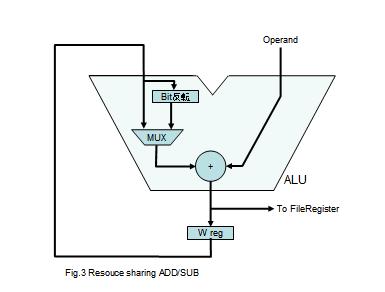
図3 加減算のリソースシェア(クリックして拡大)
| CLRF | 00 0001 1fff ffff |
| CLRW | 00 0001 0xxx xxxx |
| MOVWF | 00 0000 1fff ffff |
| NOP | 00 0000 0xx0 0000 |
| SUBWF |
W (or
f) <= f - W |
| SUBLW |
W <=
Literal - W |
図3 加減算のリソースシェア(クリックして拡大) |
| リソースシェアを意識した記
述 |
リソースシェアされないかも
しれない記述 |
|
|
<<前に戻る Index へ 次へ>>