電子情報通信学会技術研究報告, ET92-22, pp.5-12, 1992-05-23
適応型逐次検定システムの開発
小林 修
|
あらまし 能力テストには,①受検者の能力と隔たった問題が多数含まれ,受検意欲を殺ぐ,②検定精度を高めるために問題数が多く,負荷が大きい,などの問題点がある.これらを解消するために,適応型逐次検定システムを開発した.逐次検定は多重並立仮説の場合に拡張されている.本検定方式では,出題するテスト項目には,学習水準別の正答率だけが付与される.シミュレーションによる測定では,固定出題型に比べ,出題数は半減し,受検負荷が少なく,実用的な検定方式であることが確認できた.
|
1.まえがき
学習水準の検定のための適応型逐次検定システムを開発したので報告する.本稿では,これを留学生向けの日本語語彙能力テスト(5レベルにランク付けする.レベル1が学習開始直後のレベルである)に適用する.
能力テスト(proficiency test)は,広い範囲の受検者を対象とするので,一般に,次のような問題点がある.①能力の高い受検者は,低いレベルの問題に飽きてしまい,逆の場合は回答できないために意欲を失うことになる.②測定精度を高めたり,複数の能力分野の測定を行うと,受検者の負担が大きくなりがちである.③教師にとっては,テスト後のデータ処理の負荷が大きい.④受検者が,単独で能力を測定することができない.⑤教育課程の中で,定期的に能力測定を行いたい場合(日本語能力テストは,年に6回実施されている),定常的に問題を作成し供給することに困難が伴う.
これらの問題点を解消するために,項目反応理論に基づく適応形テスト(3)-(11)や,コンピュータを利用してテスト項目プールからテストを構成するシステム(1)-(2)などが試みられてきた.前者は,前掲の問題点の中では,主として①と②に関わるものであるが,前提とする項目反応理論の制約(測定対象の一次元性と測定項目間の独立性)があることと,パラメータ(困難度と識別力)の安定した推定のためにかなり大量のデータを要し,そのテスト・システムを教育現場で個別に作成・利用するというより,規範性のある検定として,他の機関からの供給を受けて利用するという形態が,より相応しいものである.テストの実施は,印刷物による場合(3)-(5),(9)とパーソナル・コンピュータによる場合(6)-(11)が報告されている.なお,逐次検定による合否判定法と適応形テストとの比較研究(10)が報告されている.合否の対象となる能力θがθc を越えるとき合格とすれば,この複合仮説に対する検定を,θ1<θc<θ2 となるようにθ1,θ2を適当に定め,θ=θ1,θ=θ2の2つの単純仮説の対立に帰着させることにより,逐次検定を適用する方法である.θ1,θ2をどう定めるのか基準がないことと,報告によれば,合否判定の誤りが予想を大幅に上回るケースがあるなど,実用上も理論的枠組みにも,弱点がある.
一方,後者のテスト構成支援システムは,③と⑤に関わる先行研究である.まとまった数のテスト項目を正答率や相関係数などと共にプールしておき,教師の操作により適切なテスト項目を選択,テストの統計的特性を推定し確認した後,そのテストを確定・作成する.これらは,テストの実施に先立ってそのテストを構成するもの(固定出題型)であり,前掲の問題点①②④に対しては,あらかじめ多種類のテストを用意しておくなど,部分的な解答しか与えることができない.テスト項目に付与する情報も量的に多く,質的にも,ある程度の精度の推定値を得るために,まとまった量の事前調査とデータ処理を要するものが含まれている.
本稿では,これらの先行研究を踏まえ,前掲の問題点①〜⑤に対する一つの解答として開発した,適応型逐次検定システムについて報告する.この検定システムは,(ア)特定のテスト理論や能力構造に依らず,統計的に処理を行うこと,(イ)教育現場で容易に適用できること,を条件とし,(ウ)テスト項目は,結果が正誤によって判定される形式であること,を制約として開発され,前掲の問題点①〜⑤に対応して,以下の利点を持つ.
- ①受検者の水準に合わせて出題するので,固定出題型に比べて,飽きることが少ない.
- ②固定出題型に比べて,出題数が少なくなるので,検定に要する受検者の負担が少ない.
