Excellent XPath Expressions
nanto_vi (TOYAMA Nao), 2010-06-05, 2010-09-26 追補
XPath で何ができるか
- 文書中のノードの選択
- 文書: XML 文書、HTML 文書
- ノード: 文書ノード (ルートノード)、要素ノード、属性ノード、テキストノード、コメントノード、etc.
- cf. CSS セレクタ: 要素の選択
- 文書を元にした文字列、数値、真偽値の生成
図 1 に HTML 文書が生成する文書木 (文書ツリー) の例を挙げます。図中、二重線で囲んだのが文書ノード、角丸四角が要素ノード、長方形がテキストノードを表します。
文書木の根 (最上部) は文書要素ノード (ルート要素ノード、HTML 文書なら html 要素ノード) ではなく、文書ノードであることに注意してください。JavaScript から DOM や XPath を扱う場合、document オブジェクトが文書ノードに対応します。
属性ノードは特定の要素ノードに属しますが、文書木中には含まれないと考えたほうがいいでしょう。
CSS セレクタと XPath の最大の違いは、CSS セレクタでは要素及び擬似要素にしかアクセスできないのに対し、XPath では要素以外にもテキストや属性にアクセスできるという点にあります。
XPath の「ノード」は厳密には DOM の「ノード」と異なりますが、ほとんどの場合同一視して問題ありません。DOM に存在して XPath に存在しないものとして、文書型宣言を現す DocumentType ノードがあります (DOM では文書ノードの子ノードとして出現する)。
XPath で何ができないか
- 文書の操作
- 文書木に現れない条件による選択
- フォームコントロールの入力値
- リンクが未訪か既訪か
- フォーカスしているか
- カーソルが要素上にあるか
XPath の仕様
- XML Path Language (XPath) Version 1.0
- XML Path Language (XPath) 2.0
- Document Object Model (DOM) Level 3 XPath Specification Version 1.0
- HTML5
以下で単に XPath といった場合、XPath 1.0 を指す
XPath は本来 XML 文書のために策定されたものですが、IE を除く各ブラウザは HTML 文書にも適用可能にしました。
HTML 文書における XPath の扱いは、名前空間や局所名といった細かな点がブラウザ間で異なりましたが、今後は HTML5 が定める形に統一されていくでしょう。
XPath の利用に必要なもの
- 式
- コンテキスト
- コンテキストノード
- コンテキストサイズ、コンテキスト位置
- XML 名前空間の接頭辞と名前空間 URI の組み合わせ
XPath というと XPath 式のみが注目を集めがちですが、その実行過程を理解する上ではコンテキスト、特にコンテキストノードが重要になってきます。
