| 学習評価のための適応型逐次検定 |
| 小林 修 |
| あらまし 本論文では,能力テストの一方法として,適応型逐次検定を提案する.能力テストは,①受検者の学習水準と隔たった問題が多数含まれ,受検意欲を殺ぐ,②検定精度を確保するために問題数が多くなり,受検負荷が大きい,などの問題点を抱えている.これらを解決するために,結果が正誤で判定されるテスト項目をあらかじめプールしておき,この中からコンピュータにより選択出題するシステムを考え,その検定法として,多重並立仮説の場合に拡張した逐次検定を,テスト項目の選択法として,適応型選択を,提案する.本検定方式では,プールするテスト項目には,学習水準別の正答率だけが付与される.シミュレーションによる測定では,固定出題型に比べ,出題数は半減し,受検負荷が少なく,実用的な検定方式であることが確認できた. |
本論文では,学習水準の検定のためのコンピュータによる適応型逐次検定について論ずる.出題する問題は,結果が正誤で判定される形式であることを前提としており,本論文では,留学生向け日本語語彙能力検定にこれを適用する.
著者の所属する短大には,留学生別科が開設され,約50名の留学生が日本語を学習している.習得した日本語能力は,年6回測定・評価される(能力テスト)が,この中の日本語語彙能力の測定では,四肢択一形式の問題50数問を20分程で回答し,5つのレベル(1が最低レベルで5まで)に判定される.また,出題した問題は項目分析に付され,適合性が検討される.能力テスト(proficiency test)に出題される問題のレベルは,テストの性格から,レベル3〜4を中心に,その前後に比較的均等に分散されている.この状況から,いくつかの問題点が指摘できる.
これらの普遍的な問題点を解消するために,項目反応理論に基づく適応形テスト(3)-(11)や,コンピュータを利用してテスト項目プールからテストを構成するシステム(1)-(2)などが試みられてきた.前者は,前掲の問題点の中では,主として①と②に関わるものであるが,前提とする項目反応理論の制約(測定対象の一次元性と測定項目間の独立性)があることと,パラメータ(困難度と識別力)の安定した推定のためにかなり大量のデータを要し,そのテスト・システムを教育現場で個別に作成・利用するというより,規範性のある検定として,他の機関からの供給を受けて利用するという形態がより相応しいものである.テストの実施は,印刷物による場合(3)-(5),(9)とパーソナル・コンピュータによる場合(6)-(11)が報告されている.なお,逐次検定による合否判定法と適応形テストとの比較研究(10)が報告されている.合否の対象となる能力θがθcを越えるとき合格とすれば,この複合仮説に対する検定を,θ1<θc<θ2となるθ1,θ2を適当に定め,θ=θ1,θ=θ2の2つの単純仮説の対立に帰着させることにより,3.1に述べる逐次検定を適用する方法である.θ1,θ2をどう定めるのか基準がないことと,報告によれば,合否判定の誤りが予想を大幅に上回るケースがあるなど,実用上も理論的枠組みにも,弱点がある.
一方,後者のテスト構成支援システムは,③と⑤に関わる先行研究である.まとまった数のテスト項目を正答率や相関係数などと共にプールしておき,教師の操作により適切なテスト項目を選択,テストの統計的特性を推定し確認した後,そのテストを確定・作成する.テストは,印刷物によるか,パーソナル・コンピュータ上で実施される(この場合,前掲③の問題点の解消が可能である)が,いずれにしても,テストの実施に先立ってそのテストを構成するもの(固定出題型)であり,前掲の問題点①②④に対しては,あらかじめ多種類のテストを用意しておくなど,部分的な解答しか与えることができない.テスト項目に付与する情報も量的に多く,質的にも,ある程度の精度の推定値を得るために,まとまった量の事前調査とデータ処理を要するものが含まれている.
本論文では,これらの先行研究を踏まえ,前掲の問題点①〜⑤に対する一つの解答として,多重並立逐次検定方式およびこれに基づく,コンピュータによる適応型逐次検定を提案する.この検定方式は,(ア)特定のテスト理論や能力構造に依らず,統計的に処理を行うこと,(イ)教育現場で容易に適用できること,を条件とし,(ウ)テスト項目は,結果が正誤によって判定される形式であること,を制約として研究され,前掲の問題点①〜⑤に対応して,以下の利点を持つ.
以下,本論文では,適応型逐次検定方式に関する上記①②⑤⑦について論じ,本検定システムの実現法に関係する③④⑥については,別の機会にゆずる.
この章では,適応型逐次検定(adaptively sequential testing) の基本的な考え方について論ずる.
本検定方式では,結果が正誤で判定されるテスト項目を多数用意し,これを逐次,受検者に提示し,これに対する受検者の反応を測定して,その受検者の学習水準を検定する.この際,特定の能力構造やテスト理論を仮定することはしない.
