該当レコードのうち1〜5番目だけを表示する方法を考えましょう。ROW要素の初めから5個を表示する方法です。これはROW要素を変換処理する際に、ROW要素の順番を評価して、5番目までなら処理する。6番目以降は無視する。という評価式を組み込みます。
| 出現順番の評価 |
|---|
|
select="〜"で、変換処理する要素を指定するわけですが、ROWのあとに[ ]が付いています。[ ]は評価式をあらわします。評価式に適合するROW要素だけがテンプレートでの処理の対象になるわけです。評価式の中を見てみましょう。
「index()」は出現順を表わす関数です。順番は0から始まります。最初のROW要素はindex()=0です。「ROW[index()$ge$0」は出現順が0以上「index()$le$4]」は出現順が4以下であることを表わし、これらを$and$で結合することで、「出現順が0以上かつ4以下であるROW要素」ということになります。こうすることで、ROW要素の1番目から5番目までがテンプレート処理の対象になります。これを組み込んだXSLファイルは次のようになります。
| ROW要素の1〜5番目までを表示するためのXSLファイル「result.xsl」 |
|---|
|
このresult.xslを使ってXMLデータをレイアウトすると次のようになります。
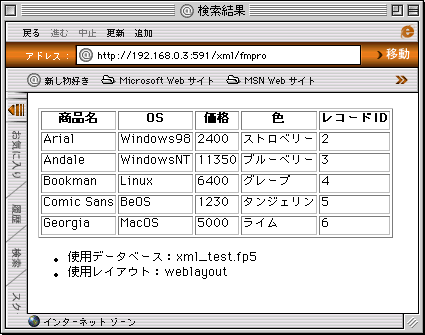
検索結果の中から、はじめの5つだけが表示されました。
評価式でよく使う比較演算子類をまとめると以下になります。
| 構文 | 説明 |
|---|---|
$and$ |
かつ |
$or$ |
または |
$not$ |
ではない |
$eq$ |
等しい |
$ieq$ |
等しい(大文字小文字を区別する) |
$ne$ |
等しくない |
$ine$ |
等しくない(大文字小文字を区別する) |
$lt$ |
より小さい |
$ilt$ |
より小さい(大文字小文字を区別する) |
$le$ |
小さいか等しい |
$ile$ |
小さいか等しい(大文字小文字を区別する) |
$gt$ |
より大きい |
$igt$ |
より大きい(大文字小文字を区別する) |
$ge$ |
大きいか等しい |
$ige$ |
大きいか等しい(大文字小文字を区別する) |
$all$ |
全て |
$any$ |
どれか一つ |
これらを使って[ ]中に評価式を作ることで、変換対象の要素をさらに限定することができるのです。>>