 |
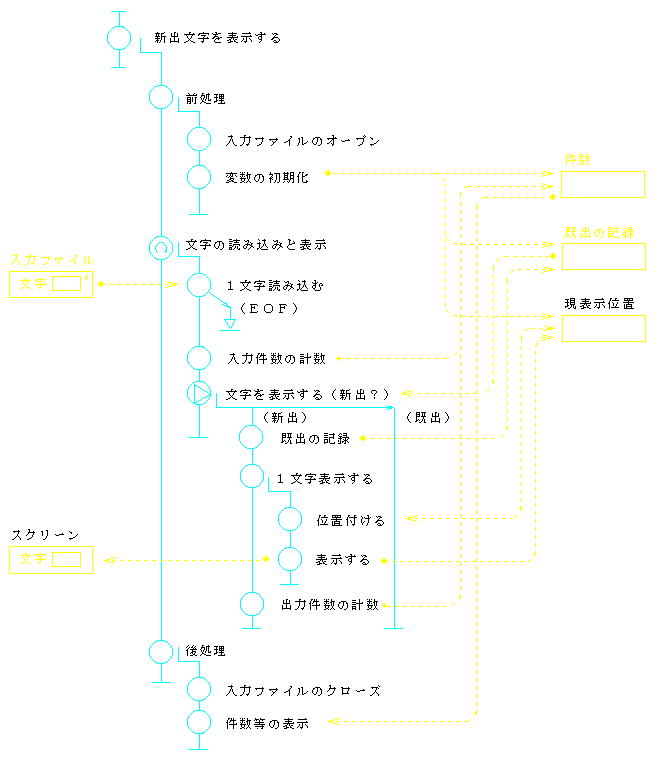
図6 構造化プログラム(例1)の流れ図
|
プログラミング教育は,情報専門学科の入門教育の他,他学科の教養科目でも,広く開講されている.また,初等・中等教育でも,授業が始まる.しかし,これら初等プログラミング教育の講義や演習の内容・方法論については問題点も多く,今も模索が続いているのが実状である.本稿では,プログラミングを「課題の表現」として捉え,初等プログラミング教育においては,「課題構造の理解とその表現」を中心として,構造的プログラミングを指導することを提案する. |
本稿では,専門教育の導入部である入門教育および初等・中等教育における初等プログラミング教育において重要と思われる指導の方法について考察する.
まず,プログラミングの過程について一般的に論じ,次に本稿の主題である初等プログラミング教育にこの考え方を適用し,最後に具体例を述べる.
プログラミングは,①課題の構造をどう認識するか,②どのプログラム言語で表現するか(課題の構造に適する言語を選択する),③使用する言語の表現力の制約下で課題をどう表現するか,④プログラム構造(データ構造と論理構造)をどう定めるか,そして最後に,コーディングという4つの段階を踏む.ただし,手順としては,②~④はほぼ同時に進行していると思われる.
この章では,プログラミングを課題理解の過程として捉え,プログラミングを一般的に論ずる.
プログラム言語の表現力について,まず自然言語の例を挙げよう.例えば,フランス語には,日本語でいう蝶と蛾に対応する単語はなく,両者を合わせてパピヨン(papillon)と呼ぶ.区別をしたいときは,「(昼の ?)パピヨン」,「夜のパピヨン(papillon de nuit)」と言うそうである.ここで注意したいのは,この現象は単に語彙の多寡の問題ではなく,自然認識の枠組み(概念)の問題だということである.日本語では,蝶と蛾は明確に区別される概念であり,好悪も正反対である.一方,フランス語では,両者は一体となって一つの概念を形作っている.言葉を替えて言えば,日本の文化を(フランスの文化を記述するのに適した)フランス語で説明するには本質的な困難が伴うのである.
同じような状況は自然科学にもある.物理学でしばしば使われるδ関数(ディラックの関数)は,数学的な関数ではなく“計算上のトリック”なので,扱いには十分な注意が必要である.しかし,物理を記述するための枠組みに超関数を導入すれば,何のトリックも要せず,しかも物理的な概念と整合的に記述することができる(ディラック測度に対応する).
このように,一般に,記述すべき内容に対して,記述の枠組みが貧弱である(表現力が弱い)と,記述そのものが不可能であったり,可能だとしてもさまざまなトリックを要することになる.
FORTRANとCOBOLの仕様を対比すれば明らかなように,プログラミングの場合(課題とそれを表現するためのプログラム言語の関係)も,同じ事情にある.プログラミングの初等教育の場合,プログラミングの本質的な点よりも,とかくコーディング(文法教育)に重点が移行してしまい勝ちである.ここに述べたような,情報を扱うことの原理的な問題は,幾ら強調しても,強調しすぎることはない.
この節では,課題の構造が理解の仕方に依存すること,およびその理解の仕方に応じてプログラム・コードが変わるべきであることを述べる.
課題を理解するとき,課題は必ず何らかの形で変形を受ける(=理解するということ).理解とは,既存の概念体系に新しい要素を取り込み,全体を再構成する手続きなのである.従って,対象物が理解の枠組みとは関わりなく存在すると考えるのは,余りにも素朴に過ぎる見方といえよう.
自然言語の例を挙げよう.日本語では,虹は七色であるが,本来連続しているはずの虹の色を,何故七色と考えるのだろうか.一方,英語圏では,同じ虹を六色に分けて見る,といわれる.更に,卑近な例として,擬音語がある.犬や鶏の鳴き声の「聞き做し」が日英で大きく異なっているのは何故だろうか.
