͂ɂ͉��̍�����Ȃ��B��x�A���͂����������l�s�ɋL�^���Ă����A�ҏW���o����Ƃ������Ƃ�����I�Ȏ��������̂ł���B����܂ł̃^�C�v���C�^�ł́A�`�S�A�P���^�C�v�����Ō�̈ꎚ���ԈႦ�Ă��A�p�����邩�A�������S���ʼn����Ȃ�̂��o��ŏ��������Ȃ������̂ł���B
���̎茳�ɂ���̂́A�����������l�s�|�n�r���A�g�c�c�p�ɖ��c�������������c�n�r�ł���TOSPICS�|�|�P�X�V�T�N�̂��Ƃł���B�h�a�l�@�o�b�Ƃo�b�|�c�n�r���o�Ă���̂́A�J��Ԃ����P�X�W�P�N�ł���|�|�ƁA������X�Ɏ������ꏈ���p�ɏ��������A������������悤�ɂ���TOSPICS-L�����邾���ł���B���́A���̌��w�ʼn��������ϊ����g���āA�^�C�v���C�^�̂悤�ɂ����u���{�ꃏ�[�h�v���Z�b�T�v�Ɏd���ďグ�悤�Ǝv���t�����B���̂��Ƃ́A�N���������P�X�V�V�N�������珑���n�߂��������̒��ŏ��߂Č��y���ꂽ�B�܂��O�l���O�l�̎v���������Ă��������ł���B���̌�A�O�l�A����A���c�������ꂽ�l�l�̎v�������̃��[�v�����ɂ��i�v�|�P�O�Ɍ������Ĉ�̃C���[�W�Ɍ`������Ă����B�Б��̎������̌`�������i�v�|�P�O�̃C���[�W���o�Ă���̂͂܂��܂���ł���B���̌`�͕��i���ǂ̂悤�Ɏ��߂邩�Ƃ����n�[�h�O���[�v�̗v�����琶�܂ꂽ���̂ł���B�ŏ��͗����̈Ă��������B
�P�X�T�O�N��́u���N�v��u���N�N���u�v��ǂ�ł����l�Ȃ�L��������̂ł͂Ȃ����Ǝv�����A�q���p�̂������ȃ^�C�v���C�^�̒ʐM�̔��̃y�[�W�������ڂ��Ă������̂ł���B�m���b�c���x�̑傫���̉~�ՂɊ������ڂ��Ă��āA������܂킵�āA���̏�Œ@���Ĉ�����̂ł������B���͂��ꂪ�~�����Ďd���Ȃ��������A�����Ȓl�i���t���Ă����͂��ŁA�ƂĂ������Ă��炦��悤�Ȃ��̂ł͂Ȃ������B���A���w���ɂ͎g�������Ȃ��B��w�@�ɓ����Ă����������Ƃ͎l���͌����̊ۑP�ɍs���p���^�C�v���C�^�����Ƃł������B����^�J�[�h���ܘ_�Y��Ȃ��B�m�I���Y�̋Z�p�̎��H�ł���B
���āA�b��߂��ƁA���̍��A�͓c����́A����̘_�����Q�l�ɑ�^�@�łe��������������p���āA�܂��A�]���^�̉��������ϊ��G���W�������삵�Ă����B���́A�~�j�R����ł̓��{����̍\�z���}���ł����B�Ȃɂ���A�������̃~�j�R���Ƃ������̂͗��ŁA�����Ă݂�A�l�o�t���ڂ��Ă���}�U�[�{�[�h�����邾���̏�Ԃɓ������B�n�[�h���\�t�g���A�ꂩ����Ȃ���Ȃ�Ȃ��̂ł���B
