(1) 推奨動作環境 Windows98、WindowsXP、メモリ255MB以上。 メモリが255MBないと処理速度がプログラムが動いていないと感じるほど遅くなる場合があります。メモリは、マイコンピュータを右クリック⇒「プロパティ」選択⇒「全般」で「255.0MBのRAM」と表示されるので確認できます。ここ数年のパソコンではメモリが255MB以上あるものが多いようですが、それ以前のパソコンですとメモリが128MBの場合もかなりあるようです。 (2) 対応文字コード(スキャナー入力機能) スキャナー入力機能で認識できる文字の範囲の説明です。 JIS第一水準漢字(ギリシャ文字、ロシア文字は除く)までのデータを辞書に登録してあります。また、ユーザー辞書登録機能で例えばレシートに出てきた「苺」なのどのJIS第一水準漢字以外の文字も辞書に登録することが可能です。 (3) 対応画像(スキャナー入力機能) スキャナーの場合、300dpiのモノクロ(白黒)8ビットまたは24ビットのビットマップで読み込んでください。(スキャナーの機種によってはモノクロよりカラーの方が認識率が上がる場合があようです) デジカメの場合は最高画質のjpgで2048×1536(ピクセル)のサイズで1回に1枚のレシートを撮影してください。 (4) 認識率(スキャナー入力機能) 認識率は、[正解した文字数]÷[認識した文字数] で定義します。