このことはまた,課題の解法とも密接に関係し,良い記述の枠組み(道具立て)を使うと課題の表現は見通しの良いものになる.
数学の例を挙げよう.階乗計算 n!(ただし, n は正の整数)は,図1のように2通りの定義の仕方がある.
|
(a) n!=n・(n-1)・(n-2)・...・3・2・1 (b) n > 1 のとき n!=n・(n-1)!, そうでないとき n!=1 |
これをC言語で記述すると,それぞれの定義に応じて,図2のようになる(例外処理は含まず).
|
(a) long factorial(int n) { long f = 1L; while (n > 0) f *= n--; return (f); } (b) long factorial(int n) { if (n > 1) return (n * factorial(n-1)); return (1L); } |
図2のコードは,コンピュータ・プログラムあるいはC言語に特有の表現はあるものの(特にコード(a)),元の定義(図1)に極めて忠実に作られており,またこの仕様はポピュラーなものであるから,殆どコメントを要しない.どちらが理解しやすいかは,プログラム・コードの問題というより,仕様の記述の問題である.つまり,階乗計算という課題を,積の反復で理解するか,再帰的に理解するか,の違いである.
ここで話題は逸れるが,2.1.に関連して言えば,後者の理解の場合に,記述言語としてCOBOL等の再帰的でない言語を用いて表現するのは極めて困難である.つまり,言語の表現力が弱いために,コードの方に極端に負担が掛かってしまうのである.また,図1(a)の記述で,もし「...」が使えないとしたら,図1の記述のように,簡潔に表現するのは難しいことだろう(これは,日本語の表現力の問題).
本稿の結論を先取りして言えば,仕様の記述を十分に吟味し,仕様(a)からはコード(b)ではなくコード(a)を書くようにプログラミングを指導する.もし(b)というコードが出来上がったとすれば,仕様の検討をやり直させるようにする,ということを提案するものである.仕様(a)に対しては,コード(b)は誤りなのである.
課題は,その解法をコンピュータ化する際にも(コンピュータ向きに)変形を受ける.例えば,数値積分のモンテカルロ法,終わりを表すデータ“9999”を最後に置くように実行手続きを変更する,等.更に,インスタレーションのための変形も行われる.例を挙げれば,シミュレーションの際,ワイヤーモデルで代替する,等(これはコンピューテーションの話題である).
この種の変形は,課題の持つ固有の構造に損傷を与えることが多く,注意が必要である.事務処理をEDP化するときに,コンピュータ優先のシステムを作ってしまう失敗例が散見されるが,これも,この種の課題変形の結果と見ることができる.
この種の変形を無限定に行うと,課題構造とプログラム・コードの構造が乖離して,可読性をひどく損なうことになる.先に述べたように,初学者に対しては,この種の課題変形は避け,もし必要が生じたときは仕様に遡って検討し直すように指導することが大切である.
この項では,これまで述べてきた課題構造と表現方法を一致させる例として,フィルター構造について述べる.
課題の理解に際し,課題の構造が複雑な場合には,状況を整理するために論理的なボトルネック(チェックポイント)を設けると良い.
例えば,事務計算では,“領域Aのデータを使って処理Bをする.ただし,領域Aにデータがないときは,領域Cのデータを使う,”というパターンがあるが,これを,図3の(a)のように記述する代わりに,(b)のように記述する.
|
if (領域A=空) 処理B(領域C) else 処理B(領域A) |
|
/** ①領域Aの完成 **/ if (領域A=空) 領域A:=領域C /** ②処理Bの実行 **/ 処理B(領域A) |
これは,“まず,①領域Aを完成させる.次に,②領域Aのデータに処理Bを施す,”という課題の変形に対応する(領域Aの内容を変えても良いかどうかはここでは問わない).これにより,課題の構造が選択構造から,より理解の容易な連接構造に変形される.この場合の①は,②処理Bのための準備であり,先に述べた論理的なボトルネックである.つまり,いかなる場合もここを通過させることにより,後続の処理の実行条件を保証している.この意味で,この構造を,「連接構造」と言わずに,「フィルター構造」と呼ぶことにする.また,このような理解の仕方の方が,実際の事務処理の考え方と辻褄が合うケースも多々あると思われ,その時はこのような記述をすると見やすく理解しやすい.単なる習慣から常套句として構造(a)で記述することは止めた方が良い.このフィルター構造は,ある種の汎用機用オペレーティング・システムで,DCBを完成するプロセスに見ることができる.
また,多くのプログラムでは,初期化処理に失敗したときはその旨通知して停止するように組まれるが,この場合も,図4(a)のように長かるべき主処理をifの中に埋め込んでまで goto文を避ける(いわゆる「構造化プログラミング」)よりも,図4(b)のように適切に goto文を利用することにより,実質的なフィルター構造にした方が,見やすいと思われる.この場合の goto文は,実行順序の変更というよりも,通常の処理からの離脱を表している.従って,理解の妨げとはならず,この場合, goto文は必ずしも有害ではない.
|
初期処理 if (初期化成功) 主処理 else 異常通知 終了処理 |
|
初期処理 if (初期化失敗) 異常通知 goto exit end< BR> 主処理 exit: 終了処理 |
goto文を使わず,連接・選択・反復の3パターンで記述するのが「構造化プログラミング」だという説がある.本稿では,これに対して,課題を表現するのがプログラムであり,その構造を主軸に据えた記述方式を構造的プログラミングと呼ぼうと提案している.この節では,「構造化プログラミング」でよく言われるトップダウン・アプローチと階層性について考える.また,これから,カプセル化の概念が自然に導かれることを述べる.