プールするテスト項目には,検定する学習水準に対応して,あらかじめ正答率を付与しておき,回答の正誤と所与の正答率から得られる尤度(付録1参照)により,最大尤度を示す学習水準をもって受検者の学習水準と判定する.このときの出題打切りの条件は,通常の逐次検定と同じく,尤度比が判定のグレイゾーンを外れた時点とする.尤度比は,通常とは異なり3つ以上の検定仮説が並立する本検定方式では,最大の尤度と次点の尤度に対するものを採用する(この出題打切りの条件については,3.で改めて論ずる).
テスト項目に付与する正答率は,先行研究のテスト構成支援システム(1)-(2)にあるように,過去の実測値を用いることもでき,そのような解釈も可能であるが,本論文においては,学習水準の基準値と解釈する.例えば語彙能力では,「カテゴリーAの語彙については90%,カテゴリーBの語彙については70%,カテゴリーCの語彙については50%を知っているとき,レベル3の語彙能力と呼ぶ」とすれば,それぞれのカテゴリーに属する語彙の正答率は上記の基準値をそのまま採用する.これは,小学校などにおける学年別配当表に相当すると考えることができる.
出題に際しては,出題打切りの条件に速やかに達するように,最適なテスト項目を選択する.テスト項目の最適選択に関しては,4.で改めて論ずるが,直感的には,その時点において,最大尤度を持つ学習水準にとっては有利(次の回答の結果,尤度が上がる可能性が高い)であり,次点の尤度を持つ学習水準にとっては不利(尤度が下がる可能性が高い)となるような正答率のテスト項目を選択すればよい.この選択は,評価関数によって,統計的に行う.
この節では,本検定方式と形式上の類似性を持つ項目反応理論(8)-(11)の概要を述べ,いくつかの対応関係と相違を指摘する.
項目反応理論は,被験者が一つの潜在特性(その値をθと記す)を具備し,これを測定するテスト項目(結果が正誤で判定される測定項目)に対する正答率が,そのテスト項目を特徴づけるパラメータとθとの関数であることを仮定する.2パラメータ・ロジスティックモデルの場合では,パラメータとして識別力(discrimination)aと困難度(difficulty)bを,正答率として
| P(θ) | = | 1 | (1) |
| 1+exp(−Da(θ−b)) |
を仮定する(但し,Dは定数1.7).そして,テスト項目に対する被験者の反応から,θ,a,bを推定する.このとき,項目情報量I(θ)は,Q(θ)=1−P(θ)とすれば,
| I(θ) | = | P´(θ)2 | |
| P(θ)Q(θ) | |||
| = | D2a2P(θ)Q(θ) | (2) |
と定義され,その項目に対する反応を知ることから得られる情報の大きさを表している.以下,θLは最尤推定値を表すとすれば,あるテストに含まれる全項目のI(θL)の総和は,推定値θLの分散の逆数を与える.このI(θL)を最大とする項目を選んで出題を繰り返す適応形テストが報告されている(6)-(11).
前節で述べたように,本論文でいう正答率は,学習水準別に定めるので,学習水準はθに,学習水準別正答率はP(θ)に対応するが,両者の関数関係は必ずしも上記のモデルに当てはまるとは限らない.仮に,学習水準別正答率をこのモデルの関数(1)で近似するとすれば,正答率が15, 50, 85%となる学習水準が,各々b−a,b,b+aに相当する.
項目反応理論では,正答率P(θ)を潜在特性がθである被験者の母集団における正答者の比率と解釈している(9)が,本論文では,前節で述べたように,被験者がその学習水準にあると認定すべき基準と解釈している.これは,大規模な事前調査をせずに,テスト項目に正答率を付与することに対する一つの根拠を与えるものである.(付録2参照.)
この章では,本検定方式の基礎となる逐次検定(sequential testing)の概要と,これを多重並立仮説の場合に拡張する問題について論じ,シミュレーションによって,これを確認する.以下では,適応型逐次検定と区別するために,この検定をランダム逐次検定と呼ぶことがある.適応型逐次検定については,4.で論ずる.(付録3参照.)
検定仮説H0と対立仮説H1に対し,第一種の過誤をα0,第二種の過誤をβ01とし,c01とc10を,
| c01 | = | β01/(1−α0) | (3) |
| c10 | = | α0/(1−β01) |
| c01 < λ1/λ0 < c10-1 | (4) |
にある限り,判定を保留し,サンプリングを続ける.上記の範囲を越えたときに検定は終了するが,当然そのときの標本数は一定ではない.検定に要する標本数は,同じα0,β01の固定標本方式に比べ,多いことも少ないこともあるが,その平均は概して少なめであり,半数程度になることもある.
(3)式に示したc01,c10とα0,β01の関係式は,2つの仮説H0,H1が正しく判定される確率1−α0 ,1−β01を(4)式を使って劣評価することにより得られる.
逐次検定では,H0とH1が対称的に現れていることに留意されたい.