- ③回答データの機械利用ができるので,データ処理を自動化できる.
- ④受検者が,単独で検定することができる.
- ⑤あらかじめプールしたテスト項目から検定実施時に逐次的に,選択・出題されるので,作問の負荷を分散できる.
- ⑥プールするテスト項目は,教育現場においても,エディタなどで容易に作成・編集できる.
- ⑦プールするテスト項目に付与する情報は,学習水準別の正答率だけであり,大量のデータ処理を要することなく設定することができる.
以下,本稿では,本検定システムの実現法に関する上記③④⑥および性能など実用的側面について報告し,適応型逐次検定方式に関する①②⑤⑦については,概要を示すに留め,詳細は別の機会にゆずる.
2.適応型逐次検定
2.1 適応型逐次検定の考え方
本検定方式では,結果が正誤で判定されるテスト項目を多数用意し,これを逐次,受検者に提示し,これに対する受検者の反応を測定して,その受検者の学習水準を検定する.この際,特定の能力構造やテスト理論は仮定しない.
プールするテスト項目には,学習水準に対応して,あらかじめ正答率を付与しておき,回答の正誤と所与の正答率から得られる尤度により,最大尤度を示す学習水準をもって受検者の学習水準と判定する.このときの出題打切りの条件は,通常の逐次検定と同じく,尤度比が判定のグレイゾーンを外れた時点とする.尤度比は,通常とは異なり3つ以上の検定仮説が並立する本検定方式では,最大の尤度と次点の尤度に対するものを採用する(次節参照).
テスト項目に付与する正答率は,本稿では,実測値ではなく,学習水準の基準値と解釈する.また,正答率の精度は,5%単位程度でよいことが分かっている(シミュレーションによる測定結果.これについては,別の機会に報告する予定である).
出題に際しては,出題打切りの条件に速やかに達するように,2.3に述べる方法で,最適なテスト項目を選択する.
2.2 多重並立仮説の逐次検定
本稿で扱う検定問題では,検定すべき仮説は学習水準の数だけ並立する.従って,通常の逐次検定方式を次のように拡張する.
検定仮説をHi,Hiに対する第一種の過誤をαi,Hjからの第二種の過誤をβijとし,尤度をλi とする.そしてHiに対するHjの棄却基準をcij=βij/(1−αi),とすれば,
iと異なるすべてjに対し,
λj/λi≦cij
となったとき,Hiを採択する.
本稿では,β=(1/2)α=5%とする.
2.3 テスト項目の最適選択
最大および次点の尤度を持つ学習水準をm,n,それぞれの尤度をλm,λn,次に回答すべきテスト項目に対する正答率をpm,pn,誤答率をqm=1−pm,qn=1−pnとする.本検定で必要とするのは尤度比であるから,λm=1に正規化し,同じ記号で表すことにする.以下,これを相対尤度と呼ぶ.
検定の過程の各時点において,受検者が学習水準iである確率は相対尤度λiに比例すると仮定すると,回答後の相対尤度の期待値の増分は,次のように計算される.
本稿の最適選択は,上式を評価関数とし,
⊿λnが最大となるテスト項目を選択する
によって行う(最小化ではない).
実際に上式を適用するときは,テスト項目に依存しない係数部分を取り除いて評価する.
2.4 実用上の問題点
本検定方式を実用に供するには,更に,次の点に関する検討が必要である.
2.4.1 出題数の下限
能力テストで実際に出題された課題で検定すると,10問足らずで検定を終了するケースがあり,形成的機能を考慮すると,出題数の下限を設ける必要がある.
2.4.2 最適選択の緩和
また,最適なテスト項目を選択して出題するので,繰り返し受検できることが本研究の前提であるにも拘わらず,検定の後半では,同じ学習水準の受検者に対して,同一のテスト項目が出題される傾向にある.従って,最適選択の条件を状況に応じて緩和する必要がある(11).
3.適応型逐次検定システム
本適応型逐次検定システムは,汎用性・可搬性を考慮し,一般的なパーソナル・コンピュータ上で動作するように実現された(図1参照).
問題形式は,本検定システムの適用目標である日本語語彙能力の検定に合わせて,択一式とし,出題に際しディスプレイの固定領域に絵を含めることができる(図2参照).