トップダウン・アプローチの有効性・必要性は疑問の余地はない.筆者自身のプログラミングを考えても,プローブとして作るプログラムを除き,ターゲットとなるプログラムは,開発のどの時点においても,プログラムとして何らかの動作をするように作っており(即ち,文法的には完成されている),何もしないプログラムが次第に機能を獲得して最終的に目標に達する,というプロセスを経る.しかしながら,実際の設計の過程を振り返ってみると,設計の進行方向は必ずしもトップからダウンへではないし,ある時点での考察の範囲も水平方向(同一階層内)だけでなく深さ方向にも及んでいる.ベテランのプログラマーであれば,ある階層の設計を,遥か下層のインスタレーションを頭の隅に描きながら,行なっているのではなかろうか.皮肉な言い方をすれば,トップダウン・アプローチが最も有効なのは,既にできあがったものを整理して説明するときなのである.トップダウン・アプローチで指導したとき,初学者が戸惑うのは,こういった点が配慮されていないことも理由の一つだと思われる.
そもそも,人が一度に把握できる要素の数には限りがある.ここでは「一瞥の範囲」と呼ぶことにする.一例を挙げれば,量を表すのに,「ビール瓶何百万本」というより「霞が関ビル7杯分」という,つまり数字の部分が十前後になるように単位を選ぶと実感が湧きやすいそうである.
この事情は,プログラミングの前段である課題の構造を把握するときも同じだと思われる.課題を,一瞥可能な範囲で要素に分割し,更にその一つの要素を詳細化する.当然その時は,他の要素のサイズは相対的に大きくなる.その結果として,段階的詳細化の方法と階層構造ができあがるのである.従って,課題の構造と関係なく行った「階層化」は,可読性を損なう恐れが多分にある. 余談になるが,この分析的理解に対し,多数の要素を含む総体を一挙に(統合的に)理解している場合は,これを手続き型のプログラム言語で表現するのは極めて困難である.手続き型言語は本質的に経時的線型的な表現しか許さないからである.譬て言えば,手続き型言語は,和音を音波の時系列波形で分析するようなものであり,アルゴリズムを書くのは至難の技である.しかし,これをフーリエ変換した周波数軸で考えれば,さほど難しくはない(周波数軸の一点は,波形の時間軸ではその全域に分散していることに注意されたい).非手続き型言語は,手続き型言語に対して,このような「軸の転回」に相当していることが多い.話は変わるが,尾形乾山の角皿を見て,筆者はとても良いと思うのだが,評論家ならぬ身には,その理由を分析的に説明することはできない.せいぜい,「その筆致が,衒うことなく自在であるのが良い,」等と言うのみである.これは,陶画上の一点一点ではなく,その総体,「感性の軸」上の問題なのであり,筆者には,理論的に,その「軸の転回」ができないので,説明に窮するのである.
これらは,2.1.で述べた言語の表現力の問題であると考えることができる.上述の各「軸」に相当する表現の枠組みの違いが,それによる表現を単純にも複雑にもするのである.このことから,階層性は言語の表現力に依存するという重要な視点に導かれる.また,プログラム言語の選択がいかに重要であるか,が分かる.
前項では,階層性が人間の理解機構の性質による自然な結果であり,単なるコード分割の結果ではない,ということを述べた.従って,個々の要素は,単なるコードの集合体ではなく,それに固有な何らかの意味(ここではいくつかの機能の総体と考えておく)を有していることが分かる.
例えば,スタックは,後入れ先出しの記憶機構であり,それを要素とする階層から見れば,push/popという機能群として現れる.そして,この階層から見る限り,push/popを通してのみスタックにアクセスすることができ,また,この2つの操作によってスタックの概念を余すことなく定義することができる.即ち,これはオブジェクトの概念そのものであり,カプセル化であるといって良い.階層化とはカプセル化に他ならないのである.ここに,階層性の本質がある.
以上述べてきたことから,プログラミングは,課題の持つ構造(これは,理解の仕方で異なり得る)を壊さないで,プログラム言語で表現することだ,とまとめることができる.以下に幾つかの例を挙げよう.
数値(リーマン)積分を,台形公式で実現するか,モンテカルロ法で実現するか.課題の構造から見ると,前者は同型で,後者は変形されている.もっとも,これが数値ルベーグ積分なら,モンテカルロ法の方が理念(構造)的には近い.
一方,土地の線引き問題等では,求積は課題の主構造ではなくそれを構成する要素の一つであるから,数値積分はマクロ(関数,サブルーチン等)化されているべきであり,その実現法は問題にはならず,それはむしろコンピューティングの主題となる.
事務計算に現れる集計のロジック(課ごとに給与の総額を計算する等)では,普通何らかの“先読み”が行われるが,C言語でいう ungetc の機能(読み込みを取り消す機能)があれば,ずっと見やすい論理が書ける.しかし,COBOLにはこの機能がないから,コードに負坦が掛かり論理構造が見え難くなってしまうのである.“先読み”は,自然な構造ではなく,プログラミング上の技巧の一つなのである.(3.2.参照)
これまで述べてきたように,プログラムとは,詰まる所,課題の表現である.そして,それを読むのは,コンピュータではなく,人(プログラマー)である.何故,高水準言語で記述するかといえば,それは人が読み,人が書くものだからである.つまり,「良いプログラムとは,可読性の高いプログラムである,」と言えよう.その根幹を成すのが,論理構造の理解しやすさである.コーディング・テクニックを駆使したプログラムではなく,課題の構造を素直に表現したプログラムが良い.メモリー性能・時間性能は,コンパイラの責任である,といったら言い過ぎであろうか.ご存知の通り,Kernighan etal.(1982)は,FORTRANのk=(i/j)*(j/i) というコードの例を挙げて,その愚を戒めている.