�͓c����^�@��ʼn��������ϊ��̃G���W�����������B����͊��ɑ�w��m�g�j�Ő�i���B�������I����Ă����̂ŕ��@�͕������Ă��āA�����ł����B����w�I�ɂ͌`�ԑf��̓G���W���Ƃ����B�X����͂�������āA�~�j�R����Ɉڂ��悤�Ɍ����B����ɂ�2�l���Ē�R�����B��L���������R�Q�j�a�A�b�o�t�T�C�N���^�C���T�}�C�N���b�A�i�Q�O�O�j�g���B���݂�2000�N���݁A�o�������������S�͂P�D�T�f�g���ł���B������Ƃ����o�b�Ȃ�A��L���͍Œ�ł��P�Q�W�l�a�B�g�c�c�͂S�O�f�a�ʂ͕t���Ă���j�̃~�j�R���łǂ�����āA���������ϊ��̂悤�ȕ��G�ȃ\�t�g�����̂��H����ɁA�e�������������͎g���Ȃ��B�����Ƃ����̓A�Z���u���[�̕����D���ł͂������̂����B
1976�N�B�͓c�A�V��̉��������ϊ����o�_���B�f�ڂ����[�v���Ƌt���ɂȂ��Ă��܂��Ă��邪�A�����炪
�P�N�����B���̎����́u���v�ɏ����Ă���悤�ɁA�܂��v�Z�@�ւ̓��{����͂̈��i�Ƃ����l���Ă��Ȃ��B

�͓c���`�ԑf��͂��^�@����~�j�R���ɈڐA�A�����G�f�B�^�J����S�����āA�~�j�R���̏�ł̍ŏ��̎���\�t�g���������B���݂̃��[�v���Ɠ����`�Ԃ̓��{�ꃏ�[�h�v���Z�b�T���a�������̂ł������B�P�X�V�U�N���X�̎��ł���B
�J�i�L�[�{�[�h�́A�ܘ_�A�P�O�U�J�i�L�[�{�[�h�Ȃǂ���Ȃ��B�����v���āA�A���v�X�ƌ�����ƃ��[�J�ɍ���Ă�������B���R�O���~�������B������Q�䎎�삵���B�����f�B�X�v���[�̓\�j�[�e�N�g���̂��̂ŁA�~�ϊǂƂ����āA��x��ʂɏ������畔�������������o���Ȃ��B�����Ƃ��͈�x�A��ʑS�̂��t���b�V�������đS�������Ȃ��Ă͂Ȃ�Ȃ��f�B�X�v���C�ł������B����ł����������x���Ŏg����ŏ�̂��̂ł���B�𑜓x�͊o���Ă��Ȃ����A�摜�����Ɏg���Ă����ʂ�����W�O�O���U�O�O�ȏ�͂��������낤�i������IBM PC/AT�͂U�S�O���S�W�O�ł���j�B�����`�悪�x���̂ɂ͕������B������A��_�������̂ɁA���A�����W�l�𑗂�Ȃ��Ƃ����Ȃ��B�P�x�����������ł��������o���Ă��Ȃ����A�P�_�����点�邾���ɂT�A�U���������̃f�[�^�]�����K�v�ł������B�����P���Q�S���Q�S�_���|�`�|�`�ƈ�_�������ď�����Ă����̂�������̂ł���B��ʑS�̂Ő����Ԃ��������͂��ł���B����ł͎g�����ɂȂ�Ȃ��̂ŁA�摜�����O���[�v�̖��c���H�v���ău���E���ǂ̕Ό����Ɏ�������A�X�ɃR���g���[���{�[�h������ăA�i���O�I�ɕ`�悷��悤�ɂ����B�ۏ؊O�ł���B������p�������C���^�t�F�[�X�ƌĂ��A���̂��A�ŁA��ʈ�ʂ̕\�����Q�A�R�b�łł���悤�ɂȂ����B