テスト項目は,市販のエディタやワープロで作成・編集可能なテキスト形式であり,検定実施者が自作し,項目集合ファイル(*.ibf)にプールしておく(図5参照).絵は,ユーティリティ(picture.exe)を使って,スキャナから読み込み,画像ファイル(*.pic)を作成し,保存しておく.最大 1,000項目を,出題対象のテスト項目として,検定プログラム(adaptive.exe)中に取り込むことができ,同じテスト項目を二度出題することはしない.
受検者は,ディスプレイに提示されたテスト項目に,選択肢に付された記号(a,b,…など)をキーボードから打ち込むことにより,回答する.これを順次繰り返し,打切り条件に達すると終了する.
検定の結果は,ディスプレイに表示されるとともに,検定履歴ファイル(*.his)にも保存され,ユーティリティ(history.exe)を使って,結果を再表示することができる(図3,図4参照).この検定履歴ファイルは,市販の表計算ソフトで読み込める形式のテキスト・ファイルであり,用途に合わせて,再編集することができる.
検定の結果を表示した後,希望すれば,検定中に出題した項目を,全問または誤答した問題のみ再現させ,自身の回答の正誤および正解を確認することができる.この再現機能は,本検定システムの形成的機能を強化する目的で設けられている.
2.1 で述べたように,本稿では,正答率は学習水準の基準値と解釈するのだが,この基準値の設定が,実際の回答状況と大きく隔たっていることがあり得る.この場合,その原因は別に求めるべきだが,補正する手段があると都合がよい.本検定システムでは,保存した検定履歴ファイルを,ユーティリティ(collect.exe)を使って集約(*.col)し,過去の回答状況を表す補正ファイル(correct.col)を作成,実行時に正答率を補正することができる.
3.1 システム構成
概要を図1に示す.
本システムは,4つのプログラムと一つの補正ファイル,テスト項目プールを構成する一つまたは複数の項目集合ファイルとそれに伴う画像ファイル,および受検の度に生成される検定履歴ファイルから構成される.
システムの容量は,1枚のフロッピーに収まる大きさであるが,動作速度を考慮すると,RAMディスクまたはハード・ディスクに置くことが望ましい.
検定中に,受検者が直接操作するのは,検定プログラム(adaptive.exe)だけである.項目集合ファイル,画像ファイルおよび補正ファイルは,カレント・ディレクトリになければならない.また,他の3つのユーティリティは,検定中は使用されない.項目集合ファイルと画像ファイルは,テスト項目が選択される度に参照されるが,補正ファイルは,検定プログラムの起動時に参照されるだけである.
検定履歴ファイルは,検定終了時に,カレント・ディレクトリに生成される.ファイル名の形式は,xxxx-nnn.his,ここで,xxxxは起動時に変更可能な検定履歴ファイルID(3.5参照)であり,nnn は001から999までの連番である.連番は小さい方から割り当てられ,空きがないときは 000が用いられる.
項目集合ファイルは,検定実施者があらかじめ市販のエディタなどで作成しておく.絵を用いる場合は,必要とするテスト項目の記述の中で,別に作成した画像ファイルのファイル名を指定する(図5参照).項目集合ファイルの構成については,3.4で改めて述べる.
画像ファイルは,33mm(縦)×44mm(横)の原画を,ユーティリティ(picture.exe) を使って,スキャナで2次元圧縮して読みとり,作成する.
ユーティリティ(history.exe) は,検定履歴ファイルの内容を,検定終了時と同様の形式で,編集・表示する(図3,図4参照).
検定履歴ファイルは,検定実施日などの時刻データ,検定結果,出題対象となったすべてのテスト項目に関し,3.4で述べる項目IDと正解,および実際に出題したテスト項目に対する回答などを含む.これらは,市販の表計算ソフトで編集可能な形式になっている.しかし,受検者名など,受検者に関する情報は含まない.
また,ユーティリティ(collect.exe) は,アーカイブ属性のついた検定履歴ファイルを集約し補正ファイルを更新する.二重計上を防ぐために,集約後,検定履歴ファイルのアーカイブ属性は解除され,補正ファイルのバックアップ(correct.bak)が作成される.検定履歴は,履歴集約ファイル(補正ファイルと同一の構造を持つ)に集約することもでき,このファイルはまた集約の対象とすることができる.