認識率が何パーセントであるかは画像の質、レシートの行間や文字間の広さ、フォントの種類などによって異なります。また数字、ひらがな、カタカナなどの出現頻度の高い文字をユーザー辞書登録するとそれらの文字の認識率が上がりレシート全体の認識率もかなり上がることになります。このような理由から認識率が何パーセントであるかを決めるのはあまり意味がなく、実際によく使われるお店のレシートなどで試して頂くしかないと思います。ただここではおおまかな目安としてテスト用に使っているレシートで比較的認識しやすいものを例として載せます。また、この例では、半角の数字、カタカナと偏と旁は全部で150文字程度すでにユーザー辞書登録してあります。(これらの文字は配布された「ねこのて」にも収録されています。) 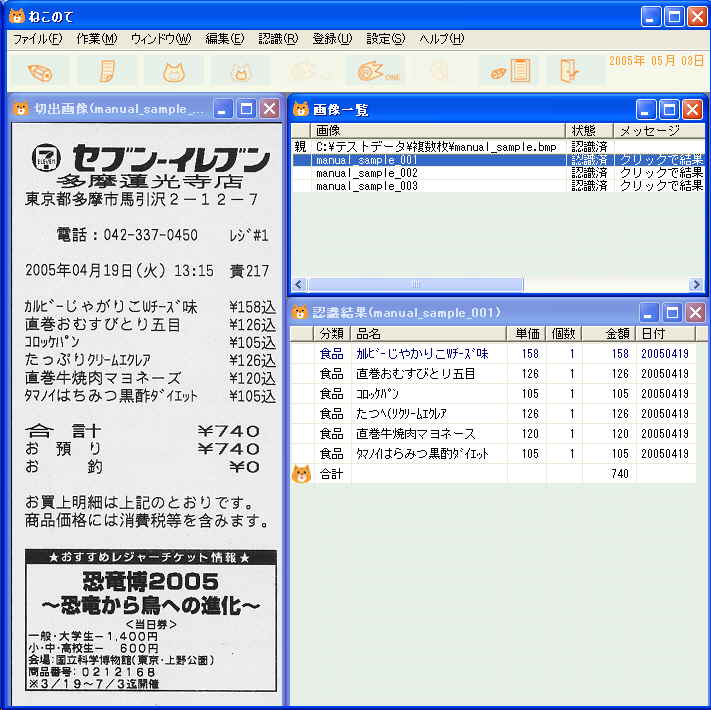 画面イメージはこちらです。 画面イメージはこちらです。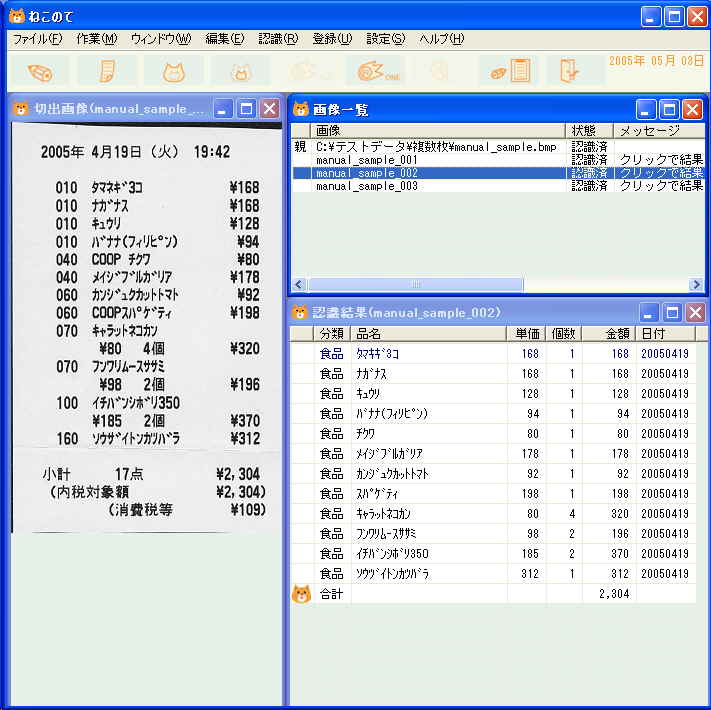 画面イメージはこちらです。 画面イメージはこちらです。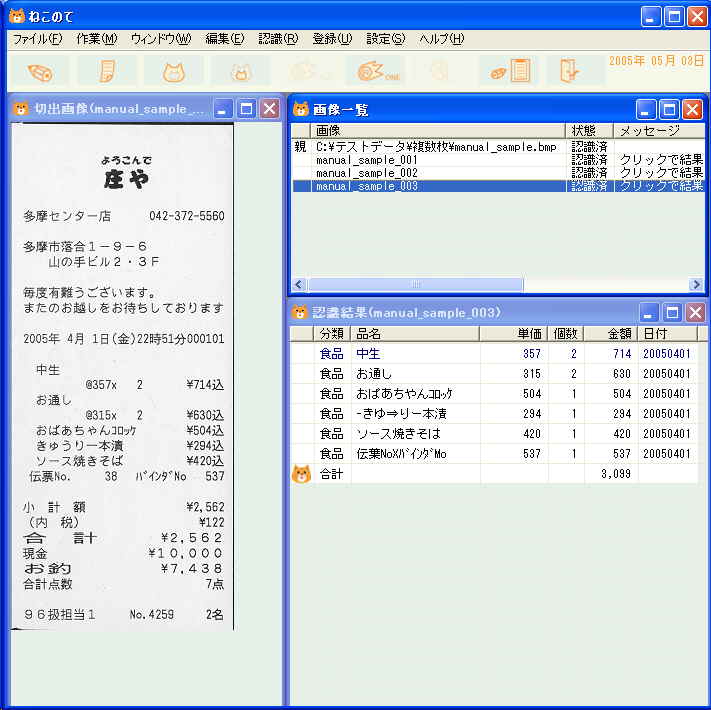 画面イメージはこちらです。 画面イメージはこちらです。 実際に使用した画像はこちらです。(レシート3枚を含みます。約11M) 実際に使用した画像はこちらです。(レシート3枚を含みます。