XPath で重要な概念に文書順というものがあります。これは文書中の各ノードを文書内で最初に出現する順番で並べた順序で、ノード同士の前後関係を表すのに用いられます。文書順は、文書木の先行順 (preorder) での順序付けと一致します。
文書順の前後をひっくり返した文書順の逆順 (逆文書順) が使われることもあります。
XPathのデータ型
ロケーションステップ
- 軸、ノードテスト、述語 (複数) の組み合わせ
- コンテキストノードを元にノードセットを選択する
- e.g.
child::p[1] (コンテキストノードの子である p 要素のうち、最初に出現するもの)
- 1 ノードからなるノードセット
- そのような p 要素がなければ、空のノードセット
ロケーションステップとはいわば、ひとつのノードを引数に取りノードセットを返す関数です。ここで引数として渡されるノードがコンテキストノードです。
軸
- コンテキストノードから見た、ノードを探す方向
child
body 要素がコンテキストノード (図中で星のついたノード) であるとき、child 軸によって選択されるノードはその子である div 要素と p 要素 (図中で網掛けされたノード) になります。
descendant
descendant-or-self
parent
ancestor
ancestor-or-self
following-sibling
preceding-sibling
following
- 文書順でコンテキストノードより後に出現するノード、ただしコンテキストノードの子孫ノードを除く
preceding
- 文書順でコンテキストノードより前に出現するノード、ただしコンテキストノードの祖先ノードを除く
self
attribute
- 【図】
- 順方向軸
child, descendant, descendant-or-self, following-sibling, following, self
- 逆方向軸
parent, ancestor, ancestor-or-self, preceding-sibling, preceding
軸は順方向軸と逆方向軸の 2 つに分けられます。文書順でコンテキストノード以降のノードを探索するのが順方向軸、コンテキストノード以前のものを探索するのが逆方向軸です。self 軸にとってこの区別はあまり意味がありませんが、便宜上順方向軸に含めます。
コンテキストノードをひとつ定めたとき、文書木中の全ノードは ancestor、descendant、preceding、following、self 軸のいずれかひとつにより選択されます。あるノードがこれらのうち 2 つ以上の軸に同時に属するということはありません。
XPath と CSS セレクタの最大の違いは、XPath には順方向軸がある (文書順が若いノードを選択できる) ということです。CSS セレクタでは「ある要素の親要素」を選択することができませんが、XPath なら可能です。
ノードテスト
- 生成するノードセットに含めるノードの検査
child::p
child::*
child::node()