補正ファイルは,3.4で述べる項目IDおよび学習水準毎の正答回数/出題回数を含むテキスト・ファイルである.これは,市販の表計算ソフトで編集可能な形式となっている.
3.2 ハードウェアの適用条件
本検定システムの開発機種は,国内で最も一般的なパーソナル・コンピュータの一つであり,同シリーズ中の比較的新しい6機種で動作を確認している.但し,検定中にファイルのオープン・クローズを繰り返すので,旧型機では動作速度が気に掛かることがある.RAMディスクまたはハード・ディスク上で検定することが望ましい.
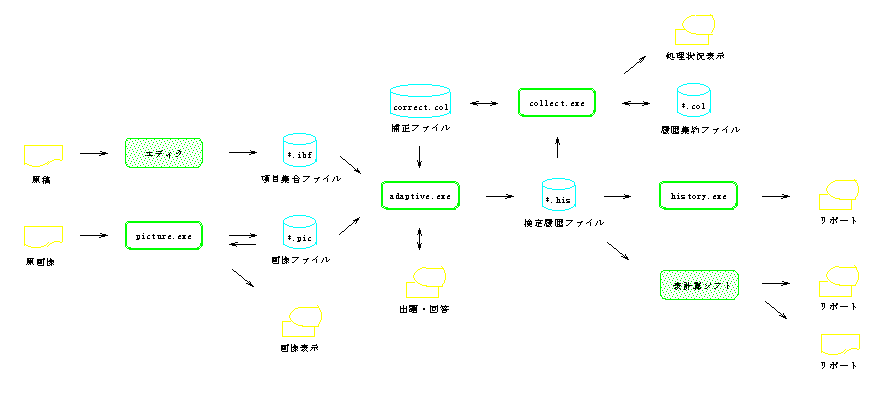
図1 適応型逐次検定システムの構成
ユーザ・メモリーは,241K以上で動作可能である.16色表示を前提にしているが,8色のカラー・ディスプレイでも表示色が重なることはない.
画像ファイルを作成する際のスキャナは,標準的な機種ではあるが,拡張モードのコマンドを使用しているので,古い機種では,動作しないことがある.
3.3 ソフトウェア仕様
ハードウェアと同様,基本ソフトについても,国内で最も一般的なものを使用して開発した.
検定プログラムおよびユーティリティは,動作モードや操作対象を指示する引数(以下,定位置引数と呼ぶ)と,動作の条件などを指示する引数(以下,オプションと呼ぶ)を伴う.
定位置引数は,その名の通り,定まった順序で記述する.一方,オプションは,定位置引数に先立って,任意の順序で記述する.
すべてのオプションは,−(ハイフン)で始まり,取り消しのオプションは,また,−で終わる.矛盾するオプションが複数並んでいるときは最後のものが有効となる.
すべてのプログラムは,一つ以上の定位置引数を必要とし,最初の定位置引数が?(疑問符)であるときは,起動コマンドの形式を表示して終了する.また,定位置引数がないときは,起動コマンドの形式を表示して終了するか,メニュー方式に切り替える(検定プログラムの場合).
プログラムの中断は,原則として,ESC(エスケープ) キーを押下して行う.
図2は,テスト項目の提示画面の一例である.画面右下の楕円の中に受検者が打鍵した回答(図2ではd)が表示される.リターン・キーの打鍵により回答が確定し,正解と比較される.このとき英字の大文字と小文字は区別されない.採点の結果に応じて,次の問題が,残りのテスト項目プールから選択され,提示される.