本論文で扱う検定問題では,検定すべき仮説は学習水準の数だけ(日本語語彙能力の場合,5つ)並立する.従って,逐次検定方式をそのままの形で適用することはできないが,H0とH1が対称的に記述されていることから,検定仮説をHi,Hiに対する第一種の過誤をαi,Hjからの第二種の過誤をβij,尤度をλi,そしてHiに対するHjの棄却基準をcij=βij/(1−αi),とすれば(付録1参照),
iと異なるすべてjに対し,
| λj/λi≦cij | (5) |
となったとき,Hiを採択する,
という検定法を考えることができる.上式は,二仮説の逐次検定の場合とほぼ並行した議論で導出できる.
全検定仮説を同等に扱う場合であれば,αi=αとし,これによりβij=β=α/(検定仮説数−1),とすればよい.本論文の場合,検定対象が学習水準であり,明白な順序関係がある.従って,ある仮説に対立するのはその前後の学習水準に付随する2つの仮説であることから,実質的には,鼎立逐次検定となる.(最下位レベルと最上位レベルの場合は,二仮説並立となるが,便宜上同じに扱う.これにより,この場合の過誤の大きさを過大に評価することになる.)以下,本論文では,β=α/2とする.
前節で述べた多重並立逐次検定方式が成立することを確認するために,シミュレーションを行った.
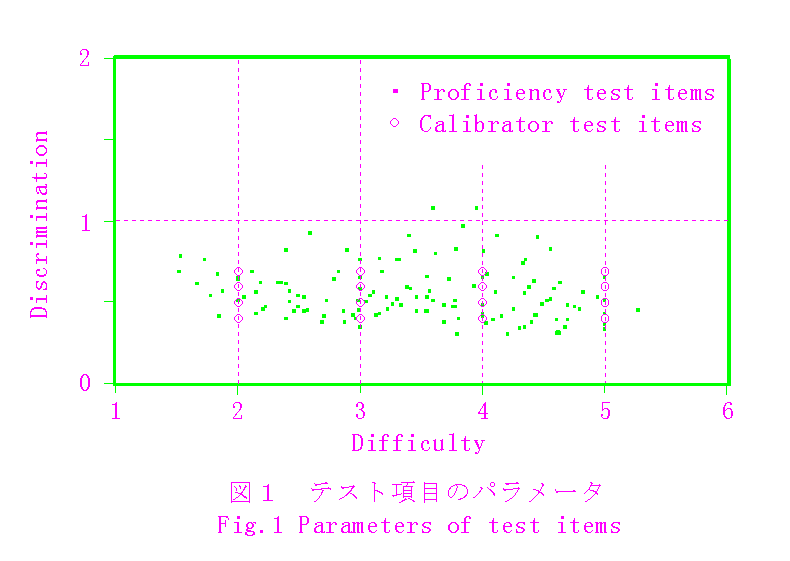
シミュレーションにあたり,現実的であり,しかも整理しやすい条件を設定するために,1991年度の能力テストで実際に使われた問題のうち,項目分析によって比較的良い判定を受けた201のテスト項目(以下,実課題と呼ぶ)を参考に,基準課題(calibrator)を作成した.実課題を2.2で述べた識別力と困難度で評価した結果を図1に示す(付録2参照).識別力は0.4〜0.9程度,困難度は1.6〜5.0程度に及んでいる.一方,基準課題は,図1に併せて示したように,識別力0.4〜0.7,困難度2〜5の16種のテスト項目を各々10項目づつ,計160項目含んでいる.テスト項目は,すべて四肢択一形式である.
シミュレーションは,学習水準がレベル1〜レベル5の受検者に対し1000回の受検を想定し,それを更に1回〜15回行っている.以下,別段の記載がないときは,テスト項目として上記の基準課題を用い,α=10%としたときのものである.
また,理論的には,逐次検定が終了しない確率は零であるが,本検定システムでは,プールしたテスト項目は有限であり,既出のテスト項目が再度出題されることがないため,テスト項目を使いきった時点で,判定未了のまま検定を終了することがあり得る.(付録3参照.)