可読性を支えるもう一つの要素は,見た目の分かりやすさ,明示性である.文章でいえば,句読点の使い方や段落の分け方等といったことである.コーディングに置き換えれば,データ名の付け方やコメント,空行,空白の置き方等に注意すると格段に読みやすいコードになるものである.
プログラミング入門のテキストを見ると,段付け等には触れているものの,変数名等の付け方はぞんざいなものが多い.変数名やCOBOLの節・段落名が,「名は体を表し」ていないことが多い.また,変数名等がローマ字になっているのは,いかがなものか.ローマ字表記の善し悪しは,多分に好みの問題ではあろう.しかし,プログラム言語の多くが元来英語であることから,その中にローマ字が混じるのは,存外に見苦しいものである.「良いプログラムは,見やすいプログラム」の見地からも,手間を惜しまずに英語を使った方が良い.辞書を片手に,良い変数名を探すのも,プログラミングの内ではなかろうか.変数の目的にかなった名前を探すことにより,逆に各変数の存在理由を理解し,型が同じだからといって変数を流用したり,プログラムの初めと終わりで使い方が異なったりするようなことは少なくなるのではなかろうか.
コメントの入れ方も大切な指導の対象である.基本は,「コメントがなくても分かるコードを書く」ことであり,先の k=(i/j)*(j/i) の個所に「i=j のとき 1 それ以外のとき 0」とコメントを書くのは本末転倒といえよう.アセンブラや変数の用法等の場合を除き,行ごとのコメントは煩わしいものであるし,多過ぎるコメントは,コードとコメントが乖離する誘因ともなる.コメントの量は,プログラムの全体の構造が分かる程度が目安となろう.コメントを入れた場所やその内容は,プログラマーの課題に対する理解の程度を表しているので,大いに指導上の参考になるだろう.
さて,初等プログラミングを指導する上で,留意すべき点を考えてみよう.これまでも触れてきたが,可読性,明示性,そして後で述べる頑健性に留意して指導することを,本稿では提案したい.
可読性の基本は,論理構造にあり,分かりやすい構造にするには,課題そのものの理解が欠かせない.しかし,残念ながら筆者の知る限りでは,コーディングに重点を置き過ぎている.課題構造に目を向けさせるには,コーディングに入る前に,彼らが最も得意としているはずの日本語(自然言語)で,課題を記述させると良いだろう.2.4.で触れた集計の例でいえば,キーである課コードが替わったとき,人手による集計作業の場合,何が起こっているのかを考えさせる.何気なくしている処理過程を客観化してみれば,キー・ブレークの検出には,何らかの先読みが必要なことが分かるだろう.人手による集計作業の場合,先読みされたデータは一旦棚上げされ,キー・ブレークの処理に入り,これが終わった後,棚上げされたデータが再び取り出される.2.4.で述べたように,C言語でいう ungetc の機能があれば極く自然に記述できる部分である.この際,いわゆる疑似言語を使う手もあろうが,これに拘る必要はなく,むしろ各自工夫して書いてみることが必要だと思われる.その成果をクラス内で互いにプレゼンテーションしてみれば,客観化の程度や理解の仕方の違い等が実感できよう.この課題構造の把握が徹底できれば,例題を引き写すだけのパターン・コーディングは少なくなるだろう.
課題構造が理解できたら,それを具体的に表現する.使用言語は,先に述べたように,疑似言語でも自然言語でも良いだろう.ただし,文章にするのではなく,論理構造が分かるように,適当に記号を使いながら箇条書きにする(つまり,自分の疑似言語を作る).その際は,「取扱い可能な大きさで論理構造を考える(階層性,局所性),「フィルター構造」等に留意する.なお,この点でいえば,CRT上で編集させることは,好ましい効果があると思われる.CRT画面は通常二十数行から成っているので,一つの論理的な構成単位を長大に書き下すと自分でも読めなくなってしまう.従って,書き下しの抑止効果が期待できるだろう.この点からも,演習環境の整備が望まれる.
十分に具体的な表現になったら,ここで初めて現実のプログラム言語のコードで記述する.その際は,3.1.で述べた変数名等の付け方,コメントの入れ方,段付け,空行の入れ方等に留意すると良いだろう.
できあがったコードは,学生相互にデバッグし批判し合う.勿論,相手のプログラムのデバッグには,自分で用意したテスト・データを用いる.うまく作られたテスト・データを使えば,バグの検出率も高くなるというわけである.この相互批判の過程の中で,仕様を綿密に読むこと,漏れのないテスト・データの作り方,デバッグの難しさ,そして優れたプログラムとは何かを学ぶはずである.(筆者は,教育実習で次のような方法を試みたことがある.練習問題を生徒に割り当て,黒板に解答させるのだが,その説明を解答者ではなく他の生徒にさせてみた.いつもの自分達の解答がいかに読み難く判り難いものか身をもって知る等の効果は期待できるのではなかろうか.)ゆめゆめ,僅かなテスト・データを教員が用意して済ませることのないようにしたいものである.
ここで,これまで述べなかったが,プログラムの「頑健性」について述べておきたい.頑健性とは,誤ったデータまたは論理に対する耐性である.例えば,反復の終了条件を記述するときは,等式ではなく不等式を使うと良い.何故なら,等式では,ループを離脱できるのは,制御変数の値域の内ただ一点だけであり,これに掛からなければ,無限ループに陥る危険性があるからである(図2参照).入力データに関する耐性についても同様で,論理的に明確に規定できる場合にデータ・チェックを行うのは当然として,それができない場合でも可能な限り目視チェックに掛かりやすいようにすべきである.