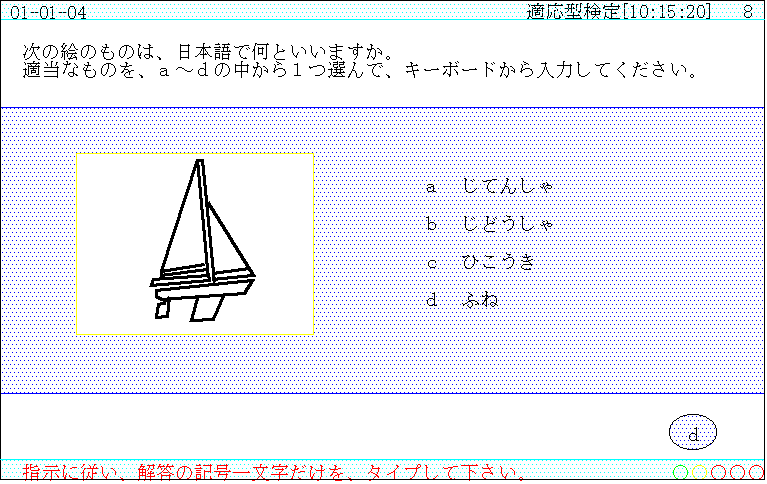
図2 テスト項目の提示画面

図3 検定結果の表示画面

図4 検定推移の表示画面
選択方法は,2.3で述べた最適選択法による.相対尤度の計算では,浮動小数点を用いることになるが,1,000 項目を含む場合でも,1秒足らず(CPU クロック 12MHz)で選択が終了する.絵を含み,フロッピー上で実行している場合は,絵の表示のために,もう少し時間が掛かる.
検定が終了すると,図3に示す検定結果が表示される.このとき,検定中の相対尤度の推移も見ることができる(図4).但し,これは検定実施者用のものである.
参考までに,ファイルの大きさを以下に示す.
| | プログラム | adaptive.exe | 241K |
| | | picture.exe | 72K |
| | | history.exe | 171K |
| | | collect.exe | 207K |
| | 項目集合ファイル | *.ibf | 0.4K/項目 |
| | 画像ファイル | *.pic | 2K/ファイル |
| | 検定履歴ファイル | xxxx-nnn.his | 0.04K/項目 |
| | 補正ファイル | correct.col | 0.05K/項目 |
3.4 項目集合ファイルの構成
テスト項目は,半角80字 4行までの説明文と最大14行の問題部分から成り,同じ説明文を持つテスト項目は,一つの項目集合ファイル(図5参照)にまとめておくことができる.また,各テスト項目には,半角8桁以内の項目IDを付けておく.この項目IDは正答率の補正の際の標識となるので,全システム内でユニークでなければならない.
項目集合ファイルは,改頁符号(FF)で区切られた頁から成り,最初の頁は,共通の説明文,2頁以降の各頁にテスト項目の問題部分を記述する.
| 説明文 | | 次の絵のものは、日本語で何といいますか。 |
| 適当なものを、a〜dの中から1つ選んで、キーボードから入力してください。 |
| [改頁符号] |
| (C) | * 01-01-04 d ふね |
| (S) | * 0 65 80 90 95 |
| 項目01-01-04 | a じてんしゃ |
| b じどうしゃ |
| c ひこうき |
| d ふね |
| [改頁符号] |
| (C) | * 01-01-06 a ものさし |
| (S) | * 0 20 40 50 60 |
| 項目01-01-06 | a ものさし |
| b アルバム |
| c いれもの |
| d おしろい |
| [改頁符号] |
|
図5 項目集合ファイルの構成
各問題部分には,項目ID,正解,画像ファイル名を記述する行(図5の(C)),および正答率を記述する行(図5の(S))を付加する.
正答率は,レベル1からレベル5までを順に,%単位で記述する.なお,レベル1は最下位レベルのため,正答率を定め難い.本システムでは,これを0と記述すると,レベル2の正答率の1/2をレベル1の正答率とみなすこととした.
項目集合ファイルをワープロで作成する場合は,作成後テキスト形式に変換することになるが,ワープロ毎に,改頁符号の扱いが異なるので注意を要する.
作成した項目集合ファイルの内容は,検定プログラム(第一定位置引数をcとして起動する)で確認することができる.このとき,テスト項目の困難度と識別力(項目反応理論の2パラメータ・ロジスティックモデルを仮定する),隣接レベル間の正答率の差(分離度)の分布,正解の分布なども集計する(図6参照).
正解とする選択肢の分布に片寄りがある場合は,当て推量の受検者の学習水準を著しく高く評価してしまう人為的可能性が生ずるので,調整を要する(図6の例では,aが多く,bが少ない).