| レベル1 | レベル2 | レベル3 | レベル4 | レベル5 | ||
| 固定標本方式 | ||||||
| 所要出題数(比) | 60 (1.00) | 84 (1.00) | 64 (1.00) | 67 (1.00) | 41 (1.00) | |
| ランダム逐次検定 | ||||||
| 判定未了率 平均出題数(比) 90%ライン (比) 第一種の過誤 |
1.4% 52.0±1.9 (0.86) 96 (1.60) 2.7% |
1.8% 66.7±1.5 (0.79) 101 (1.20) 7.4% |
0.4% 55.3±1.3 (0.86) 87 (1.36) 5.1% |
0.6% 54.5±1.3 (0.81) 83 (1.24) 8.1% |
0.7% 37.8±1.5 (0.92) 72 (1.76) 3.1% |
|
| 適応型逐次検定 | ||||||
| 判定未了率 平均出題数(比) 90%ライン (比) 第一種の過誤 |
2.6% 27.1±1.3 (0.45) 54 (0.90) 2.5% |
1.3% 39.2±1.3 (0.47) 64 (0.76) 7.3% |
0.5% 36.9±1.1 (0.58) 57 (0.89) 7.1% |
0.4% 35.9±1.0 (0.54) 57 (0.85) 8.3% |
0.1% 23.6±1.0 (0.58) 43 (1.05) 2.4% |
|
| 注) | ・固定標本方式欄の所要出題数は,第一種の過誤を10%にするために必要な出題数. |
| ・出題数平均欄の誤差は,95%信頼区間の大きさ. | |
| ・90%ラインは,シミュレーションした検定の90%が終了するのに要した出題数. | |
| ・出題数平均欄と90%ライン欄の括弧内は,固定標本方式に対する比率. | |
| ・第一種の過誤は,判定完了数に対する実測値. |
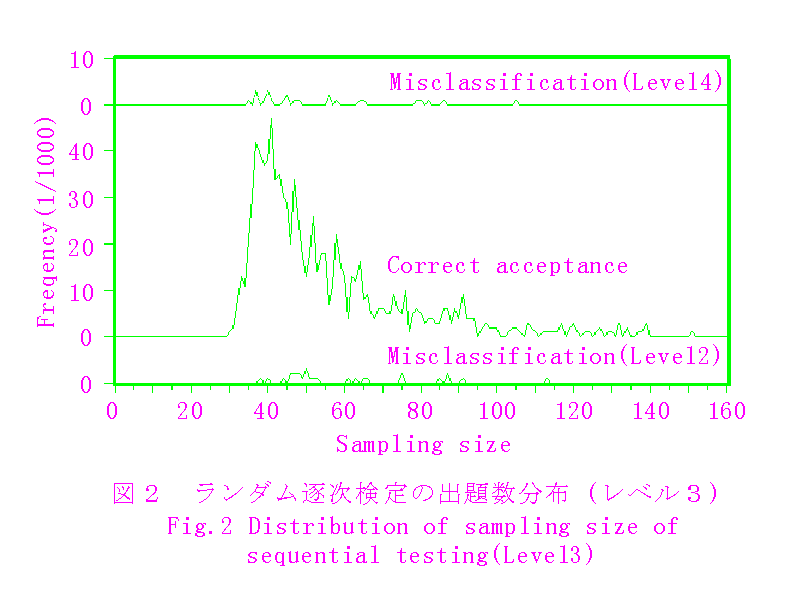
シミュレーションに使った基準課題に含まれるテスト項目の平均正答率は,レベル1から順に,13,25,41,59,75%で,その差は12〜18ポイントと比較的小さいため,固定標本方式に対する出題数の減少率は,概ね10〜20%に留まっている.上記平均正答率をもとに,二項分布を仮定したときの理論平均標本数と比べると,概ね10〜15大きくなっているが,この数字は,図2の出題数分布の長い裾に見られるように,正答率の差が平均より小さい場合標本数が極端に大きくなることを考えると,妥当な結果と思われる.(付録3参照.)なお,固定標本方式の所要出題数は,基準課題の16種のテスト項目について均等に削減して,シミュレーションを行い,過誤の大きさを測定,これを補間して求めたものである.
第一種の過誤の大きさは,鼎立仮説となるレベル2〜レベル4について,5〜8%となっていて,指定したαの数値より小さめになっている.これは,多くのシミュレーションを観察すると,検定の後半に対立している仮説は一つの場合がほとんどであることから,理論上過誤を過大に評価する結果となっているためである.
3.3に述べたように,本検定システムのテスト項目は,すべて択一式としている.この場合,どのテスト理論でも問題となるのが,当て推量のモデル化(例えば,項目反応理論の偶然正答水準(9))である.
> 本論文の逐次検定方式は,特定のモデルには依らないので,当て推量のケースを直接取り扱うことはできないが,この場合についてシミュレーションした結果を表2に示す.本節冒頭に述べたように,テスト項目は,四肢択一であるから,偶発による正答率は25%あり,これはレベル2の平均正答率に一致する.従って,レベル2と判定される場合が最も多く79%に達する.当て推量の受検者をレベル2以下と判定する割合は91%であり,本検定方式の前提を考慮すれば,実用的な検定システムとして妥当であると言える.
| レベル1 | レベル2 | レベル3 | レベル4 | レベル5 | 判定未了 | ||
| ランダム逐次検定 | 実数 | 118 | 784 | 87 | 0 | 0 | 11 |
| 割合 | 12% | 79% | 8% | 0% | 0% | − | |
| 適応型逐次検定 | 実数 | 546 | 388 | 55 | 10 | 0 | 1 |
| 割合 | 55% | 39% | 6% | 1% | 0% | − | |
また,上の議論から,より易しいテスト項目を追加すれば,この判定結果を向上させ得ることが分かる(但し,4.に述べる適応型逐次検定方式でないと,他の場合の出題数が増加することになる).