最後に,結論めいたことを言えば,コーディングそのものよりも,プログラミングの前段である課題構造の理解に重点を置き,構造を理解した上で,それに応じた詳細化による設計と可読性・明示性・頑健性等を基準としたコーディング(初歩的な構造的プログラミング)を指導することを提案したい.決して,「トップダウン・アプローチ」をトップダウンに押し付けることのないようにしたいものである.
この章では,具体的なプログラミングの演習課題とその解答例を示し,論評する.プログラム言語は,ここではC言語を使用する.
演習課題を図5に示す.
|
キーボードまたはファイルから,文字列を読み込 んで,初出の文字のみを出現順に表示する. ファイル入力の場合のファイル名は,既定のもの としてよい.各自で定めよ. 読み込んだ文字のコードは,8ビット系と仮定し てよい. 文字の表示の仕方は,各自で工夫せよ. EOFのとき,プログラムは終了する. |
以下のプログラム例では,プログラムは,キーボード入力として作成し,ファイル入力は,リダイレクトにより実現することとする.ただし,入力ファイルのオープンおよびクローズは,それを明示するために,コメントの形で,プログラム・コード中に残しておくことにする.
4.2. 構造化プログラミング例
構造化プログラミングの通例と思われる流れ図(HCPチャート(花田收悦 1983 )で記述した)を,図6に示す.また,図7は,この流れ図に添ったプログラム・コードである.
|
|
/*============================= Sample1 .c ==============================*/
#define TRUE 1
#define FALSE 0
#define SUB 0x1A /* Substitute コード */
#define MAXCODE 255 /* 文字コードの最大値 */
/*-----------------------------------------------------------------------*/
void main() {
#include <stdio.h>
#include <conio.h>
#define END SUB /* 入力終了コード */
#define LEFT 5 /* 表示範囲の左端 (0-79) */
#define RIGHT 15 /* 表示範囲の右端 (0-79) */
int InCounter, OutCounter; /* 入力・出力件数 */
int CurrentCol; /* 現表示位置 (0-79) */
int Already[MAXCODE+1]; /* 既出フラグのテーブル */
int i; /* 整数型 作業領域 */
int c; /* 文字用 作業領域 */
/*---/ 前処理 /-------------------------------------------------------*/
/*-- オープン --*/
/* fopen stdin */
/*-- 初期化 --*/
InCounter = OutCounter = 0;
CurrentCol = LEFT-1;
for (i = 0; i <= MAXCODE; Already[i++] = FALSE);
/*---/ 主処理 /-------------------------------------------------------*/
while( (c = getch()) != END) {
++InCounter;
if (!Already[c]) {
Already[c] = TRUE;
if (CurrentCol >= RIGHT || CurrentCol < LEFT) {
printf("\n%*s",LEFT,"");
CurrentCol = LEFT;
}
printf("%c", c);
++CurrentCol;
++OutCounter;
}
}
/*---/ 後処理 /-------------------------------------------------------*/
/*-- クローズ --*/
/* fclose stdin */
/*-- 件数の表示 --*/
printf("\n\n");
printf("%*s入力文字数 = %d" "\n", LEFT, "", InCounter);
printf("%*s表示文字数 = %d" "\n", LEFT, "", OutCounter);
}
/*=========================== End of Sample1 .c =========================*/
|
このプログラム例1は,3.1.に述べた要件に従って,記述されている.連接・選択・反復で構成され,適度に段付けされており,紛れもない「構造化プログラム」である.更に,変数名は,英単語を基準に命名され,その定義には,使用目的が明示されている.記号定数も,また同様である.まずまずの出来のプログラムと言って良いだろう.手慣れたプログラマーなら,こう書くだろう,そんなプログラムである.
しかし,このプログラムは,構造的プログラミングの産物ではない.図6の流れ図を見れば分かるように,このプログラムは,前処理・主処理・後処理の3要素から成っているが,3種類の変数は,必ずしもグローバルな変数ではないのに,一つならず2~3の要素と関わっている.これは,プログラム論理の構造と変数の構造に齟齬があることを示している.
実際,この課題は,読み・チェック・表示の繰り返しと理解するのが,最も自然であろう.このように考えたとき,例1の3種類の変数(「件数」は2つあるので,4つの変数)は,各々,一つの要素としか関わらないはずである.然るに,この3つの要素の,各々一部が,このプログラム例1では,第1レベルの3要素(前処理・主処理・後処理)に散在している.それで,各変数は多くの要素と関わることになるのである.
即ち,このプログラム例1は,課題の自然な構造を反映しておらず,論理とデータの構造に不一致がある.従って,構造的プログラムではないのである.
この例1のように,初期化処理を前処理の中に一括して置くことは,プログラマーなら誰しもが習慣的に行っていることであるが,構造上の吟味をすることを忘れてはならない.よくあることだが,もし二重ループの内側のループのための初期化を外側に置くような間違いをしたとすれば,構造的プログラミングについてもう一度学び直す必要があるだろう.