child::* は要素ノードのみを選択しますが、child::node() はテキストノードやコメントノードも (あれば) 選択します。
child::text()
child::comment()
ancestor::*
ancestor::node()
ancestor::* は要素ノードのみを選択しますが、ancestor::node() は文書ノードも選択します。
self::p
- コンテキストノードが p 要素なら 1 ノードからなるノードセット
- そうでなければ空のノードセット
self::*
self::node()
self::node() は常に 1 ノードのみを含むノードセットを返しますが、self::* は空のノードセットを返すことがあります (コンテキストノードが要素ノードでなかった場合)。
attribute::class
attribute::*
attribute::node()
attribute::* と attribute::node() はどちらも同一のノードセットを返します。
ノードテストは末尾に丸括弧 () がつくことがありますが、これは関数呼び出しではありません。名前テストとそれ以外のテストを区別するためのものです。(child::text だと text という名前の子要素を選択することになってしまう。)
述語
- ノードセットの絞り込み (選別)
[ 式 ]- ノードセット中の個々のノードをコンテキストノードとして式を評価
- 式の評価結果が数値なら、その値をコンテキスト位置と比較
- そうでなければ、その値を真偽値に変換
- コンテキストサイズ
- コンテキスト位置
- ノードセットに含まれるノード中での、コンテキストノードの順番
- 1 ベース
- 順方向軸、軸なしなら文書順での順番
- 逆方向軸なら文書順の逆順での順番
child::*[1]
- コンテキストノードの子要素の中で、最初に出現するもの
図 15 で body 要素をコンテキストノードとしたとき、child::* により選択されたノードセット中の各ノードのコンテキスト位置を菱形数字で示しました。
child::*[last()]
- コンテキストノードの子要素の中で、最後に出現するもの
last 関数はコンテキストサイズを返す
preceding-sibling::*[1]
- コンテキストノードの兄要素の中で、最後に出現するもの
逆方向軸により選択されるノードセット中のノードは、文書順の逆順でコンテキスト位置が振られます。
child::*[position() = 1]
child::*[1] に同じposition 関数はコンテキスト位置を返す- 等値演算子は
=
ancestor::*[position() != last()]
- 文書要素 (ルート要素) を除く、コンテキストノードの祖先ノード
child::*[child::p]
- コンテキストノードの子要素の中で、さらにその子に p 要素を持つもの
- ノードセットは空でなければ真、空ならば偽に変換される