2.1に述べたように,プールするテスト項目には,あらかじめ正答率を設定しておかなければならないが,2.2のレベル認定基準としての解釈にも拘わらず,これは言う程にたやすいことではない.もし設定した正答率の僅かな違いが,平均出題数などを大きく変動させるとすれば,本研究の前提とした実用性を失うことになる.
これらの正答率に対する感受性を見るため,検定の過程で利用する正答率(%表示)に,±1,±3,±5ポイントの擾乱を与えてシミュレーションを行った.結果は,平均出題数および第一種の過誤の実測値共に,増加減少などの傾向は見出せなかった.
この結果から,テスト項目に設定する正答率は5%単位で十分であり,平均出題数および第一種の過誤は,これに対して,実用上十分な安定性を持つと結論できる.
本論文で述べるシミュレーションは,使用した開発言語に用意された乱数発生機構によるものであるが,本検定方式の場合,発生させた乱数に,大きな数字が続くなどの性質があると,有意な結論は得られない.
この点を確認するために行った乱数の検定結果を表3に示す.χ2の値は,概ね良好であり,乱数に関して,シミュレーションは妥当であると言える.
| χ2 | 棄却域(25%) | |
| 乱数の発生頻度 | 103 | 108 |
| 20区間に分けたときの発生頻度 | 21.2 | 22.7 |
| 10区間に分けたときの発生頻度 | 6.37 | 11.39 |
| 上昇・下降の連の発生頻度 | 3.17 | 5.39 |
| 注) | 0〜99の整数を,10,000回発生させたときの統計値. |
また,各シミュレーションは1000回の検定を含んでいるが,それから得られる統計値の安定性を見るために,多くの場合,複数回のシミュレーションを行っている.これによって,平均出題数など本論文で必要とする統計値は,理論上の誤差範囲の中で,十分に安定していることが確かめられている.
この章では,ランダム逐次検定の手続きの中,出題するテスト項目の選択方法を最適化する方法について論じ,シミュレーションにより,その効果を測定する.
この最適化により,出題されるテスト項目は受検者に適合したものとなるため,この検定方式を適応型逐次検定と呼ぶ.
なお,テスト項目の選択を恣意的に行っても,そのテスト項目に対する回答行動自体は独立に行われるので,逐次検定の枠組みを損なうことはない.(既出のテスト項目による学習効果については,ランダム逐次検定の議論の際も触れていないのだが,3.3で述べた実課題を見る限り,あるテスト項目が他の項目のヒントになるケースは少ないと思われる.いずれにしても,これはテスト問題の作成に関する普遍的な問題の一つである.)
最大および次点の尤度を持つ学習水準をm,n,それぞれの尤度をλm,λn,次に回答すべきテスト項目に対する正答率をpm,pn,誤答率をqm=1−pm,qn=1−pnとする.本検定で必要とするのは尤度比であるから,λm=1に正規化し,同じ記号で表すことにする.以下,これを相対尤度と呼ぶ.
検定の過程の各時点において,受検者が学習水準iである確率は相対尤度λiに比例すると仮定すると,回答後の相対尤度の期待値の増分は,次のように計算される(付録4参照).
| ⊿λn | = | λn2 | (pm−pn)2 | (6) | |
| 1+λn | pmqm |
| ⊿λnが最大となるテスト項目を選択する | (7) |
という方策を考えることができる(最小化ではない).
なお,本論文で採用した評価関数(6)は,係数部分を除いて,離散量である学習水準を連続量に延長し,分子にある項を微分係数に置き換えると,(2)式に形式的に一致する.
実際に(6)式を適用するときは,テスト項目に依存しない係数部分を取り除いて評価する.
また,検定の始めのうちは,最大の尤度を持つ学習水準が大きく振れ,所要出題数の分散を大きくする可能性がある.これを防ぐための最適選択の保留については,次節で検討する.
本検定方式を実用に供するには,更に次の点に関する検討が必要である.
3.3の実課題で検定すると,10問足らずで検定を終了するケースがあり,形成的機能を考慮すると,出題数の下限を設ける必要がある.
また,最適なテスト項目を選択して出題するので,繰り返し受検できることが本研究の前提であるにも拘わらず,検定の後半では,同じ学習水準の受検者に対して,同一のテスト項目が出題される傾向にある.従って,最適選択の条件を状況に応じて緩和する必要がある(11).
最適選択の効果を確認し,前節で述べたいくつかの問題を調査するため,3.3と同様の条件でシミュレーションを行った.なお,このシミュレーションでは,4.2.3で述べる最適選択の保留回数は4にしている.