���̌�A���̃G�f�B�^���g���Ă̎������Ɏ����v�����ď������������A���������x�I��������A�Ȍセ�̓����ꂪ�ŏ��ɏo�Ă���Ƃ������̂ł���B1977�N�̎��ł���B���̓����͋ɂ߂ċ��͂ł������B�u�b�莫����p�����Z���w�K�ɂ�铯����I������v�Ƃ������̂ł���B��ɂ́A����Ȃ��ɂ̓��[�v���͎g���C�����Ȃ��Ƃ������̂�������B���Ƃ��A�u�������傤�v�Ɠ��͂��Ă݂悤�B�l�r�|�h�l�d�ł͂Q�P�̊������o�Ă���B���̓��A�u�H���v�͂P�V�Ԗڂł���B��͑�a�̊J��������������Ƃ����炫���ƁA�u�C�R�H���v���p�ɂɂłĂ��邾�낤�B���̂��тɁA�P�U����u�����v���邢�̓X�y�[�X�o�[��@���̂͑ς����Ȃ��B
����A1976�N���X�̂��̎����i�o�肪1976�N4���Ȃ̂ŁA�����n�߂��̂�75�N��ꂩ�A76�N���X�j�A�͓c����͎����������Ă����̂Ŏ��������[�U�����ɍœK�����邱�Ƃ��v�������B�����w�K�ƌĂ�ł���B�����u�w�K�v�Ƃ������t���g���Ă���̂ŁA���̒Z���w�K�ƊԈ���鎖�����܂ɂ��邪�A�������A�����̌o�܂��A�������܂������قȂ��Ă���B���̔����͎�������G�f�B�^���������A��ʂɓ��͎��������n�߂Ă���l���t�������̂ł���B�͓c�����̒����w�K�̓����������������A���͌���w�I�ȈӖ��������������������̓������������B����͊w��\�̑O�ɓ����������Ă����Ȃ���Ȃ�Ȃ��Ƃ����������̋K��������A��l�ł��ꂼ��̎�v�ȋZ�p���������Ƃ������Ƃœ������ɏ��������̂ł���B���ǂ��A�������t�ŏo�肵�Ă���B
�����w�K�́u���[�U�v�Ƃ����͕̂���ł��悢�B�����ہA�l���ہA�o���ۂ̂悤�Ɏg�������œ����ꂪ�قȂ邾�낤�Ƃ������z�ł���B���̎����ɂ͎��͓����肪�������B�����ꂪ�I�ꂽ�炻�̎������ڂ̕p�x�̗��̒l�ɂP�������Ă����B�����g���Ă���A�ǂ��g���铯����̕p�x�������Ȃ�̂ŁA�������̈�ʂɎ����Ă���ΑI���̎�Ԃ��Ȃ���B
�������A�����̂P�U�r�b�g�R���s���[�^�ł͖�U�T�O�O�O�܂ł����p�x���グ�邱�Ƃ��ł��Ȃ��B�P��ł��ő�l�ɒB������́A�ǂ�����̂��낤���H���ꂪ���̈�ł������B�ق��Ă����A�Ō�ɂ͑S�Ă̌ꂪ�ő�l�ɒB���Ă��܂��A�Ӗ����Ȃ��Ȃ�B�p�x���ڂ��R�Q�r�b�g�ɂ���Ζ�S�O���܂ŏグ�邱�Ƃ��ł���̂ŁA��ꂠ�邢�͐��ꂪ���̒l�ɒB�����Ƃ���ōœK���I���Ƃ��ĈȌ�͌Œ肷��Ηǂ����낤���A�����̕n��Ȑ��\�̃R���s���[�^�ł͂��̂悤���ґ�͎�����ł��Ȃ������B����Ȃ���ȂŁA�����ɂ͎������ꂸ�A����A���Ă̖����܂܂ɕ��c�������������A����Ȗ�Ō㑱�@�ł��A���Ђł��g���Ȃ������Ǝv���B
 �@�@
�@�@