child::* により得られたノードセット中の各ノードをコンテキストノードとして child::p を評価します。評価結果が空でないノードセットなら、コンテキストノードとしたノードが最終的な結果ノードセットに含まれます。
child::*[0]
- 空のノードセット
- コンテキスト位置は必ず 1 以上
child::*[""]
child::*["0"]
- コンテキストノードの子要素
- 空でない文字列は真に変換される
child::*[child::p][1]
- コンテキストノードの子要素の中で、さらにその子に p 要素を持つもののうち、最初に出現するもの
child::*[child::p] で得られるノードセットは図 18 を参照してください。そのノードセット中のノードで、コンテキスト位置が 1 であるものが選択されます。
child::*[1][child::p]
- コンテキストノードの子要素の中で最初に出現し、かつその子に p 要素を持つもの
child::*[1] で得られるノードセットは図 15 を参照してください。そのノードセット中のノードで、子に p 要素を持つものが選択されます。ここではそのようなノードは存在しないので、空のノードセットが返されます。
ロケーションパス
- スラッシュ
/ 区切りのロケーションステップの連続
- 直前のロケーションステップで得られたノードセット中の、各ノードをコンテキストノードとして次のロケーションステップを評価
child::p/child::em
- コンテキストノードの子要素である p 要素の子である em 要素
- 相対ロケーションパス
- 【図】
相対ロケーションパス ls1 / ls2 (ls1, ls2 はロケーションステップ) をコンテキストノード n0 と共に評価する過程は次のようになります。
- n0 をコンテキストノードとして ls1 を評価し、得られたノードセットを S0、そのノード数を k と置く。
- S0 中のノード n1, ..., nk をそれぞれコンテキストノードとして ls2 を評価し、得られたノードセットを S1, ..., Sk と置く。
- S1, ..., Sk をマージしたノードセットを S と置く。S が、n0 をコンテキストノードとしてロケーションパス
ls1 / ls2 を評価した結果の値である。
最終的にノードセットの集合を返すのではなく、複数のノードセットをマージしている (集合和を取っている。ノードセットは重複を含まない集合) ことに注意してください。ロケーションステップの返り値は常にひとつのノードセットです (もちろんその中のノード数は 0 であったり複数であったりします)。
/child::p/child::em
- 文書ノードの子要素(文書要素)である p 要素の子である em 要素
- 絶対ロケーションパス
絶対ロケーションパス / ls (ls はロケーションステップ) をコンテキストノード n と共に評価する過程は次のようになります。
- 文書ノードをコンテキストノードとして ls を評価し、得られたノードセットをロケーションパス
/ ls の評価結果値とする。
絶対ロケーションパスの評価に所与のコンテキストノードは用いられません。