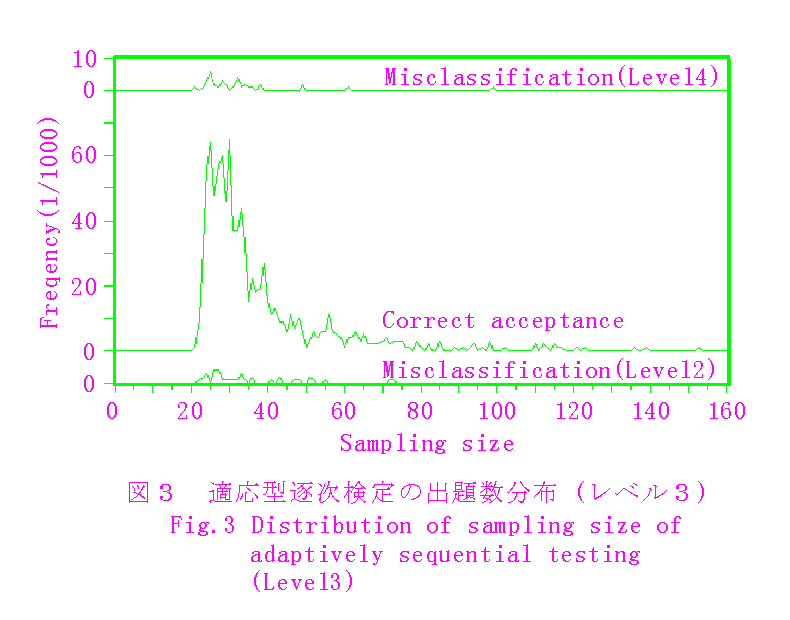
平均出題数は,固定標本方式に比べ,概ね半分になっている.減少率約5割は,受検者の負担軽減を実現するものである.
第一種の過誤の実測値も,理論的予測の範囲に収まり,理論の有効性を裏付けている.
当て推量で回答した場合の検定について,シミュレーションした結果を,表2(既出)に示す.
3.3.2の議論から予測できるように,ランダム逐次検定と比べて,レベル1と判定する割合が大幅に増え,レベル2の割合を越えている.当て推量の受検者に適応して,低いレベルのテスト項目が多く出題された結果である.
実用に際しては,基準課題に比べて,レベル1のテスト項目を増やすことで,当て推量の受検者に対応することが可能であるといえる.
検定の始めのうちは,相対尤度の順位は回答毎に大きく変動する.これが出題数などにどのような影響を与えるかを見るために,検定開始後数回はランダムにテスト項目を選択するようにして,8ケース(保留回数0〜7)についてのシミュレーションを行った.
判定未了率,第一種の過誤について,最適選択保留回数が7までの範囲で,増減等の傾向は認められない.
一方,予測通り,出題数の平均は漸増(保留回数に対する係数,0.2〜0.4),標準偏差は漸減(同,-0.1〜-0.3)傾向が認められる.標準偏差については,表1の誤差範囲から知れるように,適応型逐次検定の方が小さく出るので,この傾向はいつか漸増に転ずることになる.基準課題より識別力のあるテスト項目(識別力0.5,0.8,1.0,困難度1〜5,の15種150題)でシミュレーションした結果では,最適選択の保留回数が4〜5のとき,分散は最も小さくなり,出題数が安定する.なお,このときの平均出題数は,14〜22題である.
本検定システムでは,形成的機能の強化のために,出題数の下限を設定できるようになっている.10題以下といった,僅かなテスト項目で検定が終了しないようにするためである.日本語語彙能力の場合,20題程度の下限を設定する.
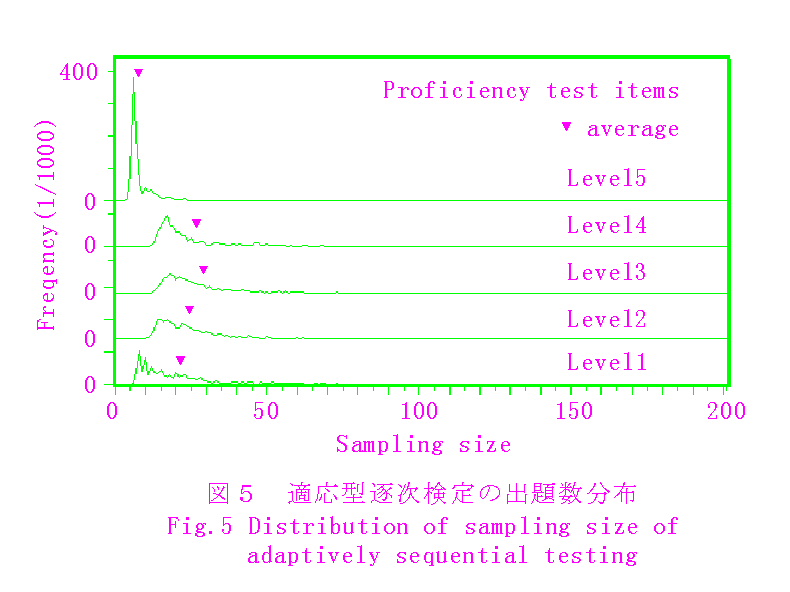
これによって,出題数は当然増加し,第一種の過誤は減少することが予想される.シミュレーションによれば,第一種の過誤の大きさは,下限を0から40に変化させることにより,表1の数値の概ね半分に減少する.しかし,図2および図3に示した出題数の分布から明かなように,前記の下限20程度では殆ど影響はない.一方,3.3の実課題の場合は,図5に示すように,出題数の分布は10前後から始まっているので,平均出題数を押し上げることになり,負担軽減と教育的配慮から下限を定めることになる.