 �������āA���̂P�X�V�U�N���X����A���i�o�ׂP�X�V�X�N���X�܂ł̂R�N�Ԃ̎��̌njR�������n�܂��B�ܘ_�A�i�v�|�P�O�Ƃ����V�X�e���J���͑吨�̋Z�p�҂̗͂̎����ł��邪�A���������ϊ��̍����\���E���p���ׂ̈̔����ƌ����ϓ_�ł͌njR�����ł������̂ł���B�R�N��A�n�Ӌ����̕s�\�錾�����͂̔閧�́A����̐l�H�m�\�̗͂ł������B���̍��A�l�H�m�\���X�I�Ɍ������Ă����̂͋���d�C�H�w�����i��ɏ��H�w�����j�̍�䌤���������ł������B����͐l�H�m�\���Ȃ������܂茤�����Ă��Ȃ������̂��B���͋����䌤�����Ŋw�l�H�m�\�A�����Ă��̈ꕔ�ł���`������w�A�v�Z����w�A���R���ꏈ���A����w�̑��͂�JW-10�Ɍ��W���Ă��̎��p���ɐ��������̂ł���B
�������āA���̂P�X�V�U�N���X����A���i�o�ׂP�X�V�X�N���X�܂ł̂R�N�Ԃ̎��̌njR�������n�܂��B�ܘ_�A�i�v�|�P�O�Ƃ����V�X�e���J���͑吨�̋Z�p�҂̗͂̎����ł��邪�A���������ϊ��̍����\���E���p���ׂ̈̔����ƌ����ϓ_�ł͌njR�����ł������̂ł���B�R�N��A�n�Ӌ����̕s�\�錾�����͂̔閧�́A����̐l�H�m�\�̗͂ł������B���̍��A�l�H�m�\���X�I�Ɍ������Ă����̂͋���d�C�H�w�����i��ɏ��H�w�����j�̍�䌤���������ł������B����͐l�H�m�\���Ȃ������܂茤�����Ă��Ȃ������̂��B���͋����䌤�����Ŋw�l�H�m�\�A�����Ă��̈ꕔ�ł���`������w�A�v�Z����w�A���R���ꏈ���A����w�̑��͂�JW-10�Ɍ��W���Ă��̎��p���ɐ��������̂ł���B
 �m�I���{�b�g�͎q���̍��̓���ł������B���s��w�̑�w�@��䌤�����ɐi�̂́A���̂悤�Ȑ����ɂ��B��䗘�V�E�����^���́u�����E�}�`�̔F���@�B�v�Ƃ����{�������āA�{���̓X��ŗ����ǂ݂��Ȃ���A�@�B���l�Ԃ̂悤�ɕ�����ǂނ��Ƃ��ł���Ƃ��������Ɏ肪�k�������̂ł���B�l�Ԃ̒m�����@�B�Ŏ������邱�Ƃ��q���̍�����̖��ł������̂ł���B��䌤�ōŏ��ɓǂ������A���m�ے��Q�̐�y�A���o����������MIT��Minsky���uSteps toward Artificial Intelligence�v�ł������B
�m�I���{�b�g�͎q���̍��̓���ł������B���s��w�̑�w�@��䌤�����ɐi�̂́A���̂悤�Ȑ����ɂ��B��䗘�V�E�����^���́u�����E�}�`�̔F���@�B�v�Ƃ����{�������āA�{���̓X��ŗ����ǂ݂��Ȃ���A�@�B���l�Ԃ̂悤�ɕ�����ǂނ��Ƃ��ł���Ƃ��������Ɏ肪�k�������̂ł���B�l�Ԃ̒m�����@�B�Ŏ������邱�Ƃ��q���̍�����̖��ł������̂ł���B��䌤�ōŏ��ɓǂ������A���m�ے��Q�̐�y�A���o����������MIT��Minsky���uSteps toward Artificial Intelligence�v�ł������B