また,項目集合ファイルに含まれるテスト項目の困難度が広く一様に分布していない場合は,分布の薄い学習水準について,検定に要する出題数が増加することとなるので,テスト項目の追加を検討することが必要である.
3.5 オプション
参考までに,本検定プログラムのオプションの概要を以下に示す.
| 検定方式に関するもの | |
| -Sx/-S- | 出題順の指示/指示取消 |
| | (d:難から易,a:易から難) |
| -ERnn | 第一種の過誤(%表示) |
| 実用上の問題(2.4,3.1)に対応するもの | |
| -MAnn | 出題数の下限 |
| -LRnn | 最適選択の緩和(10%単位) |
| -CBnnnn/-CB- | 正答率の補正(項目集合ファイルの正答率を母数nnnnのデータとして補正する)/補正しない |
| その他 | |
| -IDxxxx | 検定履歴ファイルID |
| -L/-L- | 検定中に画面の右下に学習水準毎に相対尤度を色表示する/表示しない |
| -C8/-C16/-C- | 8色表示/16色表示/自動切り換え |
4.シミュレーション
適応型逐次検定方式の効果を見るために,シミュレーションを行った.詳細は,別の機会に報告する予定であるが,本稿では,適応型逐次検定システムの適用事例として,結果の一部を示す.
4.1 テスト項目プールの構成
1991年度の能力テストで実際に使われた日本語語彙の問題のうち,項目分析によって比較的良い判定を受けた201の問題で,テスト項目プールを作成した.図6に示した属性の分布図は,このテスト項目プールを評価した結果である.
4.2 シミュレーション結果
1000回のシミュレーションによって測定した統計的数値を表1に示す.このシミュレーションでは,第一種の過誤の指定は,10%としている.
表1の判定未了率とは,テスト項目プールにある全ての問題に回答しても,2.2の判定基準に達しなかったシミュレーションの割合である.201問と,小さなテスト項目プールであるにも拘らず,1%程度に留まっていることから,実用性は十分にあると言える.なお,テスト項目プールが無限であれば,理論的に,判定未了率は零となる.
表1の90%ラインとは,判定を終了したシミュレーションの90%が判定に要した出題数の最大値である.表1から,レベル5の受検者の検定では,ほとんどの(90%の)検定が,14問以内に終了することが分かる.
第一種の過誤の測定値は,レベル2〜レベル4について,6〜8%であり,指定した値より小さめになっている.学習水準の両端であるレベル1とレベル5については,この傾向は,更に顕著である.これは,多くのシミュレーションを観察すると,検定の後半に対立している仮説は一つの場合がほとんどであることから,理論上過誤を過大に評価する結果となっているためである.
図7に,検定に要した出題数の分布を示す.
なお,効果測定用に作成したテスト項目プールによるシミュレーションでは,固定出題型に比して,42〜55%出題数が削減される.
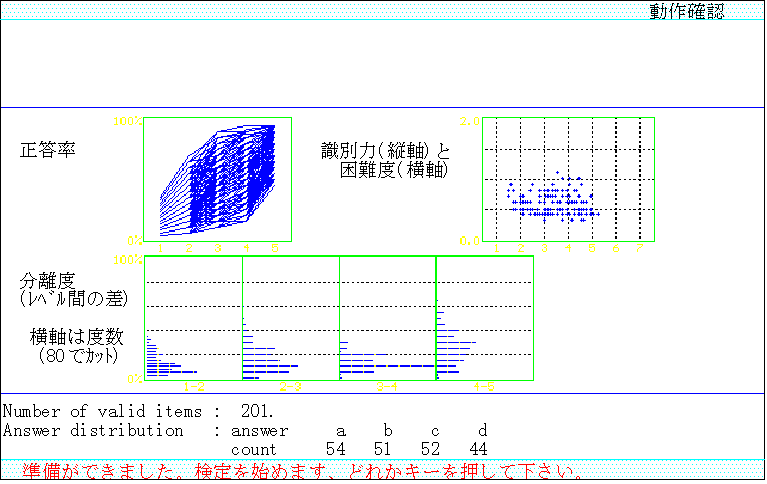
図6 テスト項目の属性の分布の表示画面
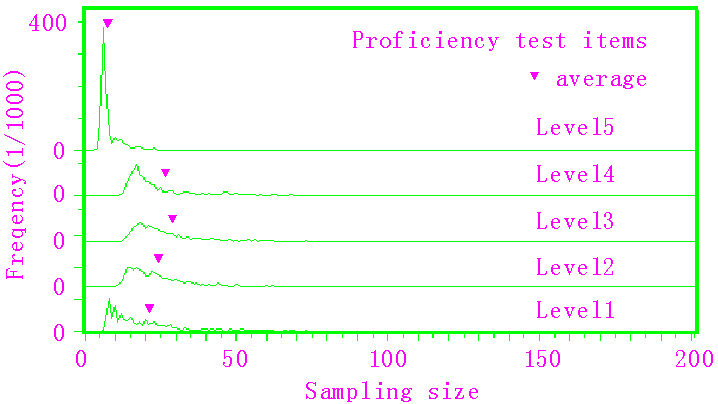
図7 適応型逐次検定の出題数分布
| | レベル1 | レベル2 | レベル3 | レベル4 | レベル5 |