反復受検および形成的効果の点から,出題を最適化することによるテスト項目の固定化という副作用は好ましい現象ではない.
2.1の議論から,同じカテゴリーに属するテスト項目は同一の正答率を持つことになるので,(6)式の評価関数の値も一致する.従って,各カテゴリーが十分なテスト項目を含んでいれば,出題の多様性は確保できるが,反面,作問の負担が増えることになる.
そこで,本検定システムでは,最適選択を緩和することで,出題されるテスト項目に幅をもたせるようにしている.緩和は,テスト項目の選択の際に,評価関数の値に(1+緩和率)を掛けることによって行う.緩和率が十分に大きければ,ランダム逐次検定と変わらないことになるから,この取扱いによって,出題数は増加し,分散も大きくなると予想される.
この最適選択の緩和の影響を見るために,緩和率を0〜5として,シミュレーションを行った.
平均出題数は,緩和率に対する係数が約3,標準偏差は,同約1で増加する.一方,第一種の過誤や判定未了率には,増減等の傾向は認めらず,理論的予測と一致する.
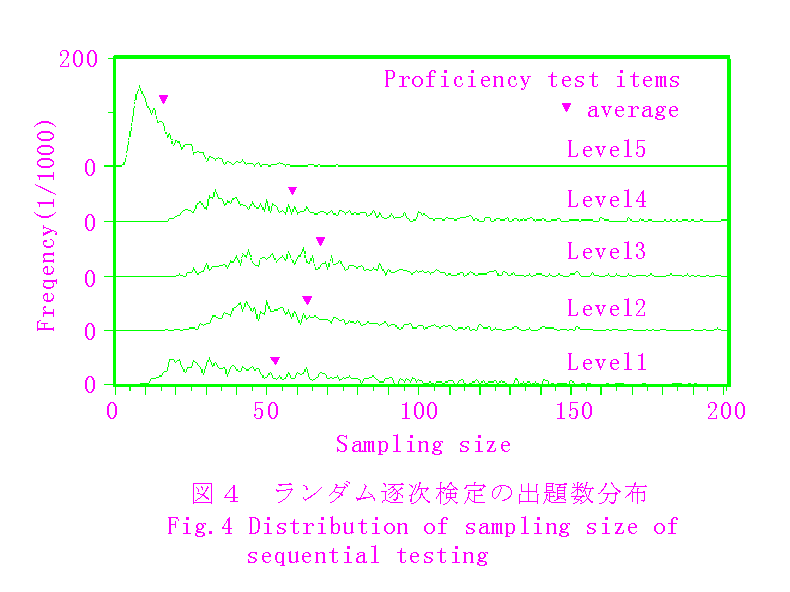
最後に,3.3の実課題によるシミュレーション結果を図4および図5に示す.実課題には,基準課題に比べて,識別力のあるテスト項目が多く含まれている(図1)ので,最適選択の効果は大きい.ランダム逐次検定の場合を1として,適応型逐次検定の平均出題数は,0.41〜0.52に削減されている.
本論文では,受検負荷が少なく,実用的な検定方式として,適応型逐次検定を提案し,シミュレーションにより,理論の裏付けを行った.また,実用上の問題点について考察,対応策を示し,シミュレーションにより,これを評価した.
これらにより,本検定方式は,1.に述べた問題点に対する一つの解答として,十分実用に耐え得るものと考える.
今後,研究分担者によるテスト項目の作成(総計500項目程度)を待って,留学生を被験者とする実験を行い,作問から後処理までを含めた実用性を検討する予定である.