 1963�N�ɋ��s��w��䌤�����ŁA�����呍�������搶�̉��ő���������Ă������̂��ł��Â��Ƃ킩�����B��䗘�V�A�����^�̎w���Ř_�����������̂�����P������Ƃ����A���̍�䌤�����̐�y�������B���ꂪ���ȕ��@��͂����ŌÂ̌����ł���B�Q�O�O�Q�N�ANHK�̃v���W�F�N�gX�̒��Łu����͂����������ł��v�Ƃ������������u�ނ͉�w���ł��v�Ɓu�͗t���w���ł��v�̞B���������Ƃ�����Ŏg���Ă������A����̘_������̈��p���������Ƃ��A���̎��킩�����B����͊��ɘ_�������Ă��āA���̗�͋L���ɗ�����NHK�ɘb���ꂽ�̂��낤�B���̒����̎��A����̗F�l��_�k��y����--�ނ͂P�N���Ȃ̂����C�m�P�Ő��E�ő�̓d�C�d�q�n�w��IEEE�ɘ_�����̘^���ꂽ�Ƃ�����G�˂ł���B�����A�C�m�Q�̎��ƒ҈�͊��S���đA�܂�������--�ɐ}������T���Ă��������A�Ȃ�ƁA�o�Ă����̂ł���B�������_���X�L�������đ����Ă��ꂽ�̂ŁA���̂܂ܓ]�����đ���ɍ����グ�����A��w��ꂽ�B���̑���Ƃ��������A���ʂ͏���A��ANHK�̋Z�p�������ʼn��������ϊ��̌����Ɏ��g�����B���搶�́A��w�ōs�����Ƃ͔ėp�̋Z�p�A���_�ł���ׂ����Ƃ����l���̐搶�ł���������A���̘_���́A�u���������ϊ��v�̂悤�ȉ��p�I�ȃ^�C�g���������u����̌v�Z�@�����v�Ƃ������O�̘_���ɂȂ��Ă���B
1963�N�ɋ��s��w��䌤�����ŁA�����呍�������搶�̉��ő���������Ă������̂��ł��Â��Ƃ킩�����B��䗘�V�A�����^�̎w���Ř_�����������̂�����P������Ƃ����A���̍�䌤�����̐�y�������B���ꂪ���ȕ��@��͂����ŌÂ̌����ł���B�Q�O�O�Q�N�ANHK�̃v���W�F�N�gX�̒��Łu����͂����������ł��v�Ƃ������������u�ނ͉�w���ł��v�Ɓu�͗t���w���ł��v�̞B���������Ƃ�����Ŏg���Ă������A����̘_������̈��p���������Ƃ��A���̎��킩�����B����͊��ɘ_�������Ă��āA���̗�͋L���ɗ�����NHK�ɘb���ꂽ�̂��낤�B���̒����̎��A����̗F�l��_�k��y����--�ނ͂P�N���Ȃ̂����C�m�P�Ő��E�ő�̓d�C�d�q�n�w��IEEE�ɘ_�����̘^���ꂽ�Ƃ�����G�˂ł���B�����A�C�m�Q�̎��ƒ҈�͊��S���đA�܂�������--�ɐ}������T���Ă��������A�Ȃ�ƁA�o�Ă����̂ł���B�������_���X�L�������đ����Ă��ꂽ�̂ŁA���̂܂ܓ]�����đ���ɍ����グ�����A��w��ꂽ�B���̑���Ƃ��������A���ʂ͏���A��ANHK�̋Z�p�������ʼn��������ϊ��̌����Ɏ��g�����B���搶�́A��w�ōs�����Ƃ͔ėp�̋Z�p�A���_�ł���ׂ����Ƃ����l���̐搶�ł���������A���̘_���́A�u���������ϊ��v�̂悤�ȉ��p�I�ȃ^�C�g���������u����̌v�Z�@�����v�Ƃ������O�̘_���ɂȂ��Ă���B
 �P�X�U�U�N�ɂ͋�B��w�̌I���r�F�搶���A�u�J�i�����ϊ��ɂ��āi��P��j�v�ƌ����_����������āA���������p�Ƃ��Ẳ��������ϊ������߂ďo�Ă����B�i��P��j�́A�I���搶�́i��P��j�ł��邯��ǁA���̎���A�u���������ϊ��v�Ƃ������̂Ő�s���Ă���_���͊F���Ȃ̂ŁA���{�ł́A����A���E�ł́i��P��j�Ȃ̂ł����B