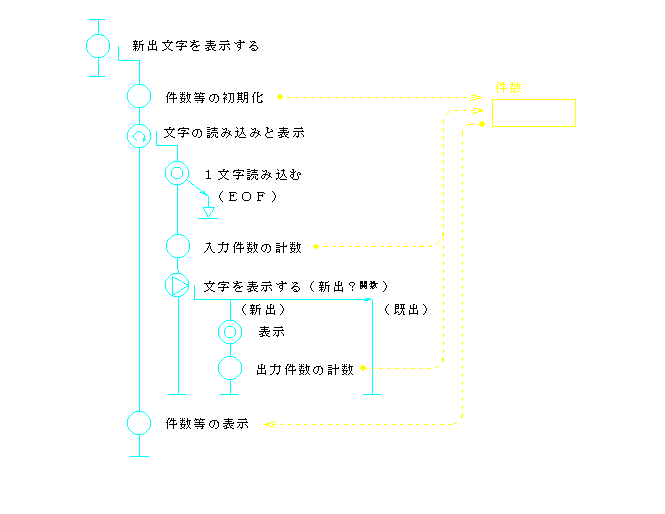
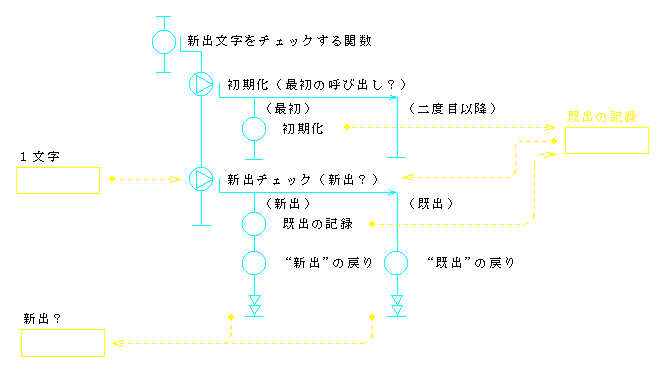
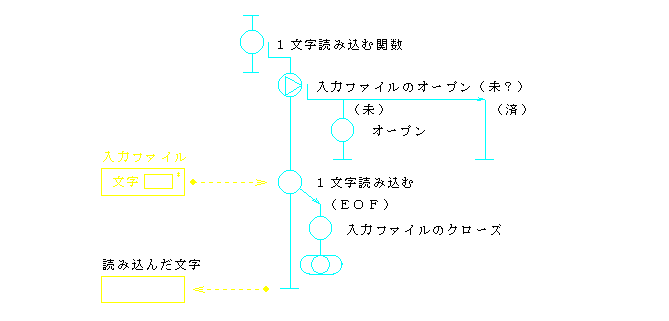
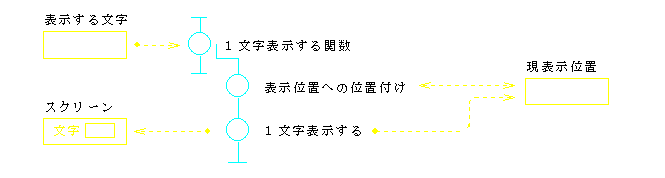
前節のプログラム例1に対して,構造的プログラムの例を図8(流れ図)と図9(コード)に示す.
    |
/*============================== Sample2 .c =============================*/
#define TRUE 1
#define FALSE 0
#define SUB 0x1A /* Substitute コード */
#define MAXCODE 255 /* 文字コードの最大値 */
#define LEFT 5 /* 表示範囲の左端 (0-79) */
#define RIGHT 15 /* 表示範囲の右端 (0-79) */
int NewCharacter (unsigned char c);
int GetANextCharacter (void);
void DisplayACharacter (char c);
/*-----------------------------------------------------------------------*/
void main() {
#include <stdio.h>
#define END SUB /* 入力終了コード */
int InCounter, OutCounter; /* 入力・出力件数 */
int c; /* 文字用 作業領域 */
/*---/ 初期化 /-------------------------------------------------------*/
InCounter = OutCounter = 0;
/*---/ 主処理 /-------------------------------------------------------*/
while( (c = GetANextCharacter()) != END) {
++InCounter;
if (NewCharacter(c)) {
DisplayACharacter(c);
++OutCounter;
}
}
/*---/ 件数の表示 /---------------------------------------------------*/
printf("\n\n");
printf("%*s入力文字数 = %d" "\n", LEFT, "", InCounter);
printf("%*s表示文字数 = %d" "\n", LEFT, "", OutCounter);
}
/*--- Functions ---------------------------------------------------------*/
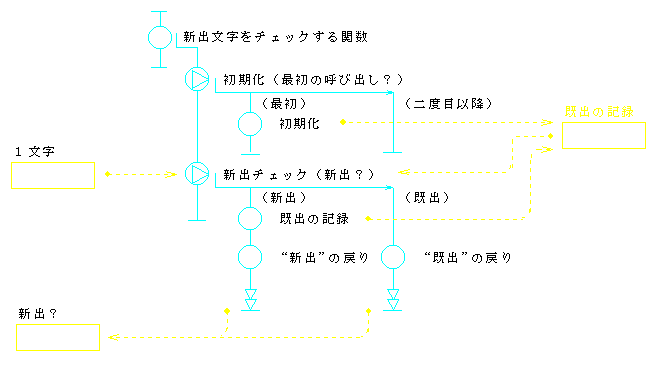
int NewCharacter(unsigned char c) {
static int ForTheFirstTime = TRUE; /* “最初の呼び出し”フラグ */
static int Already[MAXCODE+1]; /* 既出フラグのテーブル */
int i; /* 整数型 作業領域 */
if (ForTheFirstTime) {