| 判定未了率 | 0.6% | 0.3% | 1.1% | 1.2% | 0% |
| 平均出題数 | 21.7 | 25.7 | 29.5 | 27.0 | 8.4 |
| 90%ライン | 43 | 41 | 51 | 50 | 14 |
| 第一種の過誤 | 3.2% | 6.4% | 6.0% | 7.9% | 1.1% |
表1 適応型逐次検定のシミュレーション結果
5.むすび
本稿では,受検負荷が少なく,実用的な検定方法として,適応型逐次検定システムについて報告した.
4.で述べたシミュレーションによる測定結果から,本検定システムは,1.に述べた問題点に対する一つの解答として,十分実用に耐え得るものと考える.
適応型逐次検定の理論的枠組みについては,別に報告することを予定している.
今後,研究分担者によるテスト項目の作成(総計500項目程度)を待って,留学生を被験者とする実験を行い,作問から後処理までを含めた実用性を検討する予定である.
謝辞 本研究のきっかけを与えて戴いた東京工業大学教育工学開発センター赤堀侃司氏に感謝致します.
文献
| | (1) | 菊川健,吉沢将仁,川淵里美,竹本宣弘,佐藤隆博,竹谷誠,森本泰弘:“ITEM BANKING SYSTEMの開発 Ⅰ”,信学技報,ET76-6(1976). |
| | (2) | 永岡慶三:“マイクロ・アイテム・バンクの開発(1)−ソフトウェア構成−”,信学技報,ET84-2(1984). |
| | (3) | 芝祐順,野口裕之,南風原朝和:“語彙理解力測定のための多層適応形テスト”,教育心理学研究,26,4,pp.11-20(1978). |
| | (4) | 芝祐順,野口裕之,大浜幾久子:“多層適応形テストによる語彙理解力予備測定の効果”,東京大学教育学部紀要,19,pp.27-34(1979). |
| | (5) | 芝祐順,大浜幾久子,野口裕之:“在外日本人児童の日本語語彙理解力に関する調査”,東京大学教育学部紀要,20,pp.111-128(1980). |
| | (6) | 野口裕之,芝祐順,丹直利:“語彙理解力尺度の研究Ⅱ−項目固定版と適応形テストによる測定−”,東京学芸大学紀要1部門,34,pp.101-114(1983). |
| | (7) | 柴山直,野口裕之,芝祐順,鎌原雅彦:“最適化テスト方式による語彙理解力の測定”,教育心理学研究,25,4,pp.363-367(1987). |
| | (8) | 永岡慶三,植野真臣:“大学における情報教育環境としての適応型テストシステム”,信学技報,ET88-7(1988-12). |
| | (9) | 芝祐順編:“項目反応理論”,東京大学出版会(1991-9). |
| | (10) | Weiss D.J.(ed.):“New horizons in testing : latent trait test theoryand computerized adaptive testing”, Academic Press, New York(1983). |
| | (11) | Wainer H.(ed.):“Computerized adaptive testing : a primer”, Erlbaum,Hillsdale,N.J.(1990). |
Copyright (C) 1997 by KOBAYASHI Osamu. All rights reserved.
