同梱しているCSVファイル(vocaloid.csv)を編集して、単語を追加できます。
ここでは、固有名詞などの活用しない語の追加方法を説明します。
活用する語の追加など、細かい規則はMeCab公式の単語の追加方法のページを参照してください。
下の図はcsvファイルをExcelで開いたところです。
26行目の「表層形〜」は、辞書のフォーマットとの対応を見やすくするために書いたものです。実際にはこの行は必要ありません。
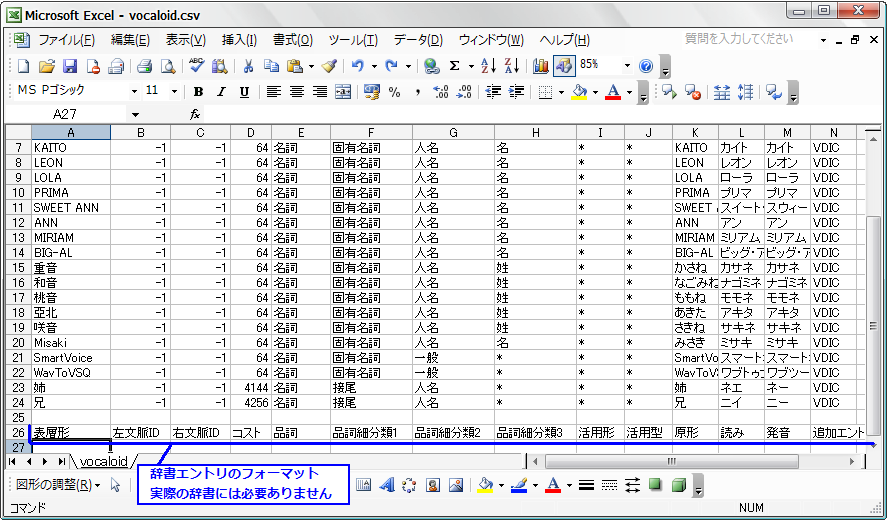
上記画像の「表層形」(A列)が読ませたい単語、「発音」の列(M列)の文字が、ロボ声で発音される読みになります。
発音は基本的に「読み」(L列)と同じでOKですが、ロボ声の発音を読みと変えたい場合(例:スイート→スウィート 等)は、「発音」列を変更すればその通り読んでくれます。
「左文脈ID」「右文脈ID」(B,C列)は、MeCab.Ver.0.97からはWindows版でも"-1"でOKとなりました。-1にすると、辞書をコンパイルするときにMeCabが品詞分類(E〜J列)の内容からIDを自動付与してくれます。
逆にこの品詞分類が間違っているとコンパイル時にエラーになってしまいます。
詳しくは下の品詞分類と文脈IDを参照してください。
「コスト」(D列)は値が小さいほど出現しやすいことを意味しています。
このユーザー辞書の固有名詞はテキトーに64にしていますが、IPA辞書では6000くらいの値のようです。固有名詞は確実に出るように小さい値が良いと思います。
また、23行、24行目の「姉(ネエ)」「兄(ニイ)」のコストが4000強の値になっているのは、文脈によって「アネ」「アニ」という読みにもなるように、IPA辞書の単語コストを参考にして調整したものです。
「追加エントリ」(N列)にある"VDIC"は今のところロボ声の動作とは関係ないので省略してもかまいません。
辞書固有の文字列を指定しておくことで、追加辞書を複数使っている時などに、単語の解析結果がどの辞書を元にしたものか分かるので便利です。
また、追加エントリはカンマ区切りでいくらでも追加できます。メモ書きや発音記号を追加で書いておくことも可能。
MeCabを利用するソフトウェアの中には、この追加エントリを正しく認識せずに、エラーになるものがあります。その場合は、この辞書の追加エントリを消して使用して下さい。
左文脈IDと右文脈IDは、IPA辞書フォルダにある"left-id.def"または"right-id.def"ファイル(以下、文脈IDファイル)に書かれています。辞書コンパイルするときに、MeCabはこれらのファイルから品詞分類に一致する文脈IDを検索しているようです。
単語を追加するときは、ユーザー辞書の品詞分類のところにこの文脈IDファイルに書かれている品詞を書かないといけません。
品詞IDファイルは、通常 "C:\Program Files\MeCab\dic\ipadic"にあります。
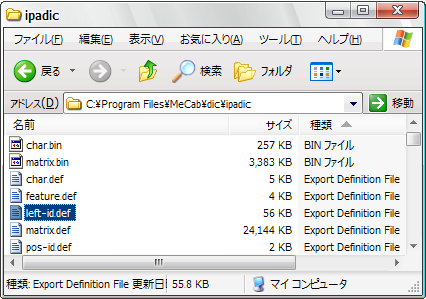
下図は"left-id.def"を開いたところです。この中から、追加したい単語の品詞を選びます。
品詞分類がよく分からない単語でも、とりあえずそれっぽい分類をで選んでおけばOKです。
例えば「初音」という単語を追加したい場合、
ここで使われる意味は人名の苗字っぽいので、1290番の「名詞,固有名詞,人名,姓,*,*,」を選びます。(画像の選択した部分)
これをメモ帳など「テキストファイルとして開いた」辞書ファイルの品詞の所に貼付ければOKです。
Excelで開いている場合は、カンマ区切り毎にコピペしてください・・・。
単語を追加したら、diccompile.batを実行して辞書をコンパイルしてください。
batファイルを実行したフォルダに辞書ファイル(vocaloid.dic)が作成されます。
既に辞書ファイルがあるときは上書きされます。
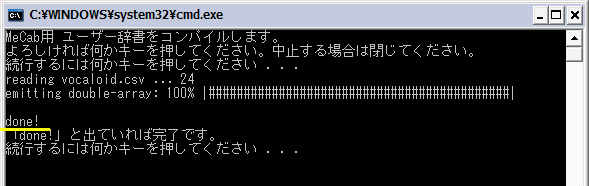
下の図のように「done!」と出ていればコンパイル完了です。(黄色下線部分)
作成された辞書ファイルを、インストール時と同様に上書きコピーしてください。
設定ファイルの変更は必要ありません。
以上で辞書の更新は完了です。