for (i = 0; i <= MAXCODE; Already[i++] = FALSE);
ForTheFirstTime = FALSE;
}
if (!Already[c]) {
Already[c] = TRUE;
return (TRUE);
}
return (FALSE);
}
/*-----------------------------------------------------------------------*/
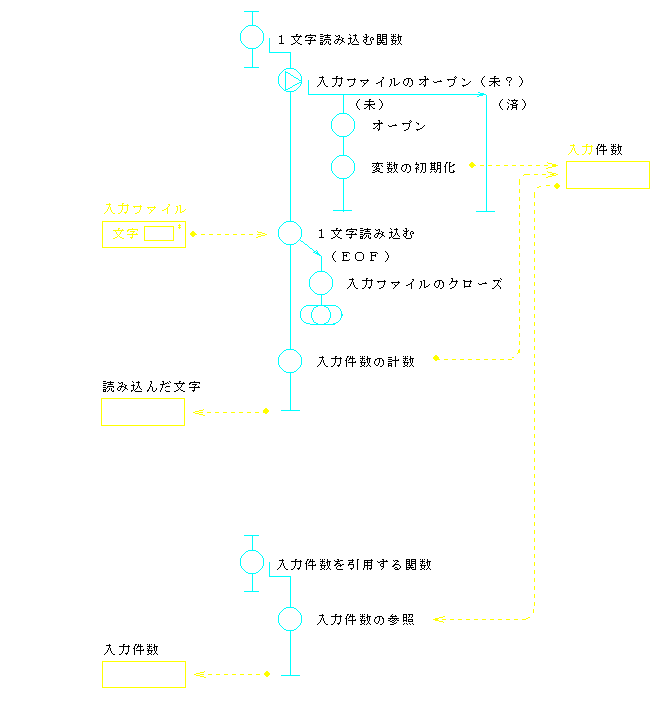
int GetANextCharacter(void) {
#include <stdio.h>
#include <conio.h>
static int Opened = FALSE; /* “オープン中”フラグ */
int c;
if (!Opened) {
/* fopen stdin */;
Opened = TRUE;
}
c = getch();
if (c == EOF || c == END) {
/* fclose stdin */;
Opened = FALSE;
c = END;
}
return (c);
}
/*-----------------------------------------------------------------------*/
void DisplayACharacter(char c) {
#include <stdio.h>
static int CurrentCol = LEFT-1; /* 現表示位置 (0-79) */
if (CurrentCol >= RIGHT || CurrentCol < LEFT) {
printf("\n%*s",LEFT,"");
CurrentCol = LEFT;
}
printf("%c", c);
++CurrentCol;
return;
}
/*========================== End of Sample2 .c ==========================*/
|
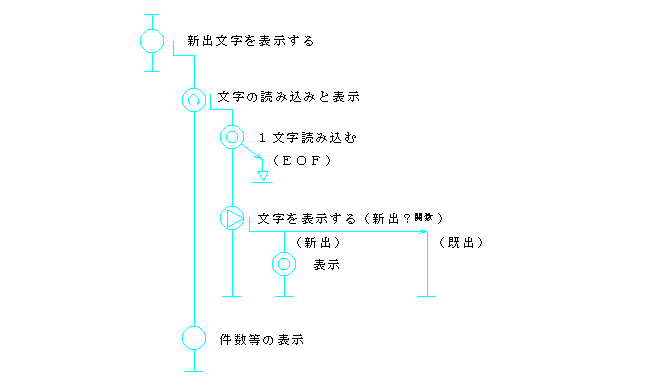
このプログラム例2では,前節で述べた,読み・チェック・表示の繰り返しという自然な構造がそのままに表現されている.3つの要素は,各々独立した関数として記述され,繰り返しは,全体の流れを司る最上位(main)関数として表現されている.入出力件数を数えることも,最上位レベルの中で考える限りにおいて,ごく自然に位置付けられていて,プログラム・コードを読む妨げにはなっていない.
また,3.1.で述べたことだが,関数名がその働きを示すように名付けられていることに留意されたい.COBOLでは,「MAESHORI」等と言った段落名を使っている例を時々見かけるが,この例2のように,「名が体を表している」と,コードがとても読みやすくなる.
ところで,入出力件数の計数は,それぞれ「読み」または「表示」の役割と考えることもできる.例えば,「読み」の中で,制御コード等の表示できない文字を読み捨てるようにしたとすれば,入力件数を上位の関数で知ることができなくなるからである.このように考えると,「読み」の果たすべき役割は,入力ファイルのオープン,文字の読み込み,入力件数の計数,入力文字の引き渡し等となる.2.3.で述べたカプセル化の概念に従えば,これらは,一つのモジュールとして実現されるべき機能群ということになる.このように課題を解釈したときのプログラム例3を,図10(流れ図)と図11(コード)に示す.