�P�X�U�U�N�ɂ͋�B��w�̌I���r�F�搶���A�u�J�i�����ϊ��ɂ��āi��P��j�v�ƌ����_����������āA���������p�Ƃ��Ẳ��������ϊ������߂ďo�Ă����B�i��P��j�́A�I���搶�́i��P��j�ł��邯��ǁA���̎���A�u���������ϊ��v�Ƃ������̂Ő�s���Ă���_���͊F���Ȃ̂ŁA���{�ł́A����A���E�ł́i��P��j�Ȃ̂ł����B
 ���̂Ƃ���I���搶�́A�i��P��j�̑O�A�P�X�U�T�N�̏����i�K�ł��u���{��̕��́E�����̂��߂̎����ɂ��āv�Ƃ����_�����o����Ă����B���̘_����T���o���ĉ��������I���搶�̂���q����ł�������L�搶�̉��l���A���̘_���̋����҂ɂȂ��Ă���Ƃ������ƂŁA���l���X������[�����ꂽ�Ƃ������ƂŁA�����I�߂����O�̉��������v���o�ɁA���A����W�҈ꓯ�A���ꂼ��ɐZ�邱�ƂɂȂ����B���̘_���́A�]���A�P�X�U�V�N�̋�B��w�H�w�W��ɏo�����̂��A�������A�Б������ŁA��������ŌÂ̏o�T�Ƃ��Ĉ����Ă������A�Q�N���O�ɑk�鎖���ł����B
���̂Ƃ���I���搶�́A�i��P��j�̑O�A�P�X�U�T�N�̏����i�K�ł��u���{��̕��́E�����̂��߂̎����ɂ��āv�Ƃ����_�����o����Ă����B���̘_����T���o���ĉ��������I���搶�̂���q����ł�������L�搶�̉��l���A���̘_���̋����҂ɂȂ��Ă���Ƃ������ƂŁA���l���X������[�����ꂽ�Ƃ������ƂŁA�����I�߂����O�̉��������v���o�ɁA���A����W�҈ꓯ�A���ꂼ��ɐZ�邱�ƂɂȂ����B���̘_���́A�]���A�P�X�U�V�N�̋�B��w�H�w�W��ɏo�����̂��A�������A�Б������ŁA��������ŌÂ̏o�T�Ƃ��Ĉ����Ă������A�Q�N���O�ɑk�鎖���ł����B
 �������āA���ʼn��������ϊ��ɓ������ꂽ���{�ꏈ���̋Z�p�́A�I���搶�̍��Z����̓����̗F�l��NHK�̑���̏�i�ł���ƌ����������A����Ɉ����p���ꂽ�̂ł������B����Ƌ��̋Z�p������Ƃ�����l�̒��ŗZ�������̂ł���B�P�X�V�O�N�ɂ�NHK���瑊��_���u���@���𗘗p�����J�i�����ϊ��v���o��B
�������āA���ʼn��������ϊ��ɓ������ꂽ���{�ꏈ���̋Z�p�́A�I���搶�̍��Z����̓����̗F�l��NHK�̑���̏�i�ł���ƌ����������A����Ɉ����p���ꂽ�̂ł������B����Ƌ��̋Z�p������Ƃ�����l�̒��ŗZ�������̂ł���B�P�X�V�O�N�ɂ�NHK���瑊��_���u���@���𗘗p�����J�i�����ϊ��v���o��B
 �������A���������ϊ��͎��p������Ȃ������B�����炩�ǂ����A�P�X�V�U�N�ɓ���̏��Ȋw�̌��ЁA�n�Ӗΐ搶���A���̈��ʂ��uNHK�v�u�b�N�X����u�����Ɛ}�`�v�Ƃ������Ȋw�̖{��������A�p���^�C�v�̂悤�ȋ@�B�͓��{��ł́u�ł��铹���������̂ł����v�ƕs�\�錾���Ȃ���Ă��܂����̂��B