なお、HTML 文書のルート要素は常に html 要素であり、p 要素ではないので、HTML 文書において式 /child::p/child::em の評価結果は常に空のノードセットとなります。
省略構文
attribute::class@class- コンテキストノードの class 属性
child::p/child::emp/em- コンテキストノードの子である p 要素の子である em 要素
child::p/descendant-or-self::node()/child::emp//em- コンテキストノードの子である p 要素の子孫である em 要素
/descendant-or-self::node()/child::p//p- 文書中のすべての p 要素
self::node()/child::p./p- コンテキストノードの子である p 要素
parent::node()..- コンテキストノードの親ノード
型変換
- ノードセット → 文字列
- ノードセット中のノードのうち、文書順で最初のものが
- 文書ノードならその子孫テキストノードのテキストを連結したもの
- 要素ノードならその子孫テキストノードのテキストを連結したもの
- 属性ノードならその属性値
- テキストノードならそのテキスト
- コメントノードならその内容
- ノードセットが空なら空文字列
- ノードセット → 数値
- ノードセットを文字列化した後、それを数値として解釈したもの
- 解釈できなければ NaN
- ノードセット → 真偽値
文字列、数値、真偽値をノードセットに変換することはできません。
演算子
- 四則演算子
+ - * div mod- 比較演算子
= != < > <= >=- 論理演算子
and or- 集合和演算子
|
- 演算子の前後にはスペースを入れたほうがいい
foo-bar は child::foo - child:bar ではなく child::foo-bar と解析される
除算演算子がスラッシュ / でなく div なのは、スラッシュ / がロケーションステップの区切り文字に使われているからです。
XPath 式 div div div において、最初と最後の div はロケーションパス (コンテキストノードの子である div 要素を選択) ですが、真ん中の div は除算演算子と解釈されます。
=、!= 演算子の両辺がそれぞれノードセットと文字列であるときの動作はやや複雑です。ノードセット中の各ノードをそれぞれ文字列化して所与の文字列と比較し、条件に一致するものがひとつでもあれば真を返します。
図 21 の文書木で body 要素をコンテキストノードとしたとき、以下の各式は次のような結果になります。
child::p = "foo"- 真。最初の p 要素の文字列化した結果が "foo" だから。
child::p != "foo"- 真。2 番目の p 要素の文字列化した結果が "foo" でないから。
string(child::p) != "foo"- 偽。型変換の項を参照。
not(child::p = "foo")- 偽。