   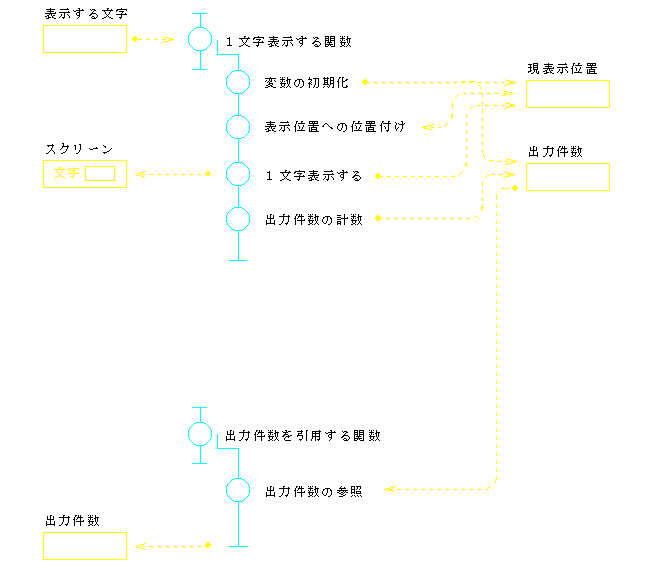 |
/*============================= Sample3 .h ==============================*/
#define TRUE 1
#define FALSE 0
#define SUB 0x1A /* Substitute コード */
#define MAXCODE 255 /* 文字コードの最大値 */
#define END SUB /* 入力終了コード */
#define LEFT 5 /* 表示範囲の左端 (0-79) */
#define RIGHT 15 /* 表示範囲の右端 (0-79) */
/*========================== End of Sample3 .h ==========================*/
/*============================= Sample3a.c ==============================*/
#include "sample3.h"
#include "sample3b.h"
#include "sample3c.h"
static int NewCharacter (unsigned char c);
/*-----------------------------------------------------------------------*/
void main() {
#include <stdio.h>
int c; /* 文字用 作業領域 */
/*---/ 主処理 /-------------------------------------------------------*/
while( (c = GetANextCharacter()) != END) {
if (NewCharacter(c)) {
DisplayACharacter(c);
}
}
/*---/ 件数の表示 /---------------------------------------------------*/
printf("\n\n");
printf("%*s入力文字数 = %d" "\n", LEFT, "", GetInCount());
printf("%*s表示文字数 = %d" "\n", LEFT, "", GetOutCount());
}
/*--- Functions ---------------------------------------------------------*/
int NewCharacter(unsigned char c) {
static int ForTheFirstTime = TRUE; /* “最初の呼び出し”フラグ */
static int Already[MAXCODE+1]; /* 既出フラグのテーブル */
int i; /* 整数型 作業領域 */
if (ForTheFirstTime) {
for (i = 0; i <= MAXCODE; Already[i++] = FALSE);
ForTheFirstTime = FALSE;
}
if (!Already[c]) {
Already[c] = TRUE;
return (TRUE);
}
return (FALSE);
}
/*========================== End of Sample3a.c ==========================*/
/*============================= Sample3b.h ==============================*/
extern int GetANextCharacter (void);
extern int GetInCount (void);
/*========================== End of Sample3b.h ==========================*/
/*============================= Sample3b.c ==============================*/
#include "sample3.h"
static int InCounter; /* 入力件数 */
/*-----------------------------------------------------------------------*/
int GetANextCharacter(void) {
#include <stdio.h>
#include <conio.h>
static int Opened = FALSE; /* “オープン中”フラグ */
int c;
if (!Opened) {
/* fopen stdin */;
Opened = TRUE;
InCounter = 0;
}
c = getch();
if (c == EOF || c == END) {
/* fclose stdin */;
Opened = FALSE;
c = END;
}
else {
++InCounter;
}
return (c);
}
int GetInCount(void) {
return (InCounter);
}
/*========================== End of Sample3b.c ==========================*/
/*============================= Sample3c.h ==============================*/
extern void DisplayACharacter (char c);
extern int GetOutCount (void);
/*========================== End of Sample3c.h ==========================*/
/*============================= Sample3c.c ==============================*/
#include "sample3.h"
static int OutCounter = 0; /* 出力件数 */
/*-----------------------------------------------------------------------*/
void DisplayACharacter(char c) {
#include <stdio.h>
static int CurrentCol = LEFT-1; /* 現表示位置 (0-79) */
if (CurrentCol >= RIGHT || CurrentCol < LEFT) {
printf("\n%*s",LEFT,"");
CurrentCol = LEFT;
}
printf("%c", c);
++CurrentCol;
++OutCounter;
return;
}
int GetOutCount(void) {
return (OutCounter);
}
/*========================== End of Sample3c.c ==========================*/
|
このプログラム例3は,6つの関数を含む3つのファイルと3つのヘッダー・ファイルから成る.例えば,「読み」のファイル(モジュール)には,読み込んだ文字を引き渡すための関数と入力件数を通知するための関数があり,入力件数の領域は static 宣言されているので,外部からは見えない.従って,このモジュールは,2つの関数を通じてのみアクセスすることができる,即ちカプセル化されている.「表示」モジュールも,また同様である.
以上,例1と例2~3を比べれば,いわゆる「構造化プログラミング」や「トップダウン・アプローチ」と本稿で述べた「構造的プログラミング」の違いは,明かであろう.
初めにトップダウン設計ありき,ではなく,初心者には,課題を理解し表現することから始め,誰にも理解しやすい構造のコードを記述できるように指導することが重要なことと思われる.その経験の中から,階層化,カプセル化,トップダウン・アプローチが自然に身に付いて行くに違いない.
初等プログラミング教育の現場を見聞きし,またそれに携わった者として,現状の反省に立ち,その教育方法について,思う所を述べた.
概して言えば,高等専門学校以降の中等・高等教育において, goto文弊害論やトップダウン・アプローチの言葉のみが一人歩きしすぎているように思われる.5文字7文字5文字の言葉をただ並べても俳句にはならないように,ただ連接・選択・反復構造で記述しても「構造的プログラミング」にはならない.初学者に対して,無味乾燥なプログラミング教育が行われることのないように期待したい.そのための議論に話題を提供できれば,本稿の目的は達したことになる.
なお,本稿は,小林修(1991)に基づき,4.を全面的に差し替え,加除訂正したものである.重複個所は多いが,論旨を保つためと,参考文献の流通性を考慮し,再録した.ご容赦を乞いたい.