�������A���������ϊ��͎��p������Ȃ������B�����炩�ǂ����A�P�X�V�U�N�ɓ���̏��Ȋw�̌��ЁA�n�Ӗΐ搶���A���̈��ʂ��uNHK�v�u�b�N�X����u�����Ɛ}�`�v�Ƃ������Ȋw�̖{��������A�p���^�C�v�̂悤�ȋ@�B�͓��{��ł́u�ł��铹���������̂ł����v�ƕs�\�錾���Ȃ���Ă��܂����̂��B

 ��Ƃɂ͎��R���ꏈ���̋Z�p�͂ǂ��ɂ��Ȃ������B���d�C���������肳��Ƃ����Ⴂ�����҂��I���������Ɍ������Ƃ��đ��荞��ł������A�ǂ��������̌㊈�p���Ȃ������B���ł����R������������悤�Ƃ����v�����������A�ǂ����Ă����̂��킩��Ȃ��̂ŁA�����搶�̂Ƃ���ɑ����������̓d�q�H�w�̐��Ƃł���͓c����𑗂荞�̂ł���B�����Ɏ������āA���ꗝ���̘_����ǂ�ł����A�Ƃ����ł̏o��ł������B
��Ƃɂ͎��R���ꏈ���̋Z�p�͂ǂ��ɂ��Ȃ������B���d�C���������肳��Ƃ����Ⴂ�����҂��I���������Ɍ������Ƃ��đ��荞��ł������A�ǂ��������̌㊈�p���Ȃ������B���ł����R������������悤�Ƃ����v�����������A�ǂ����Ă����̂��킩��Ȃ��̂ŁA�����搶�̂Ƃ���ɑ����������̓d�q�H�w�̐��Ƃł���͓c����𑗂荞�̂ł���B�����Ɏ������āA���ꗝ���̘_����ǂ�ł����A�Ƃ����ł̏o��ł������B

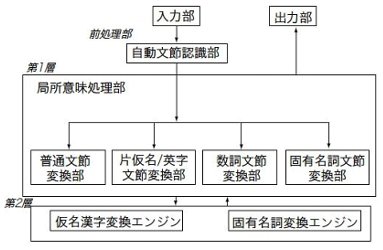 ���̂悤�ȕ��G�ȓ��{��\�L�ɑΏ����邽�߂ɁA�u�Ǐ��Ӗ������ɂ���w�^�i�������͌^�Ƃ��Ăԁj���������ϊ������v�Ƃ����A�C�f�A��n�o�����B����ł��A������͊��S�ɂ͉����ł����A���j�^�[��ɓ��₩�Ɏc��BJW-10�ł́A������͐擪�̌ꂾ����\�����A�����ꂪ���݂��Ă��邱�Ƃ��������߁A�u�����N�����Ă����B����ŁA������I�������I�Ɍ���up���邽�߂̂����ЂƂ̃A�C�f�A���o�����B�u�b�莫����p�����Z���w�K�ɂ�铯����I������v�ł���B���̃A�C�f�A�͋Ǐ��Ӗ�������n�Ă���O�̎���V�X�e���̎��Ɋ��Ɏv���������̂ł������B
���̂悤�ȕ��G�ȓ��{��\�L�ɑΏ����邽�߂ɁA�u�Ǐ��Ӗ������ɂ���w�^�i�������͌^�Ƃ��Ăԁj���������ϊ������v�Ƃ����A�C�f�A��n�o�����B����ł��A������͊��S�ɂ͉����ł����A���j�^�[��ɓ��₩�Ɏc��BJW-10�ł́A������͐擪�̌ꂾ����\�����A�����ꂪ���݂��Ă��邱�Ƃ��������߁A�u�����N�����Ă����B����ŁA������I�������I�Ɍ���up���邽�߂̂����ЂƂ̃A�C�f�A���o�����B�u�b�莫����p�����Z���w�K�ɂ�铯����I������v�ł���B���̃A�C�f�A�͋Ǐ��Ӗ�������n�Ă���O�̎���V�X�e���̎��Ɋ��Ɏv���������̂ł������B