ノードセットと文字列との比較は、ノードセット中のノード数が 0 または 1 であるとわかっているとき (. = "foo"、@type != "hidden" など) のみにとどめたほうがいいでしょう。
関数
Functions - MDC (https://developer.mozilla.org/ja/XPath/Functions) を参照
文字列関数において、最初の文字の位置は 0 ではなく 1 なので注意してください。
translate() 関数は、文字列の置換ではなく文字の置換を行います。XPath 1.0 で文字列置換を任意回数行う手段は用意されていません。
XPath に真偽値リテラルはありませんが、true()、false() 関数が存在し、それぞれ常に真、偽を返します。
実例
wedata AutoPagerize SITEINFOs (http://wedata.net/databases/AutoPagerize/items)
例と注意点
id("first second")id 関数には空白区切りで複数の id を指定可能id(//label/@for) | //label//*[self::input or self::select or self::textarea]- 何らかのラベルに関連付けられたフォームコントロールを取得
id 関数の引数にノードセットを渡すと、各ノードの文字列値を元に要素を選択//ul | //ol//*[self::ul or self::ol]- 文書ノードを祖先に持つ ul または ol 要素
すなわち、文書中のすべての ul 要素及び ol 要素です。
concat('He said, "', "That's a good idea!", '"')- 文字列リテラルにエスケープシーケンスがないので、単一引用符と二重引用符を同時に含めるには
concat 関数を用いる
- He said, "That's a good idea!"
-
//a[text() = "foo"]//a[string(.) = "foo"]//a[. = "foo"]- 最初のものは
<a><em>foo</em></a> にマッチしない
. は常に 1 ノードのみからなるノードセットを返すので、//a[string(.) = "foo"] と //a[. = "foo"] は同じ結果になります。
- 基本的に
text() は使わないこと
- 多くの場合は
string(.) が「あなたが本当に望んでいたもの」
text() テストを使っている XPath 式の 8 割は不適切な使用法です。要素の内容文字列を扱いたいときは string() 関数を使いましょう。
//* (/descendant-or-self::node()/child::*) と /descendant::* は同じ結果を返しますが、その過程は異なります。コンテキスト位置、コンテキストサイズを参照する述語をつけると、その違いがより鮮明になります。