謝辞 本研究のきっかけを与えて戴いた東京工業大学教育工学開発センター赤堀侃司氏に感謝致します.
| (1) | 菊川健,吉沢将仁,川淵里美,竹本宣弘,佐藤隆博,竹谷誠,森本泰弘:“ITEM BANKING SYSTEMの開発 Ⅰ”,信学技報,ET76-6(1976). | |
| (2) | 永岡慶三:“マイクロ・アイテム・バンクの開発(1)−ソフトウェア構成−”,信学技報,ET84-2(1984). | |
| (3) | 芝祐順,野口裕之,南風原朝和:“語彙理解力測定のための多層適応形テスト”,教育心理学研究,26,4,pp.11-20(1978). | |
| (4) | 芝祐順,野口裕之,大浜幾久子:“多層適応形テストによる語彙理解力予備測定の効果”,東京大学教育学部紀要,19,pp.27-34(1979). | |
| (5) | 芝祐順,大浜幾久子,野口裕之:“在外日本人児童の日本語語彙理解力に関する調査”,東京大学教育学部紀要,20,pp.111-128(1980). | |
| (6) | 野口裕之,芝祐順,丹直利:“語彙理解力尺度の研究Ⅱ−項目固定版と適応形テストによる測定−”,東京学芸大学紀要1部門,34,pp.101-114(1983). | |
| (7) | 柴山直,野口裕之,芝祐順,鎌原雅彦:“最適化テスト方式による語彙理解力の測定”,教育心理学研究,25,4,pp.363-367(1987). | |
| (8) | 永岡慶三,植野真臣:“大学における情報教育環境としての適応型テストシステム”,信学技報,ET88-7(1988-12). | |
| (9) | 芝祐順編:“項目反応理論”,東京大学出版会(1991-9). | |
| (10) | Weiss D.J.(ed.):“New horizons in testing : latent trait test theory and computerized adaptive testing”,Academic Press,New York(1983). | |
| (11) | Wainer H.(ed.):“Computerized adaptivetesting : a primer”,Erlbaum,Hillsdale,N.J.(1990). |
1.逐次検定に関する用語・記号の説明
本文中の用語・記号は,通用の意味で用い,また本文にも定義してあるが,念のために,説明を加える.
第一種の過誤(α)は,一般に,検定仮説が真であるにも拘わらずこれを棄却してしまう確率であり,第二種の過誤(β)は,対立仮説が真であるときに検定仮説を採択してしまう確率である.本文3.2の場合も同様であるが,第二種の過誤は対立仮説に対して定まるものであるから,記号βij(Hj が真であるときにHi を採択してしまう確率)を用いることとする.
尤度(λ)は,ある一連の測定について,それが観察される確率のことである.本文3.2の場合も同様であり,λiは検定仮説Hiが真のときにその観察が生起する確率である.
2.項目反応理論との相違
本文2.で指摘していることだが,本検定方式は項目反応理論には基づいていないことを強調しておく.項目反応理論は被験者の能力を測定するが,本検定は所与の基準に従って分類する.本文3.3で,項目反応理論の用語である困難度などを用いているのは,テスト項目を分類整理するためであり,成長曲線が諸処に登場するのと同程度の意味しかない.本論文で項目反応理論に言及しているのは,本文1.および2.で述べているように,受検者の負担を軽減する方策を提供する点で一致しているからである.従って,両者の結果を数値的に比較するのは理論上無意味である.この点で比較可能なのは出題数等の負担軽減率,あるいは適用上の有効性についてだけである.実は,負担軽減率についても,項目反応理論に基づく適応形テスト(7) は,第二種の過誤について制御しない条件で判定しており,本検定方式は両過誤の大きさを制御している.この場合,周知のように統計理論上数値の直接比較は意味がない.すなわち,それぞれの条件下で固定標本方式と比較するか,本文1.に述べてあるように,専ら適用レベルでの比較となる.これは,本論文の範囲を越え,別に報告されるべきテーマとなる.これについては文献(10)に報告があり,その一部は本文1.に引用してある.
3.逐次検定の標本数
本文3.3.1で触れているように,レベル間の正答率の差が小さいとき,また中間の正答率を持つ受検者に対して出題が多くなる傾向がある.しかし,本文3.3で指摘していることだが,周知のように,検定が終了しない確率は零である.中間の正答率に対しては相対尤度がふらついて判定が終了しなくなるのではなく,長引いても判定は終了するが,判定そのものがふらつくのである.例えば,レベル3と4の中間の正答率で回答すると,時により,レベル3ともレベル4とも判定されるのである.これは,付録2で述べた分類という観点から,首肯できる結果である.
4.本文(6)式の導出
受検者が学習水準iである確率が相対尤度λiに比例する(本文4.1の仮定)とすれば,次点の尤度の期待値は,次のように容易に計算される.(記号の意味は本文参照.)
出題された次のテスト項目に正答または誤答する確率は,仮定から,
| 正答する確率 | = | pm | 1 | + | pn | λn | |
| 1+λn | 1+λn | ||||||
| 誤答する確率 | = | qm | 1 | + | qn | λn | |
| 1+λn | 1+λn |
| 次点の相対尤度の期待値 | = | pnλn | (pm | 1 | + | pn | λn | ) | + | qnλn | ( | qm | 1 | + | qn | λn | ) | |
| pm | 1+λn | 1+λn | qm | 1+λn | 1+λn | |||||||||||||
| = | λn+ | λn2 | ( | pn2qm+pmqn2−pmqm | ) | |||||||||||||
| 1+λn | ||||||||||||||||||
と計算され,()内を変形して(6)式を得る.