約11M)(5) 苦手なレシート レシートによっては認識率が極端に落ちるものがあります。文字が擦れたレシート、行間や文字間が狭く文字同士がくっ付いているレシート、商品名、個数、単価、金額の表示が複雑なレシートは認識に失敗しやすいです。これらのレシートは、切出された画像を見ながら手で入力するしかありません。
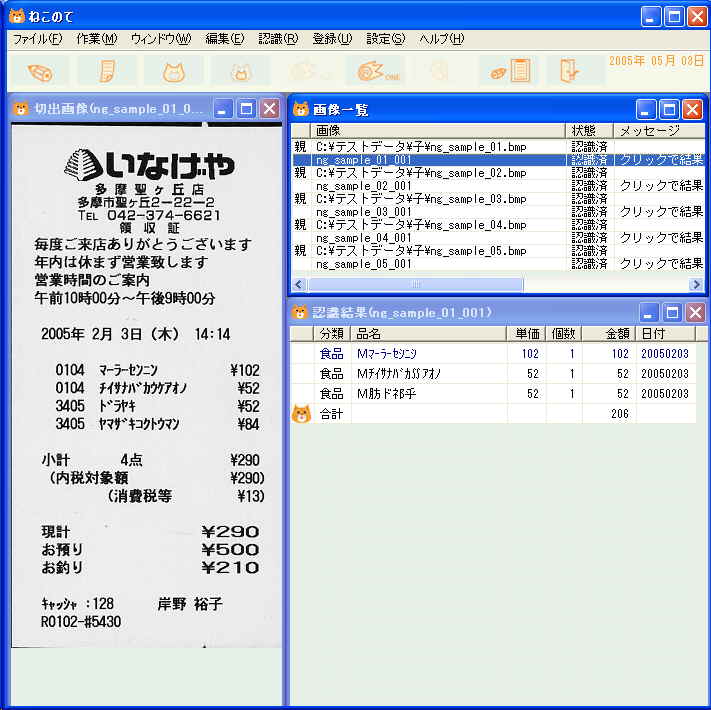 画面イメージはこちらです。 画面イメージはこちらです。 実際に使用した画像はこちらです。(約3M) 実際に使用した画像はこちらです。(約3M)
 画面イメージはこちらです。 画面イメージはこちらです。 実際に使用した画像はこちらです。(約3M) 実際に使用した画像はこちらです。(約3M)
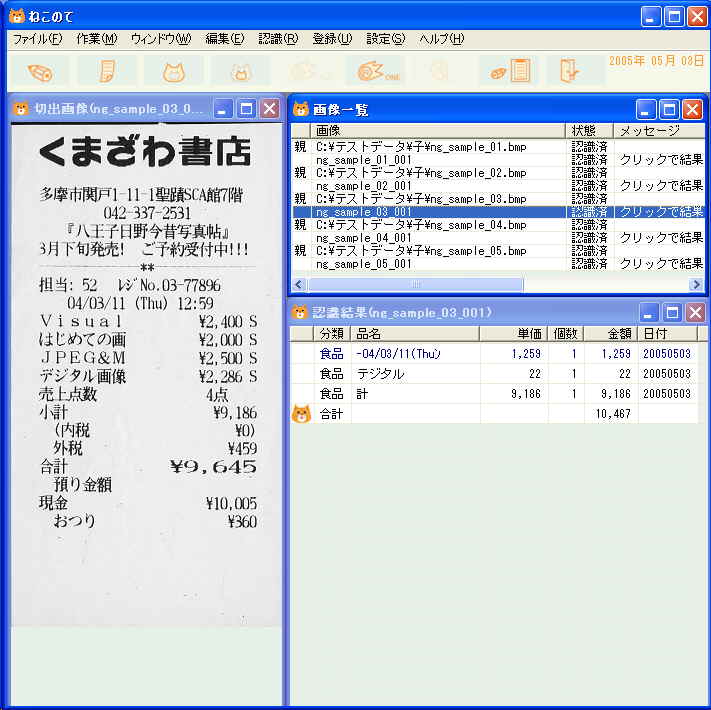 画面イメージはこちらです。 画面イメージはこちらです。 実際に使用した画像はこちらです。(約3M) 実際に使用した画像はこちらです。(約3M)
 画面イメージはこちらです。 画面イメージはこちらです。 実際に使用した画像はこちらです。(約3M) 実際に使用した画像はこちらです。(約3M)
 画面イメージはこちらです。 画面イメージはこちらです。 実際に使用した画像はこちらです。(約3M) 実際に使用した画像はこちらです。(約3M) |
|||||||