たとえば //div[1] としたとき、述語が属する軸は child 軸であり、コンテキスト位置は child 軸を基に算出されるので、コンテキスト位置が 1 であるノードが複数存在しえます (図 22)。しかし、/descendant::div[1] ではコンテキスト位置が descendant 軸を基に算出されるので、コンテキスト位置が 1 であるノードはひとつだけになります (図 23)。
「述語」の項で、コンテキスト位置は「軸なしなら文書順での順番」といいました。関数の返り値や、丸括弧でグループ化したときは軸なしになります。
たとえば、ancestor::*[1] は親要素を選択しますが、(ancestor::*)[1] はルート要素になります。
HTML の class 属性で指定されたクラス名を基に要素を選択するときのイディオムには次のようなものがあります。
//*[contains(concat(" ", normalize-space(@class), " "), " class-name ")]
normalize-space() 関数は、文字列の先頭末尾の空白文字 (タブ、改行、復帰、スペース) を取り除き、連続する空白文字を 1 文字のスペースに変換します。ただし、クラス名の区切り文字にスペース以外の空白文字が使われることはあまりないので、normalize-space() 関数を省くこともあります。
a、area、link 要素のうち rel 属性の値が "next" であるものを選択するときのイディオムには次のようなものがあります。
//*[translate(@rel, "NEXT", "next") = "next"]
HTML では rel 属性の値の大文字小文字を区別しません。translate() 関数は文字の置換を行うので、こうすると "N"、"E"、"X"、"T" がそれぞれ "n"、"e"、"x"、"t" に置換され、実際の属性値が "NEXT" でも "Next" でも受け付けられます。
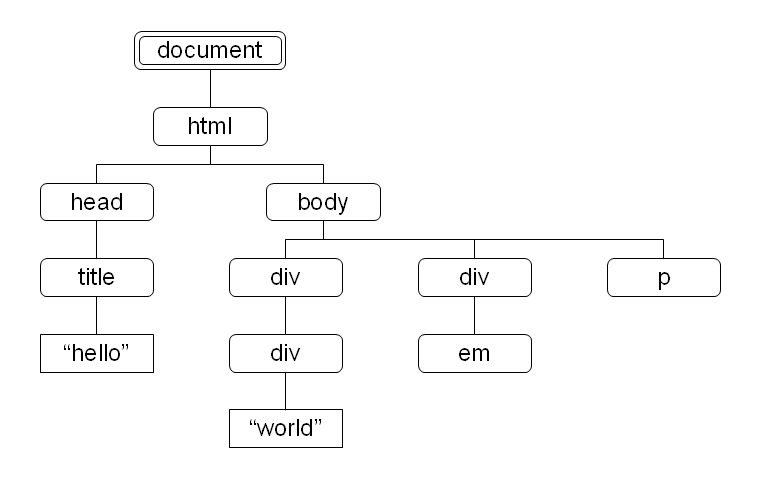 図 1: XPath のデータモデルによる文書木
図 1: XPath のデータモデルによる文書木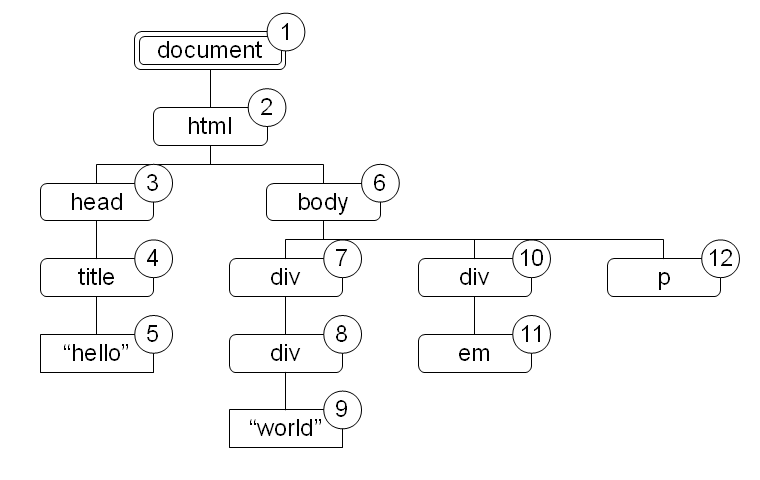 図 2: 各ノードに文書順で振った番号
図 2: 各ノードに文書順で振った番号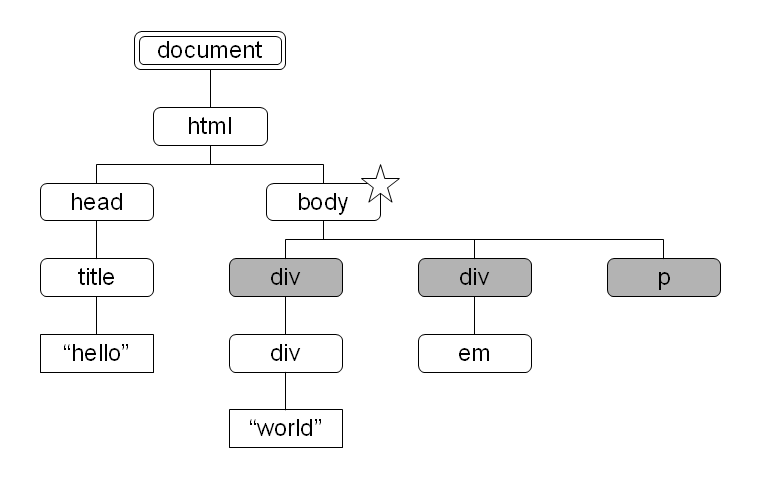 図 3: child 軸により選択されるノード
図 3: child 軸により選択されるノード 図 4: descendant 軸により選択されるノード
図 4: descendant 軸により選択されるノード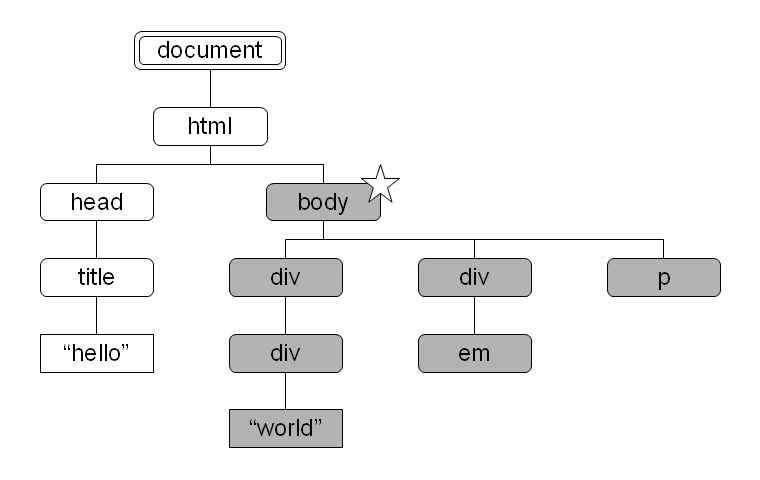 図 5: descendant-or-self 軸により選択されるノード
図 5: descendant-or-self 軸により選択されるノード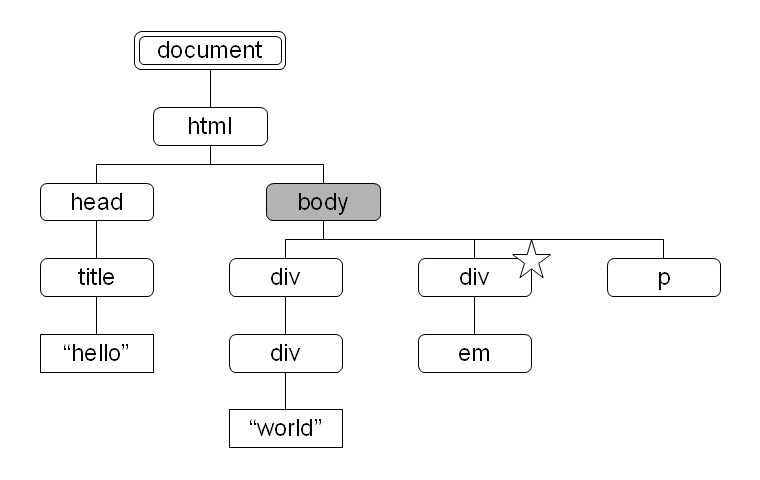 図 6: parent 軸により選択されるノード
図 6: parent 軸により選択されるノード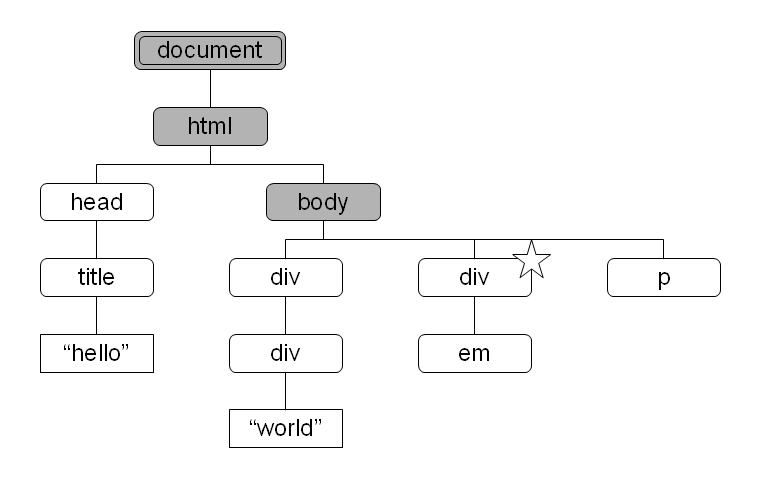 図 7: ancestor 軸により選択されるノード
