兎にも角にも、まずは検索用のページを作ります。以下のコードを書いて、「search.html」というファイル名で、ファイルメーカーProの「Web」フォルダに保存しましょう。(Webコンパニオン機能の設定はファイルメーカーProヘルプを参照してください。インスタントWeb機能が使える状態になっていればOKです)
| 「search.html」の中身 |
|---|
|
このページを開くと、
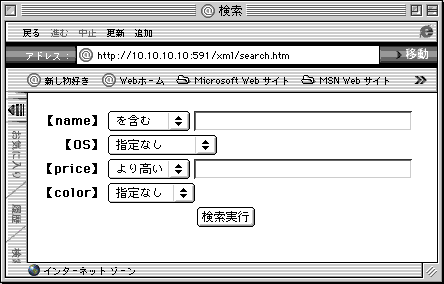
というように表示されます。CDMLを使った検索ページを作っている人ならわかるでしょう。ごく普通の検索用ページの構成です。重要なのは9行目の
<input type="hidden" name="-format" value="-dso_xml">
です。フォーマットに「-dso_xml」を指定することで、XML形式で検索結果が得られます。それだけです、ホント。それから
<input type="hidden" name="-max" value="all">を忘れないように。XML+XSLの醍醐味は、データをいっきにユーザーに送り付けて、あとはユーザー側で自由に加工してもらうことで、ソートやページ切替のたびにサーバーにリクエストを発生させないところにあります。ですから、検索結果は全件ユーザー側へ送ってしまいます。
フォーム中に適当な検索条件を入力して、検索を実行しましょう。すると検索結果が次のようなXML形式で取得できます。

すごい、XMLデータを取得できました! 簡単ですね。フォーマットに-dso_xmlを指定するだけで、XML形式で検索結果を受け取ることができます。

さて、XML形式のデータを見ると、入れ子構造(階層型またはツリー型)になっているのがわかります。これがCSV(カンマ区切りテキスト)によるデータ形式と決定的に違う点です。データ間の関連性が複雑になればなるほど、XML形式の便利さがわかると思います。
HTMLを書き慣れている人なら、入れ子構造を理解するのも簡単でしょう。FMPDSORESULT要素を第1階層(ルート)として、第二階層にはERRORCODE要素とDATABASE要素とLAYOUT要素とROW要素があります。<ROW>タグ〜</ROW>タグで挟まれた部分がレコード1つ分に相当します。検索に該当したレコードの数だけROW要素が繰り返されます。ROW要素の下の階層(第三階層)にはフィールド名に対応する各要素がならんでいます。<name>タグ〜</name>タグにはnameフィールドの値が、<os>タグ〜</os>タグにはosフィールドの値が、それぞれ挟まれています。Internet ExplorerはXMLデータを受信すると、上図のように階層構造が把握しやすいレイアウトで表示する機能をもっています(便利ですね)。
各要素において、開始タグと終了タグに挟まれた部分を要素値といいます。開始タグ中に付属するのが属性で、その値が属性値です。たとえば、ROW要素にはMODID属性とRECID属性があり、それぞれの属性値は編集ID、レコードIDが入っています。
ところで、ROW要素内に埋め込まれる各フィールドデータの出現順番は、レイアウト上でのフィールドの配置で決まります。レイアウト上でフィールドの配置を変更すると、XMLデータ内でのフィールドの順番も変わります(レイアウト上で左上にあるフィールドが、XML上で前の方に出てきます)。また、レイアウト上にないフィールドはXMLデータにも出てきません。つまり、XMLデータに載せるフィールドやその順番は、ファイルメーカーProのレイアウトで決めます(ということは、検索条件に-layの指定がないと、XMLデータは取れません)。
自分でCDMLのカスタムWebを作っている人は、自分の検索ページのフォーマット指定部分を「-dso_xml」に書き換えて、検索を実行してみてください。たったそれだけで、XML形式で検索結果を受け取ることができます。>>