図 7: ancestor 軸により選択されるノード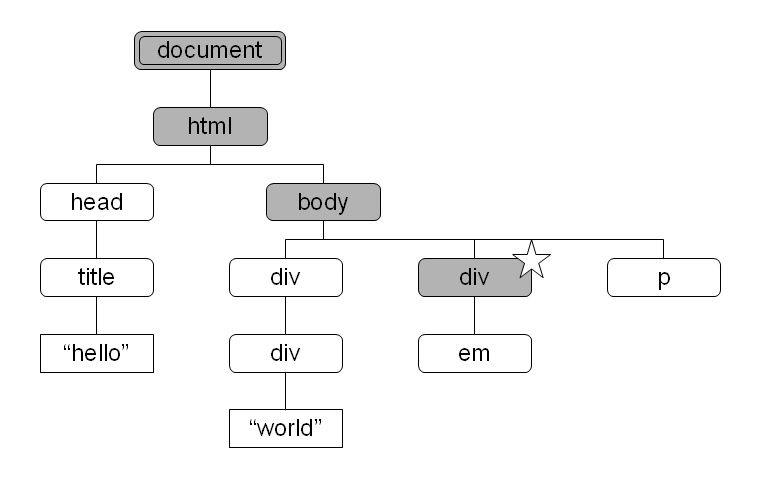 図 8: ancestor-or-self 軸により選択されるノード
図 8: ancestor-or-self 軸により選択されるノード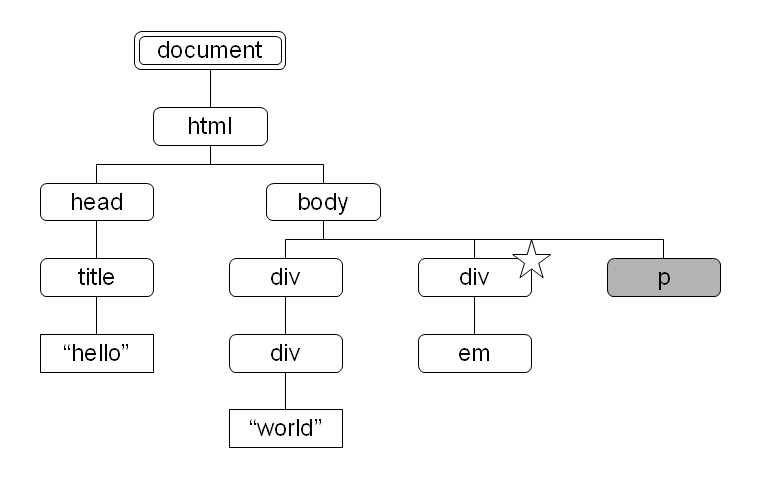 図 9: following-sibling 軸により選択されるノード
図 9: following-sibling 軸により選択されるノード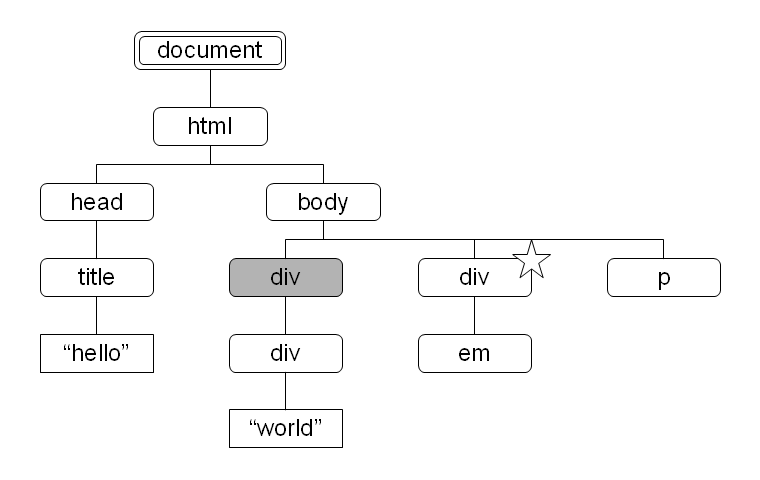 図 10: preceding-sibling 軸により選択されるノード
図 10: preceding-sibling 軸により選択されるノード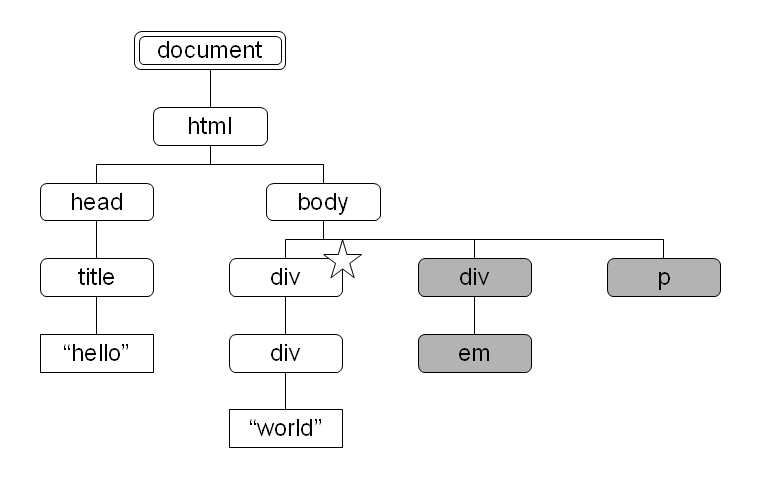 図 11: following 軸により選択されるノード
図 11: following 軸により選択されるノード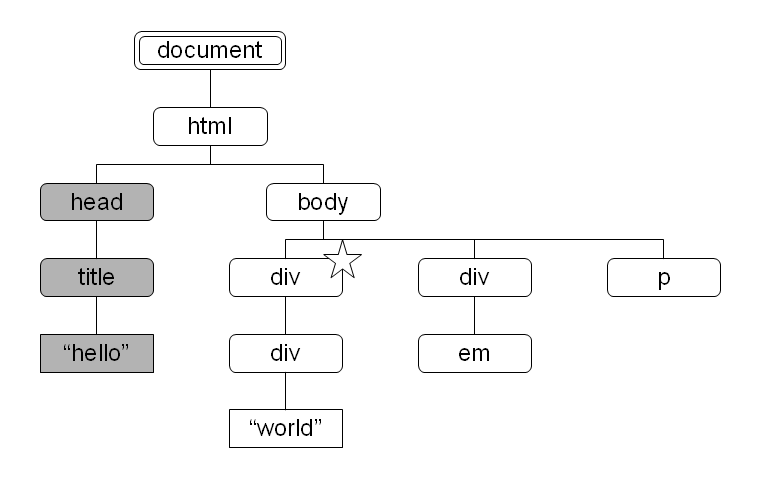 図 12: preceding 軸により選択されるノード
図 12: preceding 軸により選択されるノード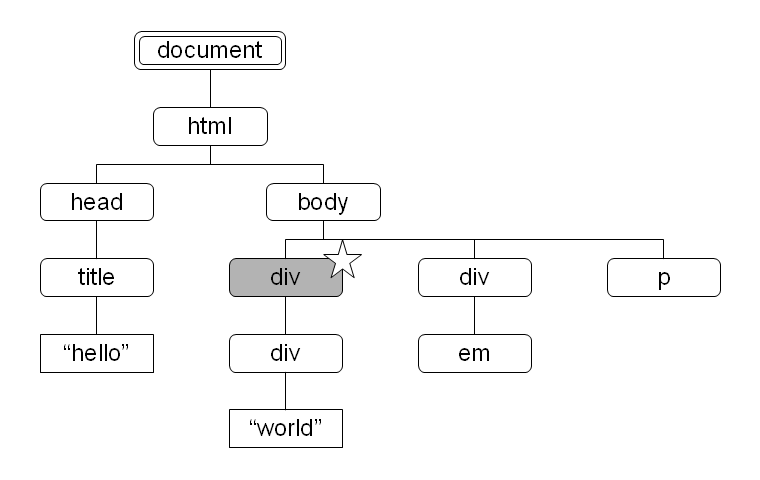 図 13: self 軸により選択されるノード
図 13: self 軸により選択されるノード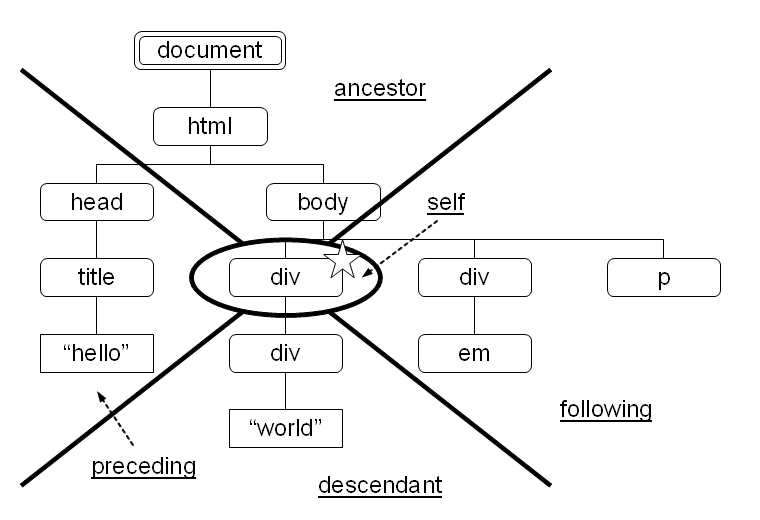 図 14: 各軸による文書木の分割
図 14: 各軸による文書木の分割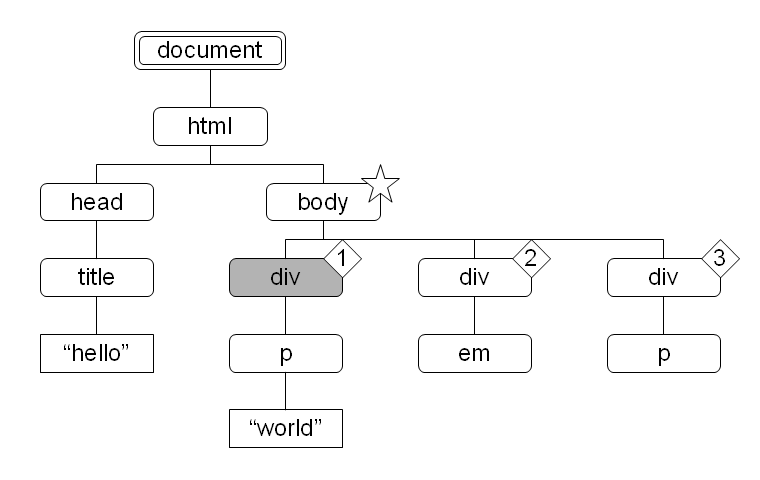 図 15:
図 15: 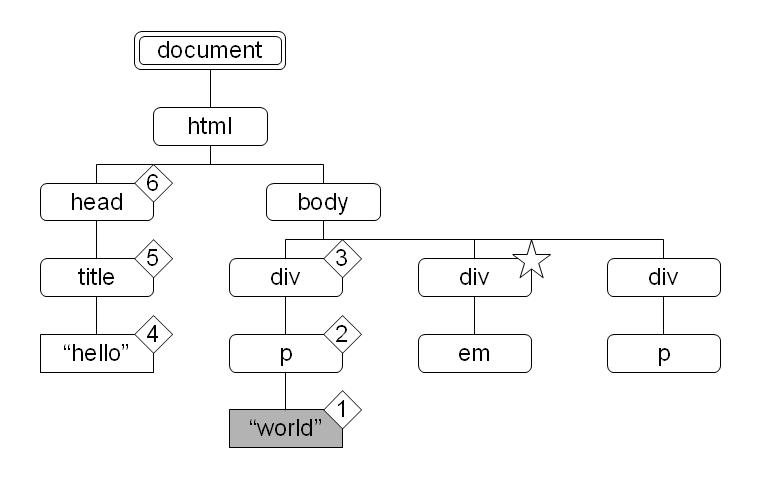 図 16:
図 16: 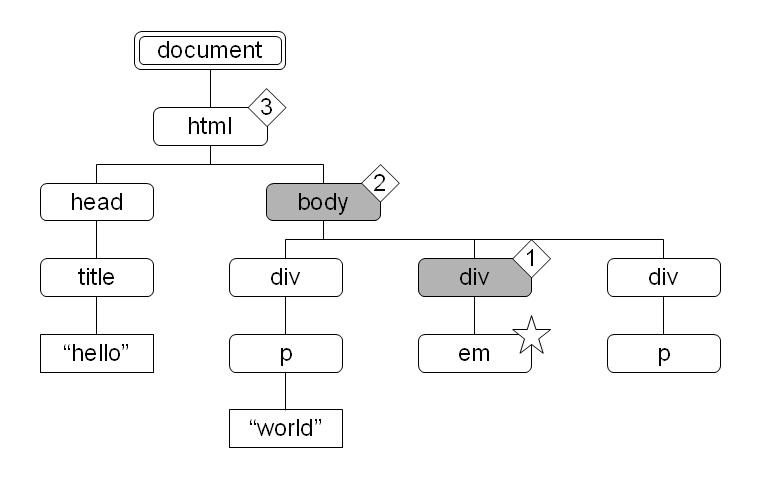 図 17:
図 17: 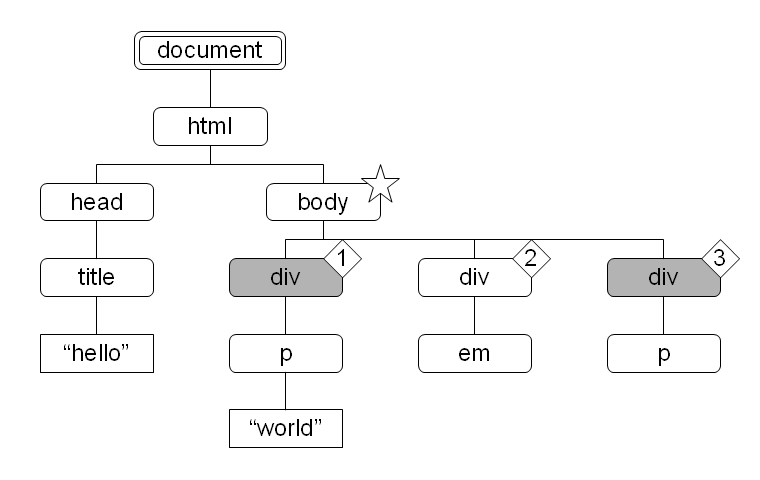 図 18:
図 18: 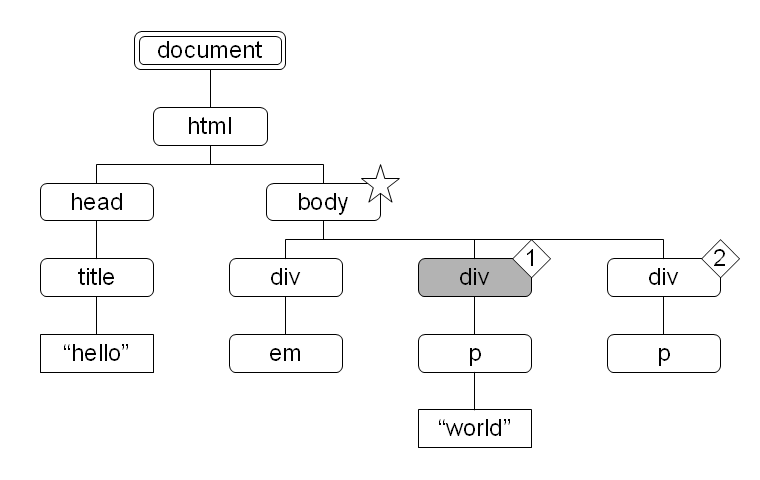 図 19:
図 19: 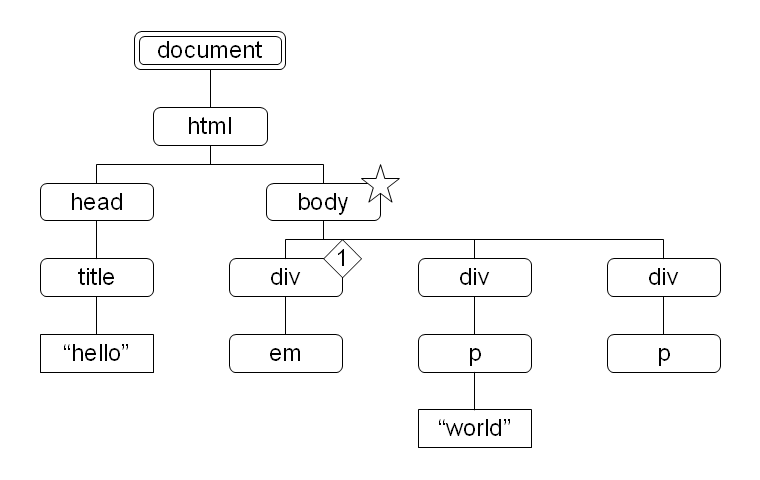 図 20:
図 20: 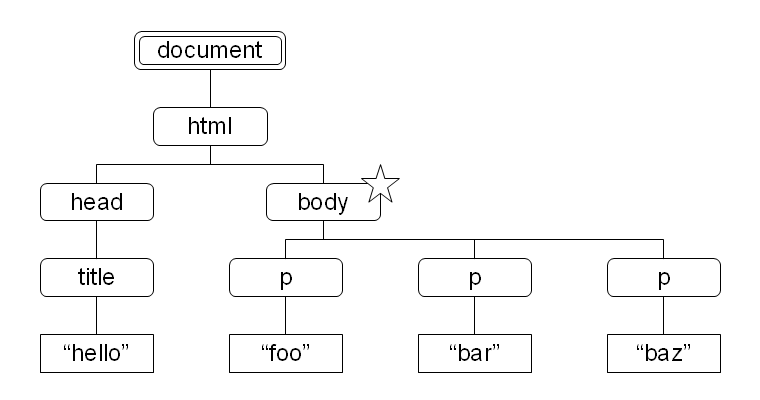 図 21: ノードセットと文字列の比較
図 21: ノードセットと文字列の比較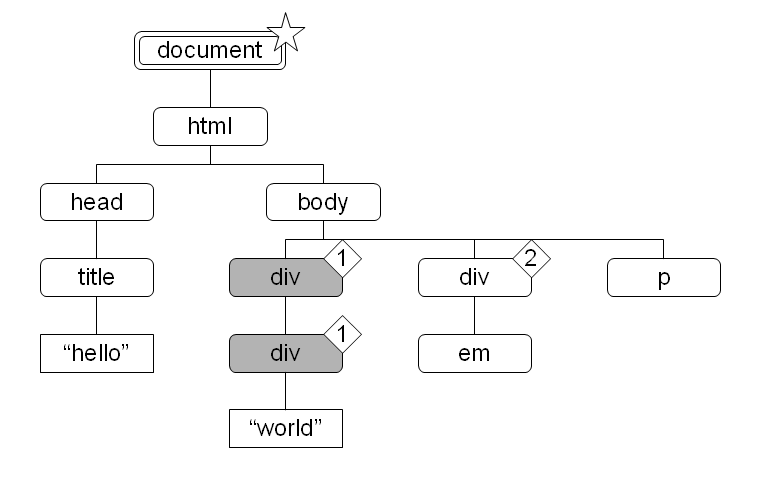 図 22:
図 22: 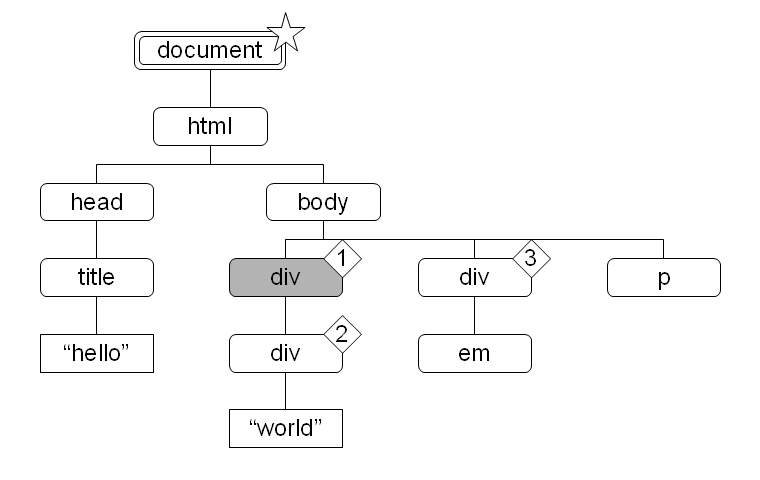 図 23:
図 23: 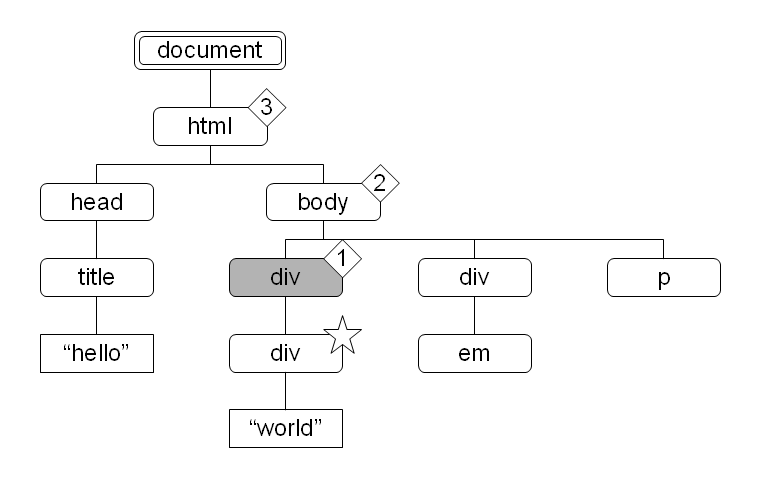 図 24:
図 24: 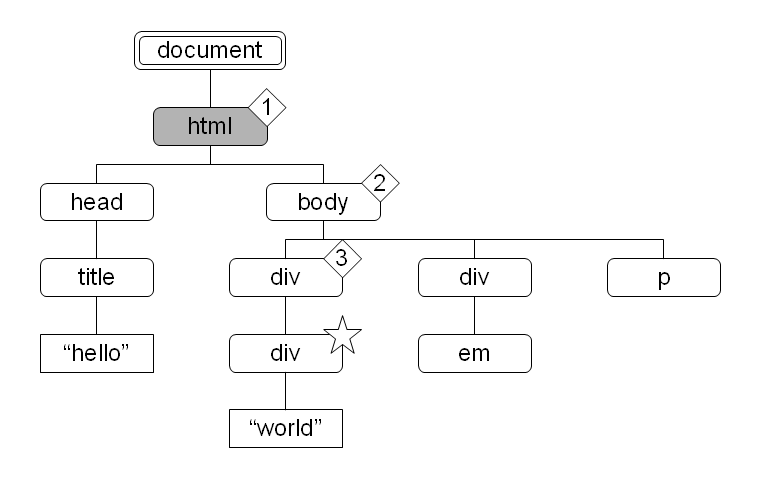 図 25:
図 25: